Conversor de Houaiss para Babylon - parte 2
Caloni, 2008-04-08 computer projects blogApós algumas semanas de suspense, chegamos finalmente à nossa segunda e última parte da saga do dicionário Houaiss.
Como devem estar lembrados, a primeira parte se dispôs a desmontar a ofuscação usada nos arquivos do dicionário para permitir nossa posterior análise, com o simples e justo objetivo de importá-lo para o Babylon, cujas funcionalidades de busca são bem superiores.
Feito isso, agora nos resta entender a estrutura interna do Houaiss para montar um conversor que irá ajudar o Babylon Builder a construir nosso Houaiss-Babylon. Simples, não?
A primeira parte de toda análise é a busca por padrões com um pouco de bom senso. O Houaiss armazena suas definições em um conjunto de arquivos de nome deahNNN.dhx (provavelmente deah de Dicionario Eletrônico Antônio Houaiss). Os NNN variam de 001 -- o maior arquivo -- até 065, com algumas poucas lacunas, em um total de 53 arquivos originais.
O nosso rústico importador fez o trabalho de desofuscar todos os 53 arquivos usando a mesma lógica encontrada pelo WinDbg: somar o valor 0x0B para cada byte do arquivo. Dessa forma foram gerados 53 arquivos novos no mesmo diretório, porém com a extensão TXT.
Partindo do bom senso, abriremos o arquivo maior, deah001.txt, e abriremos o próprio dicionário Houaiss, em busca de um padrão que faça sentido. Como poderemos ver na figura abaixo, o padrão inicial não é nem um pouco complicado.
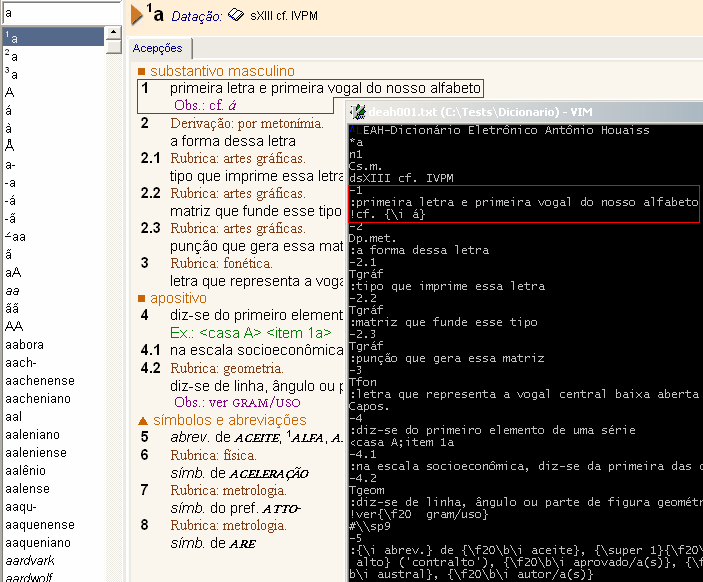
As duas primeiras observações do formato do arquivo nos dizem que (1) o primeiro caractere de cada linha indica o conteúdo dessa linha, e que (2) a formatação dos caracteres é feita dentro de um par de chaves {}.
Dessa forma, podemos começar a construir nosso interpretador de arquivos do Houaiss em seu formato básico.
#include <iostream>
#include <string>
int main()
{
char cmd; // comando da linha atualmente lida
string line; // linha atualmente lida
int count = 0; // contador de palavras
while( getline(cin, line) )
{
cmd = line[0]; // guardamos o comando
line.erase(0, 1); // tiramos o comando da linha
format(line); // formatação da linha (explicações adiante)
switch( cmd ) // que comando é esse?
{
case '*': // verbete
++count;
cout << '\n' << line << '\n';
break;
case ':': // definição
cout << line << "<br>\n";
break;
}
}
return 0;
}
Simples e funcional. Com esse código já é possível extrair o básico que precisamos de um dicionário: os vocábulos e suas definições.
Para conseguir mais, é necessário mais trabalho.
A formatação segue o estilo já identificado, de forma que podemos aos poucos montar um interpretador de formatação para HTML, que é o formato reconhecido pelo Babylon Builder. Podemos seguir o seguinte molde, chamado no exemplo de código anterior:
void format(string& str)
{
string::size_type pos1 = 0;
string::size_type pos2 = 0;
while( (pos1 = str.find('<')) != string::npos )
str.replace(pos1, 1, "<");
while( (pos1 = str.find('>')) != string::npos )
str.replace(pos1, 1, ">");
while( (pos1 = str.find('{')) != string::npos )
{
if( pos1 && str[pos1 - 1] == '\\' ) // caractere de escape
str.replace(pos1 - 1, 2, "{");
else
{
string subStr;
pos2 = str.find('}', pos1);
if( pos2 != string::npos )
subStr = str.substr(pos1 + 1, pos2 - pos1 - 1);
else
subStr = str.substr(pos1 + 1);
istringstream is(subStr);
string fmt;
string word;
is >> fmt;
getline(is, word);
if( word[0] == ' ' )
word.erase(0, 1);
if( fmt.find("\\i") != string::npos )
word = "<i>" + word + "</i>";
if( fmt.find("\\b") != string::npos )
word = "<b>" + word + "</b>";
if( fmt.find("\\f20") != string::npos )
word = "" + word + "";
if( fmt.find("\\super") != string::npos )
word = "" + word + "";
if( pos2 != string::npos )
str.replace(pos1, pos2 - pos1 + 1, word);
else
str.replace(pos1, pos2, word);
}
}
}
Algumas partes ainda estão feias, eu sei. Mas, ei, isso é um código de ráquer, não é mesmo? Além do mais, se isso não é desculpa suficiente, estamos trabalhando em uma versão beta.
A partir dessas duas funções é possível dissecar o primeiro arquivo do dicionário, e assim, construirmos a primeira versão interessante do Houaiss no Babylon.
Como é normal a qualquer dicionário do Babylon, podemos instalá-lo simplesmente clicando duas vezes no arquivo (em uma máquina com Babylon previamente instalado).
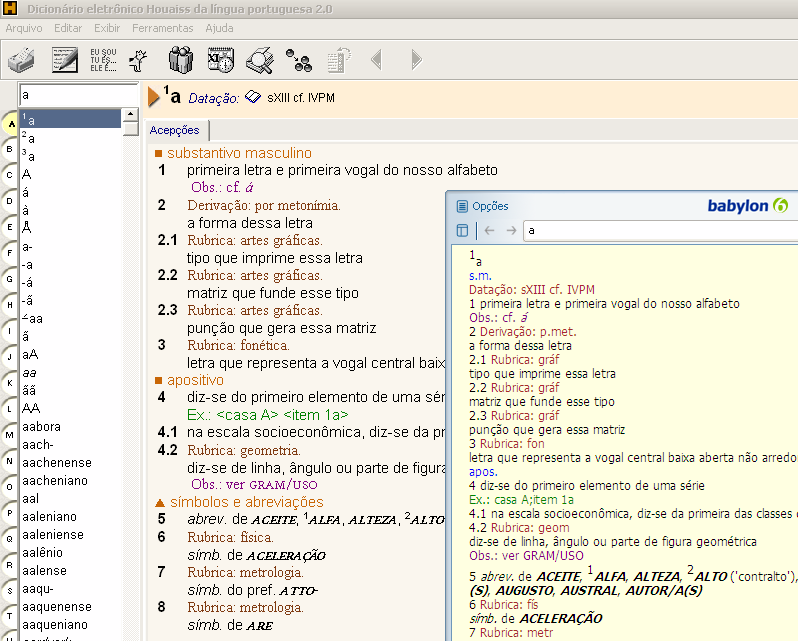
O projeto atual está um tanto capenga, mas já desencripta os arquivos do Houaiss e gera o projeto do Babylon Builder sozinho. Em anexo já está um projeto do Babylon Builder. Basta copiar o arquivo Houaiss.txt para a pasta do projeto e gerar o projeto do Babylon.
// Comments
2009-02-09 Renan de Araujo:
Olá! queria agradecer pelo esforço de criar o programa, mas tenho também uma pergunta:
Eu gostaria saber se é possível fazer esse programa gerar a tabela que vai para o babylon baseada em XML e não HTML. Por que eu gostaria de converter o arquivo final para o dicionário do mac, que tenho um conversor de babylon pro dict.app, mas o problema é o que o software não sabe interpretar HTML, então preciso de uma fonte baseada em XML
Grato pela atenção!
2008-04-21 Angélica:
Eu tenho um dicionário Houaiss 2.0 e o Babylon 7, mas não entendo nada de computação e portanto não entendi o que devo fazer para convertê-lo ao formato Babylon. Baixei a pasta acima [VERSÃO ATUAL] mas não tenho a mínima idéia de como usá-la.
1. Da onde extraio o arquivo Houaiss.txt?
2. Qual é a 'pasta do projeto'?
3. Uma vez localizado o arquivo Houaiss.txt, se eu copiá-lo para a referida pasta, o que devo fazer? Clicar aonde?
2008-04-22 Angélica:
MUITO OBRIGADO pelas dicas. Segui todas (menos a do Administrador, apesar de estar usando Windows Vista). Será que foi este o problema?
É que cheguei até o item 7, mas quando o Babylon builder entrou em ação recebi oma mensagem de erro.
Copiei a janela do erro com Snagit e se houver um modo posso enviá-la. Para tanto precisaria de um e-mail... O meu já está anotado acima.
Mesmo assim, mais uma vez obrigada. VALEU!!!
2008-04-22 Angélica:
Oi novamente,
Tentei mais vezes, agora como administradora mas mesmo assim não deu certo.A mensagem de erro é a seguinte:
Value of '-2' is not valid for 'Value'. 'Value'should be between 'minimum' and 'maximum'. Parameter name: Value
Mas não é só o '-2' que tem problema. Quase todos os valores entre 1 e 18 trazem a mesma mensagem. E não há como ignorá-las, pois a construção do glossário pára em 18%, volta para o começo e pára de novo.
Obrigada pela atenção,
Angélica
2008-04-22 Caloni:
Olá, Angélica.
Por essa eu não esperava. As respostas para suas perguntas são:
1. Não extrai. Ele deve ser gerado automaticamente no diretório de instalação do Houaiss, pasta Dicionario.
2. A "pasta do projeto" é o diretório que você extraiu do linque "versão atual". Isso é, depois de você ter compilado o projeto (que é a geração do executável que faz todo o trabalho).
3. Após gerado o arquivo Houaiss.txt, você deveria copiá-lo para a pasta do projeto.
Bem, aqui vão algumas dicas e passos para fazer a conversão, mesmo sem conhecimentos de programação e informática avançada. Disponibilizei aqui uma versão compilada do projeto. É esse executável que você irá usar para todo o trabalho.
1. Primeiro, certifique-se que instalou o Houaiss com a opção de copiar os arquivos para o disco rígido.
2. Copie o arquivo Houaiss2Babylon.exe para a pasta de instalação do Houaiss e execute. A conversão irá demorar alguns minutos, e durante esse tempo você deve ver uma tela preta sendo exibida. Se você usa Windows Vista, talvez seja necessário executar o programa com direitos de administrador.
3. Quando a tela preta sumir, o programa já deve ter desencriptado o Houaiss, e dentro da pasta Dicionario de instalação existirão alguns arquivos TXT que você pode apagar, e o Houaiss.txt, que você NÃO deve apagar ainda.
4. Para o resto da conversão, você precisa do Babylon Builder. Instale-o antes de continuar.
5. Copie o arquivo de projeto (Houaiss.grp) e o ícone (Houaiss.ico), que estão na pasta de projeto, para a pasta Dicionario onde está o arquvo Houaiss.txt.
6. Dê um duplo clique no arquivo Houaiss.grp. Para que tudo funciona é ESSENCIAL que na mesma pasta estejam os arquivos Houaiss.ico e Houaiss.txt, este gerado nos passos anteriores.
7. Quando a tela do Babylon Builder aparecer, escolha a opção Quick Build. Espere a conversão terminar.
8. Se você chegou até aqui, um arquivo de dicionário Babylon foi gerado. Se não, algum problema ocorreu. Nesse caso, descreva o que aconteceu, por favor.
[]s
2008-04-23 Angélica:
Oi Wanderley,
O Bloco de Notas abriu, mas disse que a operação é inválida:
Start building... Invalid project file name: Houaiss.gpr
Só não sei se abri o prompt da maneira correta. Fui para Iniciar > Procurar, escrevi 'cmd' e selecionei 'cmd.exe' e o prompt se abriu. Depois eu simplesmente colei o comando sugerido acima e dei um 'enter'.
Mais uma vêz, MUITO obrigada!
2008-04-23 Caloni:
Olá, Angélica.
Eu acho que você está com um problema parecido com o meu durante alguns testes iniciais. Tente fazer o seguinte: você já tem o Houaiss.txt e todos os arquivos estão na mesma pasta, certo? Tente abrir um prompt de comando dentro dessa pasta e digite os seguintes comandos:
set path=%path%;%programfiles%\Babylon\Babylon Glossary Builder BuilderWizard /Build Houaiss.gpr
Se dessa forma funcionar, no final da conversão deverá ser aberto um arquivo no Bloco de Notas indicando que está tudo OK.
Caso não dê certo, por favor, me avise, que irei tentar corrigir quando tiver um tempinho, ok?
[]s
2008-04-23 Angélica
DEU CERTO!!!
Agora eu consegui abrir o prompt DENTRO da pasta (usando a função 'Open Command Prompt here' do menu de contexto com a tecla SHIFT), e tudo correu às mil maravilhas.
O dicionário já esta instalado no Babylon e funcionando. Se você fizer novas modificaçôes avise-nos. Marcarei este site e voltarei sempre em busca de modificações.
MUITÍSSIMO OBRIGADA,
Angélica
2008-04-23 Caloni:
Olá, Angélica.
Puxa, fico muito feliz que você tenha conseguido. Sinceramente, não imaginei que alguém fosse realmente usar minha solução. Fico mesmo muito contente.
Quando tiver mais tempo pretendo fazer mais análises do que dá pra melhorar na conversão. Acredito que uma tela descrevendo os passos (que nem o Babylon Builder) deve ajudar bastante os usuários.
[]s
2008-05-18 Ricardo:
Olá, Caloni.
Esbarrei por aqui com seu projeto e achei interessante, compilei com o Visual C++ 2008 Express Edition. Foi criado o arquivo Houaiss2Babylon.exe mais ele não está convertendo os arquivos.
A mensagem do Debug é:
'Houaiss2Babylon.exe': Loaded 'C:\Tests\Houaiss2Babylon\Release\Houaiss2Babylon.exe', Symbols loaded. 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\ntdll.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\kernel32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\user32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\gdi32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\advapi32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\rpcrt4.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\WinSxS\ x86_Microsoft.VC90.CRT_1fc8b3b9a1e18e3b_9.0.21022.8_x-ww_d08d0375\ msvcr90.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\WinSxS\ x86_Microsoft.VC90.CRT_1fc8b3b9a1e18e3b_9.0.21022.8_x-ww_d08d0375\ msvcp90.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\shimeng.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\imm32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\lpk.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\usp10.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\msvcrt.dll' 'Houaiss2Babylon.exe': Unloaded 'C:\WINDOWS\system32\shimeng.dll' The program '[1260] Houaiss2Babylon.exe: Native' has exited with code -1 (0xffffffff).
Minha experiência com C++ é quase zero, sem querer abusar (já abusando) tem alguma dica?
2008-05-19 Caloni:
Olá, Ricardo.
Uma dica rápida: use o linque (2026-03-21 link quebrado) que eu disponibilizei com o projeto compilado e siga as instruções nos comentários anteriores.
Uma dica mais demorada: depure passo-a-passo e me diga em que ponto que o programa está saindo. A partir daí teremos dados mais concretos para dizer o que está acontecendo.
[]s
2008-05-19 Ricardo:
Olá Caloni.
Eu bem que já havia tentado, mais o linque está quebrado.
Quanto à dica mais demorada, o Visual C++ 2008 Express importa o projeto (The solution or project you are openig was created in a previous version of Visual Studio.) e compila de forma aparentemente normal só que o executável quando colocado na pasta de instalação do Houaiss e devidamente acionado não gera arquivo nenhum.
Obrigado pela atenção.
2008-05-23 Major Quaresma:
Muito obrigado a todos,
Não sei NADA de programação. Pra ser mais preciso, comecei - e logo desisti - de um famoso curso da UFMG de programação em C. Meu programa mais complexo pedia que o usuario inserisse um numero e desse enter, ai o meu "programaço" pedia um seguindo numero e quando o usuario apertasse enter o meu "programaço" somava os dois numeros, dividia-os por 2 e mostrava o resultado!!! Uau!!! Que máximo!!! Mas foi útil pois pelo menos eu pude compilar o programinha para extrair os dados do Houaiss... Muita tentativa e erro ate eu entender o que estava fazendo, mas funcionou... Agora vou tentar passar a base de dados para SlovoEd (PalmOS).
2008-05-26 Caloni:
Olá novamente, Ricardo.
Disponibilizei novamente uma versão compilada no mesmo linque (2026-03-21 quebrado) dos comentários. Tente usar esta versão.
[]s
2008-05-26 Caloni:
Olá, Major.
Fico feliz que tenha conseguido compilar e usar meu pequeno e singelo programinha. Você é uma inspiração para que outros tentem mais um pouco.
[]s
2008-07-09 Roberto Bechtlufft:
Estou interessadíssimo nisso, mas tive algum problema. Quando executo o Houaiss2Babylon nada acontece. A tela do cmd só pipoca rapidamente na tela. Quando tento executar pelo cmd, entro o comando e nada. Minha pasta Dicionário tem vários arquivos dhx.
2008-07-10 Caloni:
Olá, Roberto.
Lembre-se que para aplicar a conversão é necessário que você tenha o Houaiss, o Babylon e o Babylon Builder instalados em seus lugares padrões. Caso você tenha, poderia me informar o sistema operacional utilizado e o idioma?
[]s
2008-07-11 Fabricio Morrone:
Caloni,
Tive o mesmo problema do Roberto. Tenho o Houaiss instalado assim como o Babylon e ainda não instalei o Babylon Builder. Uso Windows Vista em português. Não sei o que fazer, pois acho que sei menos de programação que o Major!!!
2008-07-11 Caloni:
Olá, Fabrício.
Não se preocupe. Apenas peço que tenha paciência que em breve irei lançar uma versão mais robusta com geração de log, o que me permitirá descobrir o que está acontecendo nas suas execuções.
No momento, poderia fazer mais um teste? Tente executar o programa dentro de um prompt de comando com direitos administrativos E nível de integridade alto. Você consegue isso clicando com o outro botão do mouse sobre o atalho para o prompt e escolhendo "Executar como Administrador", ou algo do tipo.
Obrigado a todos pelo feedback dos problemas da versão beta.
[]s
2008-07-11 Fabricio Morrone:
Olá Caloni
Executei como vc pediu e nada aconteceu. O meu Houaiss é a versão 1.0.5, de agosto de 2002. Será que é por isso que não dá certo?
2008-07-13 Adrian:
Olá caloni,
Estou interessadíssimo nisso, mas tive algum problema. Quando executo o Houaiss2Babylon na pasta c:\houaiss nada acontece, o mesmo se executo na pasta c:\houaiss\dicionario. A tela do cmd só pipoca rapidamente na tela. Quando tento executar pelo cmd, entro o comando e nada ocorre. Uso o Windows XP sp2, houaisss versao 1.05, instalei o babylon 7 e o babylon builder.
Agradeço pela atenção.
2008-07-14 Caloni:
Olá a todos.
Foi gerada uma nova versão (2026-03-21 link quebrado) com diversas mensagens de erro. Se puderem testar novamente, agradeço muito.
[]s
2008-07-14 Fabricio Morrone:
Oi Caloni
Testei essa nova versão, ela dá várias mensagens de erro mesmo, mas não cria os arquivos txt. As mensagens são para cada arquivo da pasta Dicionario (Erro abrindo arquivo "C:\Arquivo de Programas\Houaiss\Dicionario\deah***.dhx". Erro de sistema numero 3"). Essa mensagem aparece também com a extensão txt.
Por enquanto, obrigado por tentar nos ajudar!!
2008-07-15 Caloni:
Olá, Fabricio.
A mensagem do erro número 3 é "O sistema não pode encontrar o caminho especificado". Você poderia verificar se o caminho que está sendo mostrado na mensagem é exatamente o que existe em sua máquina? Grato.
[]s
2008-12-22 Willians:
Olá Caloni
Será que através do seu método seria possível converter o Houaiss para um arquivo com extensão ".PDB", lido pelo Roadlingua, em versões para palm e Windows mobile?
Parabéns, muito obrigado e um grande abraço.
2008-12-23 Caloni:
Olá, Willians.
Se o formato do Palm for aberto, ou o Roadlingua possuir um conversor de um formato aberto para seu formato, então com certeza! Se você der uma olhada no artigo em que fazemos a engenharia reversa do dicionário vai perceber que seu formato interno é muito simples de interpretar.
[]s
2008-12-23 Willians:
Olá Wanderley
Muito obrigado meu caro, sem querer abusar, mas o algoritmo utilizado na interpretação do Houaiss 2.0 é aplicável ao Houaiss 1.0 (não consigo achar o 2.0 por aqui)?
Mais uma vez, o meu muito obrigado, um feliz natal pra você e um ano novo igualmente agradável.
2008-12-24 Caloni:
Olá, Willians.
Até onde eu sei, iniciei minha análise na versão 1.0, portanto deve funcionar. Ainda está na minha lista de tarefas dar uma olhada em por que o conversor não está funcionando nessa versão, apesar da desencriptação seguir o mesmo princípio.
Igualmente.
[]s
2008-12-25 Willians:
Olá Wanderley
Evoluí um pouco, todavia, surgiu uma caixa de diálogo com a seguinte mensagem: 'Erro abrindo arquivo "C:\Windows\dicionário\deah049.dhx". Erro de sistema número 2.' Sempre que clico no botão "OK" é aberta uma nova caixa de diálogo com texto análogo, só se modificando o número do arquivo, que passa a ser "deah050.dhx", e assim sucessivamente, até o arquivo "deah059.dhx", se não me engano. Acontece que, de fato, ao verificar a pasta "Dicionario", constatei que os arquivos a que me referi acima, não existem. Será que o procedimento de conversão foi bem sucedido e, na verdade, o que ocorreu foi a não previsão, na sua rotina, da inexistência desses arquivos para a versão Houaiss 1.0?
Novamente, muito obrigado e um grande abraço.
Detalhe: Não foi gerado o arquivo "Houaiss.txt"
2008-12-26 Caloni:
Olá, Willians.
Agora que me toquei: você deve estar usando a versão antiga, não?
A versão para usuário (ainda beta) está disponível (2026-03-21 não mais) neste outro artigo.
Boa sorte!
2008-12-26 Willians:
Olá Wanderley
Funcionou! Arrisco-me a afirmar que talvez tenha descoberto o porquê do aplicativo não funcionar no Houaiss 1.0 (por enquanto só posso especular, uma vez que não disponho da versão Houaiss 2.0). Acho que isso ocorre justamente pela ausência dos arquivos que vão do “deah049.dhx” ao “deah059.dhx” na versão Houaiss 1.0 (eles provavelmente devem existir na versão 2.0). Pra tentar “enganar” o teu aplicativo, criei arquivos de texto vazios com o nome e extensão daqueles ausentes e funcionou. Percebi, analisando o algoritmo que você disponibilizou a seguinte linha (o início de um “laço”):
for( int fileIdx = 1; fileIdx ...
Acredito que quando a rotina se depara com a quebra da sequência numérica, ocorra o “bug”.
Enfim, espero não ter falado muita besteira.
Um abraço e muito obrigado!
2008-12-27 Willians:
Olá Caloni
Tenho até vergonha de te aborrecer com isso, mas estava tentando alterar a tua fonte com o propósito de tornar o arquivo de texto "Houaiss.txt" compatível com o programa "awmaker", que converte arquivos de texto para a base de dados de dicionários do "roadlingua", o que faria com que todos nós, além de podermos usar o Houaiss no Babylon, também pudéssemos usá-lo em celulares, smartfones, palms, etc. Todavia, para que isso possa funcionar corretamente, tenho de adequar o arquivo de texto "Houaiss.txt" para o padrão ”.csv”, ou seja, a palavra procurada (ou verbete) deve estar separada da sua respectiva definição por um ";" (ponto-e-vírgula), e toda a definição deve estar em um bloco de texto único, sem os marcadores HTML. Ademais, para poder fazer a quebra interna do texto dever-se-ia usar o delimitador "\n" (sem as aspas) invés do “enter” ou qualquer outro tipo de tabulação. O problema é que não conheço muito da linguagem "C", quase nada, pra ser mais preciso, e sempre que tento fazer esse delimitador ser adicionado no arquivo de texto, o que ocorre, na verdade, e a quebra automática do texto da definição (o que não pode acontecer, sob pena de descaracterizar o padrão .csv), não aparecendo o já referido delimitador no texto.
Será que pode me ajudar mais uma ver amigo.
Grande abraço.
2008-12-29 Willians:
Olá Caloni
Consegui alterar o código-fonte do teu aplicativo e fazer funcionar a base de dados do “Houaiss 1.0” no "Windows Mobile 6", que é o sistema operacional do meu celular (mas é possível fazer o mesmo para o sistema PALM), através do “Roadlingua”, para tanto, além de gerar um arquivo de texto compatível com o "awmaker", tive de dividir os arquivos “.pdb”, gerados por intermédio desse último, em 5 arquivos menores (“Houaiss_A-C.pdb”, “Houaiss_D-G.pdb”, “Houaiss_H-N.pdb”, “Houaiss_O-T.pdb”, “Houaiss_U-Z.pdb”), tive de fazê-lo por que se os mantivesse em único arquivo ele ficaria muito pesado, provocando travamentos no celular (coloquei essa hipótese à prova). Esse artifício atrapalha um pouco o processo de pesquisa, mas não a inviabiliza, pelo contrário, é condição para o seu funcionamento (pelo menos da maneira como vejo).
A propósito, se interessar, mandei cópia das alterações feitas no código-fonte por intermédio da tua página de contato.
Mais uma vez, muito obrigado e um grande abraço!
2008-12-29 Caloni:
Olá, Willians.
Antes de tudo, parabéns pela sua iniciativa e dedicação, mesmo não conhecendo muito da linguagem, de tentar adaptar o programa para seus objetivos. Fico muito feliz que tenha conseguido, e conseguido sozinho, o que prova sua capacidade de resolver problemas aparentemente muito difíceis se tentado sozinho.
Olharei seu código-fonte com calma. Obrigado por compartilhá-lo.
[]s
2008-12-29 Willians:
Oh! Caloni, na verdade sou eu quem deve agradecer. Um grande abraço e um feliz ano novo pra ti.
2009-02-10 Caloni:
Olá, Renan.
Uma vez que conseguimos desencriptar o conteúdo do Houaiss através de engenharia reversa, e seu formato aberto é facilmente interpretável, podemos convertê-lo para qualquer formato, limitado apenas à imaginação =)
Dessa forma, se você for programador, recomendo que dê uma olhada no artigo sobre a engenharia reversa aplicada e criar sua própria solução.
Se você não é, então terá que esperar pelo menos uns dois meses, depois que eu voltar de férias e ter algum tempo para pensar em uma futura nova versão =)
[]s