- About
- Wanderley Caloni
- O bom filho à casa retorna
- A Inteligência do if: Parte 1
- Introdução ao Debugging Tools for Windows (usando o Logger para monitorar APIs)
- Disassembling the array operator
- História do Windows - parte 1.0
- A Inteligência do if: Parte 2
# About
Caloni, 2007-06-14 journal> [up] [copy]Quer entrar em contato? Mande o bom e velho email. Quer um resumo profissional?

Wanderley Caloni é um programador C/C++ especializado em backend para Windows que decidiu ter seu próprio blogue técnico a pedidos insistentes do seu amigo Rodrigo Strauss, que estava blogando já fazia alguns anos no www.1bit.com.br. Busquei mantê-lo atualizado por esses longos anos de programação, depuração e transpiração com minhas peripécias do dia-a-dia. Eventualmente me tornei crítico de cinema e juntei aqui essas duas escovas de dentes, textos técnicos e cinematográficos, o que acabou tornando o saite gigante a ponto de eu precisar trocar meu static site generator duas vezes. Hoje uso AWK. Sim, os clássicos acabam quebrando um galho =).
Overview geral por cima

Colaborador frequente do Grupo C/C++ Brasil, eu e o Strauss nos consideramos fundadores do grupo por organizar e participar do Primeiro Encontro de Programadores e Aficionados da Linguagem C/C++ do Brasil, que ocorreu em São Paulo exatamente no dia dezessete de dezembro de dois mil e cinco, às três horas da tarde, no restaurante Outback do Shopping Eldorado. Desde então o grupo vem realizando encontros mais técnicos no decorrer dos anos, com palestras e debates. A cerveja tradicional se manteve ao final do evento.
Trabalhei por dez anos na área de Segurança da Informação, principalmente em dois sistemas. O primeiro deles, que tenho mais carinho, foi o Sistema de Controle de Acesso a Usuários e Aplicações (aka SCUA), desenvolvido totalmente no Brasil desde a época do MS-DOS. O segundo, mais contemporâneo, desenvolvido pela Open CS, protege os usuários contra ameaças bancárias virtuais, onde meu papel foi fazer análise de trojans e ataques de phishing utilizando engenharia reversa.
Depois desses dez anos migrei para a área financeira e fui trabalhar na EzMarket, uma pequena empresa iniciada pelo meu amigo Anderson Silva (mais tarde ela foi comprada pela UOL). Desenvolvi um sistema de risco que roda (rodava?) em uma das maiores corretoras do país (a Easynvest) e me tornei sócio desenvolvedor de uma empresa especializada nessas soluções, a Intelitrader. Em meio a isso me tornei sócio de outra empresa, a BitForge, pela qual nutro um carinho especial porque ela auxilia empresas e equipes de desenvolvimento em problemas complexos, seja em arquitetura ou a pura escovação de bits. A metodologia da BitForge é simplesmente fazer o serviço e resolver o problema, seja ele qual for, da maneira mais indolor possível para o cliente.
No mundo acadêmico mantenho teias de aranha por muitos anos. Participei de minha primeira faculdade aos dezoito anos, no século passado, na Faculdade de Filosofia, Letras e Ciências Humanas da USP (aka FFLCH). Cursei um ano e meio antes de me descobrir perdidamente apaixonado por computação. Eventualmente me formei em Arquitetura de Redes pelo Instituto Brasileiro de Tecnologia Avançada. Finalizando a seção sobre diplomas e troféus em geral, de 2013 a 2018 fui nomeado MVP (aka Most Valued Professional) pela Microsoft, um prêmio em consideração pelas colaborações à comunidade C/C++.
Entre xadrez e andar de bicicleta, o hobby que levei mais a sério foi mesmo ser cinéfilo inveterado, e com isso escritor em formação. Tendo mantido por quase dez anos um blogue especializado no assunto, o Cine Tênis Verde, desde o finalzinho de 2014 sou colaborador de um site especializado, o CinemAqui, participando de cabines de imprensa e escrevendo críticas sobre cinema, geralmente sobre estreias de filmes fora do circuito hollywoodiano. A pandemia veio a pausar um pouco essa dinâmica, mas me considero extremamente grato pela oportunidade dada pelo Vinicius Carlos Vieira, editor do site.
No detalhe
Caso esteja ainda curioso e tenha chegado até aqui, abaixo temos uma breve e não-exaustiva lista das coisas que eu andei fazendo na minha não tão breve vida de escovação de bits. E espero que essa lista continue crescendo.
Desenvolvi uma solução de cópia de arquivos entre máquinas famigeradamente conhecida como "CopyFile que não copia" usando tecnologia COM e expansão de macros. Foi meu primeiro sistema a ser lançado em produção e me orgulho bastante dele ter sido concebido ainda por um programador de nível Júnior que mal sabia compilar uma DLL.
Mantive um sistema de inventário de hardware que utiliza as tecnologias WMI e SMBIOS, além dele ser também um inventário de software, pois coleta dados pelo registro da máquina.
Criei uma proteção da área de transferência, o Ctrl+C Ctrl+V, além do PrintScreen, através de um hook de janelas e manipulação de mensagens globais do sistema. É muito bacana para proteção de cópias fáceis dos dados de uma empresa, ainda que sempre exista a cópia difícil, pelo cérebro do funcionário, impossível (até o momento) de ser protegida.
Escrevi alertas no log de eventos do sistema usando device drivers. Sim, isso parece trivial, mas nada que você desenvolva usando Microsoft em C ou C++ acaba sendo trivial no final das contas.
Me comuniquei entre o user mode e kernel mode através de chamadas à função Windows DeviceIoControl, o que engloba praticamente toda solução desses dez anos em segurança da informação e envolve níveis diferentes de conhecimento, dependendo do protocolo definido entre esses dois mundos.
Acessei remotamente desktops usando ferramenta similar ao VNC com código-fonte modificado, onde a maior dificuldade é compilar de primeira.
Fiz do zero uma ferramenta de execução remota similar ao PsExec. Em alguns casos até melhor, pois vem com o código-fonte.
Controlei a impressão de documentos através de regular expressions usando uma biblioteca da Boost junto de um hook do shell do sistema.
Gerenciei as diretivas de acesso do sistema durante o logon e o logoff dos usuários. Para isso, mais uma vez, apelei para o registro e os hooks que a vida nos dá.
Migrei entre as bases de dados CTree e SQL usando classes OLEDB. Migrei novamente utilizando camadas de abstração DCOM. Migrei mais uma vez desenvolvendo ferramentas de conversão. Havia algum problema de gerência nesse projeto que nunca conseguiu abandonar a tecnologia antiga.
Autentiquei no Windows usando serviço DCOM e GINA customizada, ou até mesmo a Credential Provider, desenvolvida no Windows Vista para substituir as técnicas anteriores.
Sincronizei remotamente duas bases de dados CTree usando serviço DCOM (olha o projeto de bases de dados CTree aí de novo).
E por falar em CTree, consertei um bug bem sério de starvation de threads no servidor atendendo 80 mil clientes ao bypassar a solução desse componente problemático para acessar diretamente a base de dados principal em SQL Server.
Compilei um CD Linux bootável com scripts bash e ferramentas de criptografia de discos. Tudo em linguagem C.
Também mexi no driver de criptografia de discos rígidos e armazenamento USB, como o uso de pen drives.
Já realizei dezenas de análises de telas azuis ou dumps de memória usando WinDbg, seja em kernel mode ou user mode.
Certa vez fiz um serviço COM de execução de aplicativos na conta de sistema que foi muito útil para vários pontos de um sistema gigante.
Customizei a MBR, ou Master Boot Record, os primeiros bytes que ligam um PC, adaptando de acordo com as características da BIOS, o código que está na placa que liga um PC.
Mantive uma biblioteca de criptografia Blowfish e SHA-1 em C++ e Assembly 16 bits, o que me rendeu uma semana de análise de um bug em modo real e um ótimo artigo aqui no blog. Com isso aprendi a usar um carregador de boot em Assembly 16 bits e depuração usando o simplório debug.com.
Outro sistema que deu certo trabalho foi o driver de auditoria de acesso, que usa memória compartilhada e eventos entre user mode e kernel mode. Mais sessões intermináveis de depuração no WinDbg.
Trabalhei com um sistema que fazia hook de API (mais um hook) em kernel mode para ambas as plataformas Windows, NT e 9X.
Protegi os executáveis através de autenticação em domínio configurado no resource dos arquivos, uma solução muito boa para centralizar instalações em um ambiente.
Mantive DLLs de proteção à navegação em Internet Explorer 6 e 7, e Firefox 1 e 2. Tudo usando injeção de código Assembly 32 bits.
Desenvolvi uma biblioteca de proteção de código, strings na memória e execução monitorada. Isso envolvia desde o alto nível da ferramenta até o uso de interrupções Win32.
Também desenvolvi uma biblioteca de geração de log centralizado, o que parece fácil, mas não quando você precisa controlar todos os processos do sistema através de memória mapeada e eventos globais.
Já mexi com os BHOs, ou Browser Helper Objects, e ActiveX, para Internet Explorer 6 e 7. Para o Mozilla e Firefox usei um plugin XPI.
Já fiz muito gerenciamento de projetos usando Source Safe, Subversion, Mercurial, Bazaar e scripts batch. Atualmente meu maior conhecimento em controle de fonte é usando git na linha de comando.
Já fiz debug de kernel em plataformas NT usando SoftIce e WinDbg. Isso em NT, mas como em 9X não existem essas coisas a solução foi uma mistura entre SoftIce e um depurador obscuro, que quase ninguém deve saber que existe, chamado WDeb98. Rodei esse cara dentro de uma máquina virtual emulada em conjunto com a interpretação das instruções em Assembly.
Como citado na introdução, fiz engenharia reversa de trojans feitos em C++, Visual Basic e Delphi usando WinDbg e IDA, e posso dizer com propriedade que os mais difíceis de entender são os feitos em VB.
Fiz certa vez uma ferramenta de diagnóstico muito simpática que lista arquivos, serviços, drivers, registro, partições, processos, tudo de uma máquina Windows.
Monitorei a execução de jobs em Windows 2000 ou superior para controle de instalação e atualização de produtos.
E por falar em monitoração, também registrei a frequência de uso de aplicações usando hook de janelas, de maneira invasiva e não-invasiva. O que não travasse estava bom.
Como pet project fiz a reversa do dicionário Houaiss e importei para o formato de outro dicionário eletrônico, o Babylon.
Controlei o sistema de build quando não havia muitas soluções open source por aí com Cruise Control .NET, e mantive um servidor de símbolos, talvez um dos únicos na época fora da Microsoft, usando Debugging Tools for Windows.
Documentei projetos através de Doxygen e uma solução wiki chamada Trac. Mantive os sistemas de documentação no ar e ativos enquanto estava no projeto, embora depois essas coisas se perdem e ninguém mais sabe como fazer.
Outro projeto que lembro com carinho, quando atingi a marca de dez mil linhas de código, foram as interfaces de gerenciamento para desktop que desenvolvi usando C++ Builder 5 e 6 e bibliotecas Visual C++. O principal deles, conhecido como Manager, roda até hoje, em um mundo onde tudo está no browser. Já mexi com interfaces de análise também, feitas em Visual C++ com os frameworks MFC, ATL e WTL.
Fiz análise de e-mails usando expressões regulares, dessa vez com a biblioteca da ATL, que é muito curiosa e enxuta, além de bugada. Nessa época também me especializei em análise de logs e edição global de projetos utilizando regular expressions. É impressionante o quanto você consegue economizar de tempo analisando logs e projetos gigantes se conhecer regular expressions.
Como citado na introdução, desenvolvi um sistema de risco para o mercado financeiro, corretoras da bolsa de valores. Rodando em uma das maiores corretoras do país, contém o conjunto mais rebuscado de regras que alguém da área de risco poderia querer, desenvolvido com a ajuda de um especialista na área. Este é outro projeto que me dá orgulho, principalmente pelo sistema que detecta travas de opções.
Escrevi muitos artigos em português no meu blogue técnico, e mais alguns em inglês, aqui e pelo Code Project, que por muitos anos era a comunidade mais ativa de projetos Microsoft.
Suportei uma solução RTOS usando um não-RTOS na camada de aplicação (Windows). Nós desenvolvemos uma ponte de comunicação entre um firmware in house do cliente e o sistema operacional rodando código gerenciado e Web API mantendo uma camada fina em um SDK escrito em C++ que suportava respostas em tempo real independente da resposta do código gerenciado.
Desenvolvi uma API de comunicação com dispositivos HID USB, o que permite navegar pela árvore de dispositivos hoje em dia que estão conectados pelo protocolo. Isso envolve pen drives, celulares, câmeras, qualquer coisa que tenha uma entrada ou saída USB.
Já programei para interfaces mobile do finado Windows Phone e para o Android. Para um usei Visual Studio e para o outro Android Studio. É impressionante como ainda são pesadas essas interfaces de desenvolvimento para mobile.
Mantive por um tempo as soluções de baixo nível da Intelitrader, principalmente as que envolvem market data, pois o fluxo de dados nesses sistemas é absurdamente alto em tempos de crise. Ou seja, atualmente, todo o tempo. Todo o projeto era um mix de sockets C, callbacks C++ e Boost.Asio em cima de um protocolo multicast. Além disso, junto com minha equipe estendemos a biblioteca nativa em C para uso em Java e Golang.
Também na Intelitrader a equipe melhorou o roteamento de ordens no MetaTrader mantendo uma worker thread secundária para persistência de ordens na base de dados.
Nos últimos anos voltei para a área de segurança, onde na Venn estou me divertindo fazendo engenharia reversa e mantendo um sistema de sandboxing que permite isolamento completo dos aplicativos de trabalho e lazer.
English (for resumes)
Developed a solution for copying files between machines using COM technology and macro expansion.
Maintained a hardware inventory system using WMI and SMBIOS technologies.
Created a clipboard protection (Ctrl+C Ctrl+V) using windows hook and handling global system messages.
Wrote alerts to the system event log using device drivers.
Communicated between user mode and kernel mode through calls to the Windows DeviceIoControl function.
Remotely accessed desktops using a tool similar to VNC with modified source code.
Made a remote execution tool similar to PsExec from scratch.
Controlled the printing of documents through regular expressions using Boost and a system shell hook.
Managed system access policies during user logon and logoff using hooks.
Migrated between CTree and SQL databases using OLEDB classes.
Authenticated on Windows using DCOM service and custom GINA and Credential Provider.
Remotely synchronized two CTree databases using DCOM service.
Fixed a serious bug with thread starvation in server attending to 80k clients by bypassing CTree Database solution to direct access main database in SQL Server.
Compiled a bootable Linux CD with bash scripts and disk encryption tools.
Fiddled with the driver for encryption of hard disks and USB storage such as using pen drives.
Performed dozens of analysis of blue screens or memory dumps using WinDbg (kernel and userland).
Made a COM service to run applications under the system account.
Customized the Master Boot Record adapting according to the characteristics of the BIOS.
Maintained a Blowfish and SHA-1 cryptography library in C++ and 16-bit Assembly.
Worked with a system that hooked an API in kernel mode for WinNT and 9X platforms.
Protected the executables through authentication in the Server Domain.
Maintained browser protection DLLs in Internet Explorer 6 and 7, and Firefox 1 and 2.
Developed a code protection library, strings in memory and monitored execution.
Developed a centralized logging library for all system processes using mapped memory and global events.
Maintaned Browser Helper Objects and ActiveX.
Done a lot of project management using Source Safe, Subversion, Mercurial, Bazaar, Git and batch scripts.
Done kernel debugging on NT platforms using SoftIce and Windbg.
Reverse engineered trojans made in C++, Visual Basic and Delphi using WinDbg and IDA.
Made a diagnostics tool that lists files, services, drivers, registry, partitions and processes on a Windows machine.
Monitored the execution of jobs in Windows 2000 or higher to control the installation and updating of products.
Recorded the frequency of use of applications using a window hook, both invasively and non-invasively.
As a pet project reversed the Houaiss dictionary and imported it into the format of another dictionary, Babylon.
Controlled the build system when there weren't many open source solutions out there with Cruise Control .NET.
Documented projects through Doxygen and a wiki solution called Trac.
Developed from scratch a desktop management interfaces using C++ Builder 5 and 6 and Visual C++ libraries.
Analyzed emails using regular expressions with the ATL library.
Developed a risk system for the financial market, stock exchange brokers in C++ and Poco Libraries.
Wrote many articles in Portuguese on my technical blog, and a few more in English for the Code Project.
Developed a communication API with USB HID devices, which allows to browse through the connected devices.
Developed and maintained a new system to run in ATMs with a low level protocol using SSL-based protocol written in C++ (Boost.Asio) to allow packet exchange and support screen share even in adverse network bandwidth scenarios, by example, in the middle of Amazonian Forest.
Programmed for mobile interfaces of the late Windows Phone and for Android.
Supported a RTOS solution using a non RTOS in the application layer (Windows) developing and sustainning real time communication between a in house firmware and the Operating System running managed code and Web API by keeping a thin communication layer in a SDK written in C++ that supported real time response independent from the managed code response.
Kept Intelitrader's low-level solutions, such as market data and algo trading. A mix of C sockets, C++ callbacks and Boost.Asio supporting the multicast protocol. Kept high performance market data traffic, even with low computational resources. Interface from native C library to Java an Golang.
Improved order routing performance in MetaTrader keeping a secondary worker thread to persist orders in the database.
In the last years I'm back to security, where at Venn I'm having fun doing reversing and keeping a sandboxing system that isolates work and leisure apps.
"Não basta saber: temos que aplicar. Não basta querer: temos que fazer." Goethe
# Wanderley Caloni
Caloni, 2007-06-14 [up] [copy]Location: São Paulo, Brazil
Email: wanderleycaloni@gmail.com
Stack: C/C++ (26 yrs), Windows (26 yrs), Debugging (23 yrs), Reverse Engineering (15 yrs), Tech/Art Writing and Knowledge Sharing (15 yrs), Linux (10 yrs).
Languages: Python, C#, Assembly, PHP, Java, Golang, Pascal.
Tools: Visual Studio, WinDbg, Git , SSH+Vim.
Work
Sr. Developer at BitForge (2015-current)
- ATM. The old solution was slow and demanded frequent physical support to the ATMs. As the main target of the project was security and resilience, I developed and maintained a new system with a low level protocol using SSL-based protocol written in C++ (Boost.Asio) to allow packet exchange and support screen share even in adverse network bandwidth scenarios, by example, in the middle of Amazonian Forest. The outcome was the exchange of the 20 years old solution, what decreased the frequency of physical support at the ATMs (20k+).
- Firmware. The client needed to support a RTOS solution using a non RTOS in the application layer (Windows). I developed and sustained real time communication between a in house firmware and the Operating System running managed code and Web API by keeping a thin communication layer in a SDK written in C++ that supported real time response independent from the managed code response. The solution was sold and delivered for the final client.
Tech Lead at Intelitrader (2019-2023)
- InteliMarket. The main goal was to keep high performance market data traffic, even with low computational resources. I kept the system running in a uptime at 99% and up to date to B3 UMDF protocol last spec. The bug response time daily was about 5 minutes because I organize a time schedule in the team, including backups, and a monitoring system that alerted the team every time an occurrence could be happening, before the final customer even noticed. The outcome was that the reliability of the solution increased and InteliMarket doubled the number of clients subscribing to the solution. I also reduced subscription delays in 50% by removing a core but unnecessary event queue. The entire solution was a mix of C sockets, C++ callbacks and Boost.Asio supporting the multicast protocol.
- MetaTrader. Improved order routing performance by 200%+ by keeping a secondary worker thread to persist orders in the database, becoming success case in the local market, being recomended by MetaQuotes in the midia to its Brazilian clients. Even without a reliable test environment the solution was proved resilient by writing a massive quantity of unit tests to cover all the cases where the final customer reported a behavior error. With that system the bug occurrences in production fell from 6 to only 1 per year. The entire system was developed in C++ with Boost.
Risk Developer at EzMarket (2012-2015)
- EMS. As a experienced trader I was selected to develop the entire Risk System for the order routing system by transforming the client mathematics formulae to high performance and reliable solution in C++ to manage the financial risk of the entire broker with 20k+ active accounts by using POCO Libraries. I also improved the channels internal communication system to be completely configured via XML with routing rules defined by message type, independent from any individual component. The outcome was the exchange of the old solution, what increased total trades and broker total revenue.
Sr. Developer at SCUA (2008-2012)
- Disk Cryptography. The main goal was to protect data from users and companies using low level cryptography in Hard Drive and Pen Drives (USB). This was a tricky project because not always the cryptography worked on every hardware. I had a small team of 3 people and a lot of machines using our product. Sometimes the system boot crashed and I had to analyze the MBR information and to debug the boot process in real mode (8086 assembly) to save the information for the users. The outcome was that this was one of the best selling products from SCUA because big companies loved the idea of a customizable cryptography solution free from hackers of Microsoft trying to break and with a team ready to fix any problems. For this solution it was used Assembly, WDK, Lilo source code and Linux for the bootable CD of troubleshooting.
- Application and User Control System (SCUA). Updated the Windows XP solution to support Vista+. In order to do this I needed to adapt the current custom GINA (Graphical Identification and Authentication) to Credential Provider, allowing other identification methods such as biometric systems to login on Windows. The solution was developed using C++ and native API. The outcome of this project was that old customers were able to update their OSes to Windows Vista, 7 and newer versions without losing the control provided by the SCUA solution. Among technologies used are WinAPI, Windows Services and Device Drivers (WDK). I also fixed a serious bug with thread starvation in server attending to 80k clients by bypassing CTree Database solution to direct access main database in SQL Server.
Security Specialist at OpenCS (2005-2008)
- Sniper. The main goal of this project was to protect users from system vulnerabilities when accessing online banking on the computer. Brazilian banking system was a target from severals online attacks at that time, and Sniper solution was based on API hook by device drivers, creating a shield to protect users from malicious software running on the computer that detect the bank site access and try to capture the user information to login on the bank. After the first release I was responsible for develop a protection for Sniper itself, because hackers were trying to reverse engineer our solution, so I developed techniques for anti debugging and string obfuscation. A global log system was created to allow us to analyze some bugs happening only in specific sets of hardware and software. The number of computers where Sniper was installed was counted in hundreds of thousands and some issues were happening in all kinds of sets, like a user running Solitaire in a Windows 98. As an outcome, this product was sold to a big bank from the South of Brazil and was the main cause of the company growing in the first two to three years after the first release. Among the technologies used are Assembly, WDK and Virtual Machines such as VMWare, Parallels, Virtual Box and QEMU. I had also to reverse engineered several trojans on a daily basis to discover the API used in the threats in order to develop a new version with the new protection.
Security Developer at SCUA (2001-2005)
- Application and User Control System (SCUA). The main goal of this project is to protect the computer from viruses and other threats based on access rules on paths and Windows policies. The access rules are kept in a distributed CTree database and the product needed a Graphical Interface to configure those rules. I developed the desktop management application in C++ Builder by adapting MSVC libraries. It was my first big project with 10k+ lines of code. The outcome was that it became the oficial app to configure rules to SCUA, being used even today for all customers, 20 years after being developed.
# O bom filho à casa retorna
Caloni, 2007-06-15 <journal> [up] [copy]Depois de seis meses blogueando em um novo domínio, que seria totalmente focado em C++, descobri que não consigo viver escrevendo apenas sobre a linguagem em que programo. Não é que falte assunto. Simplesmente meu dia-a-dia nunca se resume apenas em regras de sintaxe e erros de compilação.
Por outro lado, aprendi muitas coisas novas desde o começo desse ano. Decorei novos comandos do Windbg, novos atalhos no Google Reader. E fiz outras tantas coisas novas também. Projetei um sistema de comunicação entre processos -- versão alfa, tudo bem, mas projetei. Decifrei o formato do banco de dados do dicionário Houaiss para poder usá-lo no Babylon. E por aí vai.
E por falar em escovação de bits, apresentei mais duas vezes aquela palestra sobre engenharia reversa. O curioso é que, em vez de eu aumentar o conteúdo da transparência, eu diminuo. Talvez isso seja uma ingênua tentativa de tornar a apresentação menos enfadonha e mais interessante para o público em geral, por mais leigos que eles sejam. Nessa última versão (3.0) cheguei a explicar o processo de análise dos cavalos de tróia dentro da Open Security, desde a descoberta da ameaça até a implementação da cura.
Depois de todas essas aventuras percebi que meus conhecimentos em C++ não aumentaram nem um pouco. Talvez um pouco, mas culpa da nossa fascinante lista de discussão sobre C++ aqui no Brasil, que esmera nos detalhes. Porém, por mim mesmo não aprendi nenhuma biblioteca nova do Boost. Não desenvolvi nenhuma artimanha nova usando templates e herança múltipla (obs: com uma perna só). Enfim, não aprendi nem fiz nada relevante com o tema C++ nos últimos seis meses.
E isso me leva de volta para cá, o cantinho de onde nunca deveria ter saído. Mas aprendi a lição. Estarei por aqui de agora em diante, pronto para escrever sobre o que fizer parte dos meus dias de programador. Não irei cair novamente nas ilusões de um pensamento purista e inadequado à minha realidade de escovador de bits "estamos aí para o que der e vier". Afinal de contas, a gente depura mas se diverte.
# A Inteligência do if: Parte 1
Caloni, 2007-06-18 computer> programming> philosophy> assembly> closed> [up] [copy]No nível mais baixo, podemos dizer que as instruções de um computador se baseiam simplesmente em cálculos matemáticos e manipulação de memória. E entre os tipos de manipulação existe aquela que muda o endereço da próxima instrução que será executada. A essa manipulação damos o nome de salto.
O salto simples e direto permite a organização do código em subrotinas. Subrotinas permitem o reaproveitamento de código com parâmetros de entrada distintos, o que economiza memória, mas computacionalmente é "inútil", já que pode ser implementado simplesmente pela repetição das mesmas subrotinas. O que eu quero dizer é que, do ponto de vista da execução, a mesma seqüência de instruções será executada. Pense no fluxo de execução de uma rotina que chama várias vezes a mesma subrotina:
sub:
code
ret
routine:
code
call sub
code
call sub
code
call sub
Ela é, na prática, equivalente a uma rotina que contém várias cópias da subrotina na memória, uma seguida da outra.
routine:
code
sub:
code
code
sub:
code
code
sub:
code
A grande sacada computacional não são subrotinas. O real motivo pelo qual hoje os computadores são tão úteis para os seres humanos é a invenção de um conceito chamado salto condicional. Ou seja, não é um salto certo, mas um salto que será executado caso a condição sob a qual ele está subordinado for verdadeira:
code
if cond:
call sub
code
if cond:
call sub
code
if cond:
call sub
code
Os saltos condicionais, vulgarmente conhecidos como if, permitiram às linguagens de programação possuírem construções de execução mais sofisticadas: laços, iterações e seleção de caso. Claro que no fundo todas essas construções não passam de um conjunto formado por saltos condicionais e incondicionais. Peguemos o while e seu bloco, por exemplo. A construção em uma linguagem de programação possui uma condicional seguido de um bloco de código que se repete enquanto a condicional for verdadeira:
while cond:
code
Enquanto para o programador dessa fictícia linguagem existe um controle de execução no início que determina quando o código deixará de ser executado repetidamente, para o compilador o while não passa de um salto no final do bloco para o começo de um if.
label:
if cond:
code
jump label
O for, por outro lado, possui tradicionalmente em seu início três operações: inicialização, condição e incremento. O código começa executando a inicialização e verifica a condição uma primeira vez. Após executado o bloco de código condicionado ao for, o incremento será executado, e mais uma vez a condição verificada. Caso a condição seja verdadeira novamente o bloco de código volta a executar, para no final executar o incremento e verificar a condição, e assim por diante.
for: i = 0; i < 10; i++
code
Do ponto de vista do compilador, que irá transformar esta lógica em código de máquina, o for não passa de um contador que é incrementado a cada iteração com um salto incondiconal no final do bloco de código executado.
i = 0
label:
if i < 10:
code
i++
jump label
O switch-case, ou seleção, filtra um determinado valor em comparações de igualdade, a condição, em série. Quando é encontrada alguma igualdade verdadeira o código atrelado é executado e o código imediatamente seguinte ao switch é executado. Opcionalmente o bloco inteiro após uma seleção é ignorado.
switch i:
case 0:
code
case 1:
code
case 2:
code
default:
code
Essa lógica embutida nas linguagens de programação são convertidas pelo compilador em vários ifs seguidos e unidos por um else, o que torna a comparação exclusiva. No final de cada bloco de código existe um salto incondicional para o final da construção.
if i = 0:
code
jump label
elif i = 1:
code
jump label
elif i = 2:
code
jump label
else:
code
label:
Neste artigo vimos como todas as construções de uma linguagem de programação, independente do seu nível, podem ser convertidas em um conjunto de saltos, condicionais e incondicionais. Em um próximo artigo veremos como o salto condicional verdadeiramente funciona, e como pode ser implementado usando apenas operações matemáticas. Afinal, matemática básica é o bloco lógico mais básico que temos em um computador. Qualquer computador.
# Introdução ao Debugging Tools for Windows (usando o Logger para monitorar APIs)
Caloni, 2007-06-20 <computer> debugging> windbg> [up] [copy]2025-10-05: Hoje o Logger está desatualizado e não recomendo mais seu uso. Há ferramentas melhores, como API Monitor, além de ser possível você mesmo desenvolver com a lib Detours.
O WinDbg é uma ferramenta obrigatória em uma das minhas mais divertidas tarefas aqui na Open: engenharia reversa de cavalos de tróia. Não tenho o código-fonte desses programas, não posso executá-los em minha própria máquina e não consigo fazer tudo que preciso usando apenas o depurador integrado do Visual Studio (como remontar o assembly do programa, por exemplo). Tudo isso faz do WinDbg a alternativa perfeita (senão uma das únicas). É um depurador que permite ser usado tanto através de janelas quanto através de comandos, o que permite um aprendizado em doses homeopáticas: comece com as janelas e aos poucos ganhe o controle total. Conseqüentemente cada dia aprendo um comando novo ou um novo uso para um comando que já conheço.
Abaixo um esboço de como o WinDbg se parece, com suas principais janelas. A de comandos é a da direita.
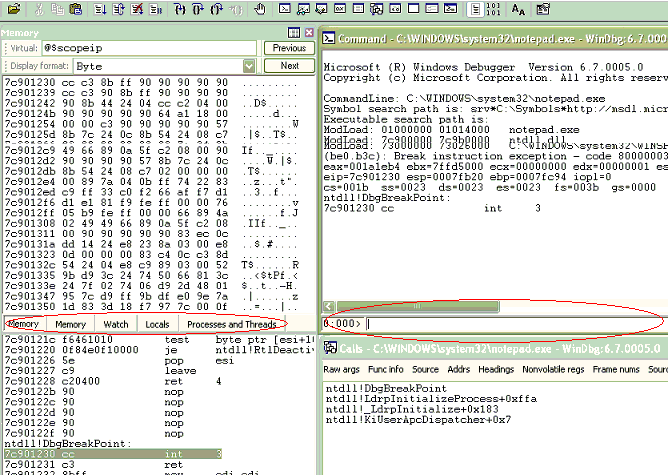
Ele não está limitado apenas para engenharia reversa de código malévolo. Esse é o uso que eu faço dele. Meu amigo Thiago, por exemplo, resolve problemas em servidores que rodam código gerenciado com WinDbg. É a maneira ideal de depurar um problema em uma máquina onde o ambiente de desenvolvimento não está disponível nem pode ser instalado. Outro ponto relevante é que ele não depura apenas um programa em particular, mas pode ser usado para depurar um sistema inteiro. Chamado de kernel debugging, podemos usar esse modo de funcionamento para resolver os problemas que surgem logo depois de espetar algum periférico novo comprado na Santa Ifigênia.
Mas esse artigo não é apenas sobre o WinDbg. Ele não vem sozinho. É uma interface amigável para alguns depuradores linha de comando e outras ferramentas disponíveis no Debugging Tools for Windows, pacote disponível gratuitamente no sítio da Microsoft e atualizado geralmente de seis em seis meses. Nele podemos encontrar:
- CDB: depurador que roda em user mode e é uma "linha de comando agradável" para um programador avançado.
- NTSD: depurador que roda em user mode, da mesma forma que o CDB, mas também pode ser usado como um redirecionador de comandos para o depurador de kernel (logo abaixo). Existem algumas diferenças sutis entre esses dois depuradores (como o fato do NTSD não criar janelas quando usado como redirecionador), mas são diferenças que se aprendem no dia-a-dia.
- KD: depurador que roda em kernel mode, pode analisar dados do sistema local ou depurar um sistema remoto conectado através de um cabo serial ou por meio de um pipe criado por uma máquina virtual.
Existem outros métodos mais avançados ainda para conseguir depurar uma máquina tão tão distante, por exemplo.
- Logger: tracer de chamadas de funções da API. Pode ser usado para análise de performance ou para fazer o que eu faço com os trojans, que é dar uma olhada nas funções que eles chamam constantemente.
- Logviewer: visualiza resultados gerados pelo Logger.
Existem ainda outras ferramentas, mas estas são as principais que costumo utilizar. Para saber como usá-las de acordo com suas necessidades recomendo a leitura de um pequeno tutorial para o WinDbg que vem junto da instalação, o kernel_debugging_tutorial.doc. Ele é apenas a introdução dos principais comandos e técnicas. Depois de ter dominado o básico, pode partir para o arquivo de ajuda, que detalha de forma completa todos os comandos, técnicas e ferramentas de todo o pacote: o debugger.chm. A maioria dos comandos que precisava encontrei usando essa ajuda ou em alguns blogs muito bons, como o Crash Dump Analysis. Porém, acredite: no WinDbg, você quase sempre vai encontrar o comando que precisa.
Para exemplificar um uso prático dessas ferramentas vamos usar o Logger para descobrir quais funções API estão sendo chamadas constantemente por um cavalo de tróia, uma coisa um tanto comum em ataques a bancos. Para tornar as coisas mais reais ainda vamos utilizar o código-fonte de um suposto cavalo de tróia usado em minhas apresentações:
#include <windows.h>
#include <shlwapi.h>
int WINAPI WinMain(...)
{
CHAR wndTxt[MAX_PATH];
while( true )
{
HWND fgWin = GetForegroundWindow();
wndTxt[0] = 0;
if( GetWindowText(...) )
{
if( StrStrI(wndTxt, "Fict Bank") )
{
MessageBox(fgWin,
"Hi! Like to be under attack?",
"Free Trojan",
MB_OK);
break;
}
}
}
ExitProcess(ERROR_SUCCESS);
}
Para compilar esse programa, você só precisa digitar os seguintes comandos em um console do Visual Studio:
cl /c freetrojan.cpp link freetrojan.obj user32.lib shlwapi.lib
O logger.exe possui uma extensão que pode ser usada pelo WinDbg para usar os mesmos comandos a partir do depurador. Mas para tornar as coisas mais fáceis nesse primeiro contato iremos iniciar o programa através do próprio executável:
logger freetrojan.exe
Irá aparecer uma janela onde selecionamos o conjunto de APIs que serão capturadas. Podemos manter todas as categorias selecionadas e mandar rodar usando o botão "Go". Aguarde o programa executar por um tempo para termos um pouco de dados para analisar. Em minhas análises reais eu geralmente deixo ele atacar, seja no sítio real do banco ou em uma armadilha. Depois do ataque posso confirmar qual a API que ele utilizou. Se quiser fazer isso nesse teste basta criar uma janela que contenha o texto "Fict Bank" em seu título. Após isso, podemos finalizar o processo pelo Gerenciador de Tarefas.
Mesmo após finalizá-lo ele continuará na lista de processos, como se tivesse travado. Na verdade, a parte injetada do Logger mantém o processo no ar, em um estado semi-morto (ou semi-vivo). Depois de finalizar o Logger fechando sua janela principal ambos os processos terminam e podemos ler o resultado da captura em uma pasta chamada LogExts criada por padrão no Desktop ou Área de Trabalho. Podemos dar uma olhada nos resultados através do visualizador de logs gerados, o Logviewer.
Algumas colunas do Logviewer são tão úteis que vale a pena mencioná-las:
- Module: determina quem chamou a API, o próprio executável ou alguma DLL.
- Call Duration: tempo em milissegundos que a chamada da função demorou.
- API Function: o nome da função API que foi chamada.
- Return Value: o retorno da chamada da função.
De quebra ele exibe todos os parâmetros das funções de acordo com o tipo, identificando inclusive quando se trata de uma enumeração ou define reservado. Essa "mágica" é feita interpretando os headers que ficam na pasta Debugging Tools for Windows, winext, manifest, tarefa executada pelo Logger no início.
O Debugging Tools é um pacote extremamente poderoso de ferramentas para programadores avançados. De maneira alguma conseguirei cobrir tudo que é possível fazer com essas ferramentas em apenas um blog e muito menos em um post. Porém, espero que essa pequena introdução seja o começo de uma série de artigos bem interessantes sobre debugging e uma série de testes realizados pelos meus leitores.
# Disassembling the array operator
Caloni, 2007-06-22 <computer> ccpp> english> code> [up] [copy]Arrays are fascinating in C language because they are so simple and so powerful at the same time. When we start to really understand them and realize all its power we are very close to understand another awesome feature of the language: pointers.
When I was reading the K&R book (again) I was enjoying the language specification details in the Appendix A. It was specially odd the description as an array must be accessed:
A postfix expression followed by an expression in square brackets is a postfix expression. One of the expressions shall have the type "pointer to T" and the other shall have enumeration or integral type. The result is an lvalue of type "T". (...) The expression E1 [ E2 ] is identical (by definition) to *( (E1) + (E2) ).
Notice that the rules don't specify the order of expressions to access the array. In other words, it doesn't matter for the language if we use a pointer before the integer or an integer before the pointer.
#include <iostream>
#include <cassert>
int main()
{
char q[] = "Show me your Code, "
"and I'll tell you who you are.";
int i = 13;
std::cout
<< "And the language is: "
<< q [ i ]
<< std::endl;
assert( q[i] == i[q] );
assert( q[13] == 13[q] );
assert( *(q + i) == "That's C!"[7] );
return 13[q] - "CThings"[0];
}
The `q[i]` bellow shows that we can use both orders and the code will compile successfully.
std::cout
<< "And the language is: "
<< i [ q ]
<< std::endl;
This code doesn't show how obscure we can be. If we use a constant integer replacing the i, by example, the code starts to be an IOCCC participant:
std::cout
<< "And the language is: "
<< 13 [ q ]
<< std::endl;
Is this a valid code yet, right? The expression types are following the rule. It is easy to see if we always think about using the "universal match" *( (E1) + (E2) ). Even bizarre things like this are easy to realize:
std::cout
<< 8["Is this Code right?"]
<< std::endl;
Obs.: this kind of "obscure rule" hardly will pass in a code review since it is a useless feature. Be wise and don't use it in production code. This is just an amusing detail in the language specification scope. It can help in analysis, never in programming.
# História do Windows - parte 1.0
Caloni, 2007-06-26 <computer> windows history [up] [copy]Devido à grande procura através de mecanismos de busca (vulgo Google), estarei republicando esse artigo dividido em partes (até porque existem partes não acabadas), cada parte descrevendo um conceito geral do que representou cada versão do sistema operacional. Bem-vindos ao História do Windows.
Tudo começou em 1981, quando chegou às lojas o primeiro IBM PC, uma poderosa máquina de 4.7 MHZ, 64 (KB!) de RAM e um drive de disquete de 160 KB. Já havia sido lançado em agosto o MS-DOS, sistema operacional encomendado pela IBM à empresa recém-criada por Paul Allen e Bill Gates, a Microsoft Corporation. O DOS foi baseado num sistema básico anterior produzido pela Seattle Computer Products.
No mesmo ano uma empresa chamada Xerox pôs ao mundo uma estação de trabalho gráfica chamada Star. Do Star vieram os conceitos de janelas, ícones, e o uso de um hardware apontador de tela chamado de mouse. De lá foram tiradas, portanto, as principais idéias que moldaram a criação dos futuros sistemas operacionais que revolucionaram o conceito de interação computador/usuário, como o LISA, da Apple -- que mais tarde também deu origem ao Macintosh -- e o sistema gráfico da Microsoft chamado Windows.
Em novembro de 1983 a Microsoft Corporation anuncia oficialmente, no Plaza Hotel em Nova York, o Microsoft Windows, a próxima geração de sistemas operacionais que irá ter uma interface gráfica para o usuário (GUI) e ambiente multitarefa. É possível que o nome original do sistema tivesse sido Interface Manager se um dos gênios do departamento de marketing da Microsoft, Rowland Hanson, não tivesse convencido o fundador da empresa, Bill Gates, que Windows seria um nome melhor por ser mais intuitivo. A promessa inicial dizia que o sistema iria ser lançado em abril do próximo ano.
No início daquele ano, então, foi mostrada uma versão beta aos chefões da IBM, que não se mostraram muito entusiamados. Na verdade, a criadora do Personal Computer estava trabalhando num novo projeto que substituiria o sistema original da Microsoft, o MS-DOS.
Surgiram concorrentes potenciais do Microsoft Windows. VisiOn, da VisiCorp, foi a primeira GUI oficial lançada para PC. GEM (Graphical Environment Manager), lançada pela Digital Research no começo de 1983. No entanto ambos careciam do suporte de desenvolvedores para a plataforma. Ora, se ninguém quer fazer programas para um sistema, quem vai querer comprá-lo?
Um produto chamado Top View fora lançado pela IBM em fevereiro de 1985, baseado em DOS com um gerenciador multitarefa, mas sem uma GUI. Era lento e precisava de muita memória. Acabou sendo descontinuado dois anos depois e nunca chegou a ter uma interface gráfica.
Antes do lançamento do Windows, advogados da Apple alertavam sobre a possibilidade do sistema infringir os direitos e patentes que a empresa tinha sobre as características da sua interface gráfica, a LISA (janelas com barra de título, menus drop-downs, suporte a mouse, etc). Daí o fundador da Microsoft, Bill Gates, teve a idéia brilhante de firmar um contrato de licença com a Apple, dando-lhe o direito de incluir em todas as futuras versões do Windows e programas os conceitos de GUI adquiridos pelo sistema gráfico da Apple (isso antes do Windows ser lançado).
Finalmente, em 20 de novembro de 1985, a Microsoft lança o Windows 1.0, quase dois anos depois da promessa inicial. Foi vendido inicialmente por 100 USD. Continha em seu pacote: MS-DOS Executive, Calendar, Cardfile, Notepad, Terminal, Calculator, Clock, Reversi, Control Panel, PIF (Program Information File) Editor, Print Spooler, Clipboard, RAMDrive, Windows Write e Windows Paint.
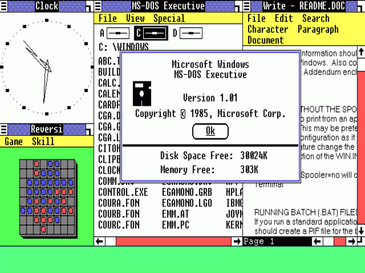
O novo sistema não fez muito sucesso de imediato. Pelo contrário, foi considerado lento e primitivo. Devido às limitações impostas pela Apple o sistema não pôde apresentar certas características como a sobreposição de janelas e a famosa lixeira (um conceito proprietário da Apple). Ficou cerca de dois anos boiando no mercado até que foi lançado um produto chamado Aldus PageMaker 1.0. PageMaker foi o primeiro programa WYSIWYG (What You Seee Is What You Get) para o PC. Tinha a grande novidade de juntar tipos e gráficos no mesmo documento. Depois de um ano, a Microsoft lança uma planilha de cálculos chamada Excel. Mais tarde outros produtos como Microsoft Word e Corel Draw ajudaram a aumentar a popularidade do Windows, embora esse ainda precisasse de muitas melhoras.
# A Inteligência do if: Parte 2
Caloni, 2007-06-29 <computer> <programming <philosophy> <assembly> <closed> [up] [copy]Vimos na primeira parte desse artigo como o if revolucionou o mundo da computação ao trazer um salto que depende de condições anteriores e, portanto, depende do estado do programa. A ele chamamos de salto condicional. Também vimos como o resto das construções lógicas de uma linguagem são apenas derivações montadas a partir de saltos condicionais e incondicionais. Nesta segunda parte veremos como implementar um saldo condicional baseando-se no fato de que o computador pode apenas realizar operações matemáticas. Afinal de contas, um computador não "pensa".
Uma condição, item necessário para o funcionamento do salto condicional, nada mais é do que o conjunto de um cálculo matemático e o seu resultado, sendo o salto dependente desse resultado. Geralmente o resultado usado é uma flag, um indicador, definida pela arquitetura, como o armazenador de resultado para comparações de igualdade. Na plataforma 8086, por exemplo, as instruções que comparam memória definem uma flag chamada de Zero Flag (ZF) que é modificada sempre logo após executada uma instrução da categoria de comparações de valores.
É comum nas arquitetura o resultado de uma comparação ser igual a zero se os elementos são iguais e diferente de zero se são diferentes. O resultado, então, denota a diferença entre as memórias comparadas, e se não há diferença o resultado é zero.
set memA, 1 set memB, 1 cmp memA, memB # ZF=0 set memA, 1 set memB, 0 cmp memA, memB # ZF=1
Mas como de fato comparar? Aí é que reside a mágica das portas lógicas e operações booleanas. A comparação acima pode ser feita com uma porta lógica XOR, o OU-eXclusivo, por exemplo, e o resultado pode ser obtido e armazenado se a saída for conectada a um flip-flop (um flip-flop, ou multivibrador biestável, é um circuito de computador capaz de armazenar o valor de 1 bit, o necessário para o nosso salto). Vamos por partes.
Uma porta lógica é uma série de circuitos que recebe uma ou mais entradas e que resulta em uma saída, sendo as entradas e a saída representadas pelo sinal 1 e 0. As portas lógicas costumam ser nomeadas pela sua função na lógica booleana. Dessa forma, uma porta AND, ou E, é uma porta em que a saída será 1 se todas as suas entradas forem 1, e 0 se pelo menos uma de suas entradas for 0.
Um flip-flop é o circuito que é usado para armazenar os resultados das portas lógicas de forma que após ter sido alimentado o valor não se perde. É o bloco mais fundamental de memória de um computador. Ele não se esquece depois que as entradas foram zeradas e pode ser reiniciado quando novas entradas forem fornecidas. É a maneira de gravar dados temporários na memória RAM da placa-mãe ou na memória cache do processador.
O flip-flop serve para que o valor do ZF permaneça após a instrução XOR entre os registradores que serão comparados. Eis como funciona: é usada uma porta lógica XOR para cada um dos bits dos valores comparados, fazendo com que qualquer bit diferente tenha uma saída 1. Se todos os bits dos valores comparados forem iguais a zero, significa que os valores são idênticos. Para agrupar todas essas saídas é usada uma porta lógica OR, fazendo com que um único bit diferente de zero (ou mais) reflita na saída. A saída da porta OR, por sua vez, é invertida através da porta NOT colocada antes do flip-flop. Ou seja, se os valores forem idênticos (saída zero da porta OR) a saída final será 1, do contrário será zero.
No final das contas, esse valor armazenado por um flip-flop é a flag ZF da arquitetura 8086. Se houver alguma diferença entre os valores, como foi o caso no exemplo acima, o valor final será o um invertido, ou seja, zero. Esse valor armazenado pode ser usado nas próximas instruções para realizar o salto, que dependerá do que estiver nessa flag. Dessa forma temos o nosso resultado realizado automaticamente através de um cálculo matemático.
Um salto incondicional, como vimos na parte um, é um salto para um outro ponto no código que vai ser feito de qualquer forma. Pode ser uma instrução do processador saltar para um endereço definido em algum lugar da memória. O goto possui como destino o endereço X, sendo que X depende do que estiver em seu próprio endereço.
001 set memA, 004 002 jump memA 003 code # not executed 004 code 005 ...
Agora, para executar o salto condicional, precisamos não apenas de um, mas de dois endereços de destino, cada um deles com um endereço de memória. Podemos definir o primeiro endereço como o armazenador do salto se a condição for falsa, e o segundo endereço se a condição for verdadeira.
001 set memA, 006 002 set memB, 005 003 cmp memC, memD 004 jz memA 005 code # ZF=1 006 code # ZF=0 007 ...
Se os valores em memC e memD forem iguais a comparação feita na linha 003 deixará o ZF igual a 0 e portanto o comando jz (jump if zero, saltar se zero) irá realizar o salto para a linha 006, que é o endereço contido em memA. Caso contrário não será feito o salto, ou seja, a próxima instrução será a da linha 005, a mesma contida em memB.
Agora você pode estar se perguntando por que existe o endereço em memB, já que se a condição for falsa o código simplesmente seguirá o fluxo normal. Bom, este memB é meramente figurativo, pois estou tentando demonstrar como não existe, de fato, uma "inteligência" na instrução de comparação que determine a igualdade de dois valores. Tudo se resume a circuitos realizando cálculos matemáticos.
Para isso continue imaginando o memB sendo usado como o endereço a ser usado caso a condição falhe. Esse endereço está localizado logo após o memA na memória. Se memA estiver em 080, memB estará em 081.
080 memA # 006 081 memB # 005
Dessa forma, para executar o salto baseado em um resultado de 0 ou 1 (o Zero Flag) só temos que alterar o endereço da próxima instrução para o valor do endereço de comparação mais o valor de ZF, que pode ser 1 ou 0. Se for 0 será o próprio endereço da condição (memA), mas se for 1 será esse endereço mais 1 (ZF), ou seja, memB.
001 set memA, 006 002 set memB, 005 003 cmp memC, memD # muda ZF 004 jump [memA + ZF] 005 code # ZF=1 006 code # ZF=0 007 ...
Lembre-se que essa é apenas uma demonstração de como pode funcionar um salto condicional através de cálculos matemáticos. De maneira alguma estou afirmando que é feito dessa forma. Aliás, existem inúmeras formas de realizar esse salto. Uma segunda solução seria adicionar a defasagem (offset) entre o endereço da próxima instrução e o endereço do salto. Meu objetivo foi apenas ilustrar que, dado um problema, pode haver várias soluções. Talvez mais para a frente veremos como é implementado um if em assembly, subindo mais um nível de abstração. Por enquanto estamos apenas trabalhando no nível filosófico. O mais importante de todos.
[index] [2007-07]