- Desenvolvendo em linha de comando
- Responsabilidade
- Ponteiros de método: conceito fundamental
- Ponteiro de método: qual this é usado?
- Detectando hooks globais no WinDbg (SetWindowsHookEx)
- MouseTool
- SDelete
- História do Windows - parte 5.1
- Usando a libc nativa do Windows
- Carregando DLLs arbitrárias pelo WinDbg
- Carregando DLLs arbitrárias pelo WinDbg ou como escrever script para WinDbg
- Desenhando em C++ Builder
# Desenvolvendo em linha de comando
Caloni, 2007-11-01 [up] [copy]Desde uns tempos para cá o Visual Studio tem se tornado uma das ferramentas mais pesadas de desenvolvimento já criadas. Como se não bastasse, a compilação de pequenos trechos de código é algo desnecessariamente complicado no ambiente. Por esse motivo estou ganhando o costume de usar a linha de comando para esse tipo de tarefa. Afinal de contas, na maioria das vezes a única coisa que eu preciso fazer é abrir o atalho "Visual Studio Command Prompt" e digitar uma linha: cl meu-codigo-fonte-do-coracao.cpp.
O problema é ter que "andar" do diretório padrão de início até a pasta onde está o código-fonte que desejo compilar. Porém, isso é facilmente resolvido com uma linha (no registro), dentro de HKCR, Folder, shell, Console, command crie a chamada ao cmd.exe passando a bat que constrói o ambiente para o Visual Studio C++. A partir daí, o comando "Console" existe no menu de contexto de qualquer pasta que clicarmos no Windows Explorer.
Note que é possível criar outros comandos, como é o meu caso, onde preciso de vez em quando compilar utilizando o Visual Studio 2005 (o comando Console) e o Visual Studio 2003 (o comando VS2003). Ao escolher a opção, um prompt de comando é aberto com o ambiente de compilação montado e (adivinhe) com a pasta padrão sendo a que foi clicada no explorer.
Nossos projetos aqui na empresa costumam ser divididos em inúmeras soluções do Visual Studio para evitar a bagunça que seria (foi) ter que abrir uma solução de 10^24324 projetos. O problema é que, se abrir um Visual Studio já pesa, imagine abrir cinco de uma vez.
Por isso mesmo que, aproveitando que agora tenho uma linha de comando personalizada com o ambiente de compilação, faço uso da compilação de soluções em modo console que o devenv (a IDE do Visual Studio) oferece: devenv meu-solution-do-coracao.sln /build Debug ou devenv meu-project-do-coracao.vcproj /build Release. Além de ser rápido, pode ser usado em builds automatizados, coisa que já fazemos. O que quer dizer que podemos matar os itens 2 e 3 do teste do Joel, nos deixando um passo mais próximo do purgatório.
Tudo bem, mas eu preciso depurar o código! Você não quer que eu use o ntsd.exe, ou quer?
Sabe que não é uma má idéia?
Porém, se você prefere algo mais amigável, mais ainda que o WinDbg, você pode iniciar o depurador do Visual Studio por linha de comando: vsjitdebugger notepad.exe ou vsjitdebugger -p meu-pid-do-coracao. Daí não tem jeito: você economiza no start, mas o Visual Studio vai acabar subindo. Ou um ou outro. Por isso eu recomendo aprender a usar o WinDbg ou até o NTSD. Quer dizer, é muito melhor do que esperar por uma versão mais light do Visual Studio no próximo ano.
# Responsabilidade
Caloni, 2007-11-01 <quotes> <self> <now> [up] [copy]Assumir responsabilidade por este momento é estar em harmonia com a vida.
Tolle, Eckhart (O Poder do Agora, 1997)
# Ponteiros de método: conceito fundamental
Caloni, 2007-11-05 <computer> [up] [copy]Diferente de ponteiros de função globais ou estáticas, que são a grosso modo ponteiros como qualquer um, os ponteiros de método possuem uma semântica toda especial que costuma intimidar até quem está acostumado com a aritmética de ponteiros avançada. Não é pra menos: é praticamente uma definição à parte, com algumas limitações e que deixa a desejar os quase sempre criativos programadores da linguagem, que vira e mexe estão pedindo mudanças no C++0x.
Três regras iniciais que devem ser consideradas para usarmos ponteiros para métodos são:
- A semântica para lidar com ponteiros de método é totalmente diferente de ponteiros de função.
- Ponteiros de método de classes distintas nunca se misturam.
- Para chamarmos um ponteiro de método precisamos sempre de um objeto da classe para a qual ele aponta.
Visto isso, passemos a um exemplo simples, um chamador de métodos aleatórios, que ilustra o princípio básico de utilização:
#include <iostream>
#include <time.h>
class Rand;
typedef void (Rand::*FP)();
class Rand
{
public:
Rand()
{
srand(time(NULL));
}
FP GiveMeFunc()
{
return m_funcs[rand() % 3];
}
private:
void FuncOne() { std::cout << "One!\n"; }
void FuncTwo() { std::cout << "Two!\n"; }
void FuncThree() { std::cout << "Three!\n"; }
static FP m_funcs[3];
};
FP Rand::m_funcs[3] = { &FuncOne, &FuncTwo, &FuncThree };
void passThrough(FP fp)
{
Rand r;
( r.*fp )(); // <<-- this
}
/** No princípio Deus disse:
'int main!'
*/
int main()
{
Rand r;
FP fp;
fp = r.GiveMeFunc();
passThrough(fp);
}
Como podemos ver, para o typedef de ponteiros de método é necessário especificar o escopo da classe. Com isso o compilador já sabe que só poderá aceitar endereços de métodos pertencentes à mesma classe com o mesmo protótipo. Na hora de atribuir, usamos o operador de endereço e o nome do método (com escopo, se estivermos fora da classe). É importante notar que, diferente de ponteiros de função, o operador de endereço é obrigatório. Do contrário:
error C4867: 'Rand::FuncOne': function call missing argument list; use '&Rand::FuncOne' to create a pointer to member
E, por fim, a chamada. Como é a chamada de um método, é quase intuitiva a necessidade de um objeto para chamá-la. Do contrário não teríamos um this para alterar o objeto em qualquer método não-estático, certo? Daí a necessidade do padrão C++ especificar dois operadores especialistas para esse fim, construídos a partir da combinação de operadores já existentes em C:
Rand r; Rand* pr = &r; // [obj] .* [method ptr] ( r.*pMethod )(); // [obj ptr] ->* [method ptr] ( pr->*pMethod )();
Esses operadores obrigam o programador a sempre ter um objeto e um ponteiro. Daí não tem como errar. Infelizmente, devido à ordem de precedência, temos que colocar os parênteses em torno da expressão para chamar o método. Pelo menos fica equivalente ao que precisávamos fazer antes da padronização da linguagem C.
# Ponteiro de método: qual this é usado?
Caloni, 2007-11-07 <computer> [up] [copy]Depois de publicado o artigo anterior sobre ponteiros de métodos surgiu uma dúvida muito pertinente do autor do blogue CodeBehind, um escovador de bits disfarçado de programador .NET: qual objeto que vale na hora de chamar um método pelo ponteiro?
Isso me estimulou a desdobrar um pouco mais os mistérios por trás dos ponteiro de métodos e de membros, e descobrir os detalhes mais ocultos desse lado esotérico da linguagem.
Para entender por inteiro o que acontece quando uma chamada ou acesso utilizando ponteiros dependentes de escopo, algumas pequenas mudanças foram feitas na nossa pequena classe Rand.
#include <iostream>
#include <time.h>
class Rand;
typedef void (Rand::*FP)();
typedef int Rand::*MP;
class Rand
{
public:
Rand()
{
m_num = rand() % 100;
}
int m_num;
void Print()
{
std::cout << "this: "
<< std::hex << this
<< ", member: "
<< std::dec << m_num
<< std::endl;
}
};
/** No princípio Deus disse:
'int main!'
*/
int main()
{
srand(time(NULL));
Rand r1, r2, r3;
FP fp = &Rand::Print;
MP mp = &Rand::m_num;
(r1.*fp)();
(r2.*fp)();
(r3.*fp)();
std::cout << std::endl;
std::cout << "this: "
<< std::hex << &r1
<< ", member: "
<< std::dec << r1.*mp
<< std::endl;
std::cout << "this: "
<< std::hex << &r2
<< ", member: "
<< std::dec << r2.*mp
<< std::endl;
std::cout << "this: "
<< std::hex << &r3
<< ", member: "
<< std::dec << r3.*mp
<< std::endl;
}
O novo código chama através do mesmo ponteiro o mesmo método (duh), mas através de três objetos diferentes. Se observarmos a saída veremos que cada instância da classe guardou um inteiro aleatório diferente para si:
this: 0012FF6C, member: 97 this: 0012FF5C, member: 5 this: 0012FF60, member: 44 this: 0012FF6C, member: 97 this: 0012FF5C, member: 5 this: 0012FF60, member: 44
Cada compilador e plataforma tem a liberdade de implementar o padrão C++ da maneira que quiser, mas o conceito no final acaba ficando quase a mesma coisa. No caso de ponteiros de métodos, o ponteiro guarda realmente o endereço da função que pertence à classe. Porém, como todo método não-estático em C++, para chamá-lo é necessário possuir um this, ou seja, o ponteiro para a instância:
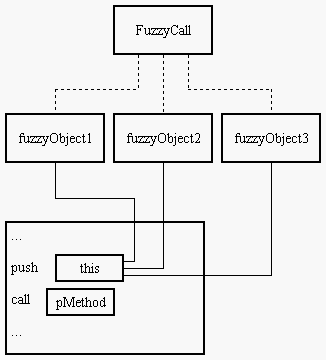
Em assembly teremos algo assim:
; FP fp = &Rand::Print; lea rax,[Rand::Print] mov qword ptr [fp],rax ; (r1.*fp)(); lea rcx,[r1] call qword ptr [fp] ; (r2.*fp)(); lea rcx,[r2] call qword ptr [fp] ; (r3.*fp)(); lea rcx,[r3] call qword ptr [fp]
Além do ponteiro de métodos, também é possível no C++ apontar para membros de um dado objeto como foi feito no exemplo acima. Para tanto, como vimos no código, basta declarar um tipo de ponteiro de membro de acordo com o tipo desejado com o escopo da classe: typedef int Rand::*MP. Nesse caso, a técnica de usar o próprio enderenço não funciona, já que cada objeto possui um membro próprio em um lugar de memória próprio. Porém, assim como os ponteiros de métodos, os ponteiros de membros exigem um objeto para serem acessados, o que já nos dá a dica de onde o objeto começa. Sabendo onde ele começa, fica fácil saber onde fica o membro através do seu offset, ou seja, a distância dele a partir do início da memória do objeto. O código abaixo simplifica a obtenção de um objeto dentro da classe usando ponteiro para membros:
MP mp = &Rand::m_num; int i1 = r1.*mp; int i2 = r2.*mp; int i3 = r3.*mp;
Note no assembly gerado que para isso funcionar o código precisa do offset armazenado em algum lugar. E, nada mais óbvio, o "ponteiro" de um membro de uma classe nada mais é que o offset deste membro dentro desta classe.
; MP mp = &Rand::m_num; mov dword ptr [mp],0 ; int i1 = r1.*mp; movsxd rax,dword ptr [mp] mov eax,dword ptr r1[rax] mov dword ptr [i1],eax ; int i2 = r2.*mp; movsxd rax,dword ptr [mp] mov eax,dword ptr r2[rax] mov dword ptr [i2],eax ; int i3 = r3.*mp; movsxd rax,dword ptr [mp] mov eax,dword ptr r3[rax] mov dword ptr [i3],eax
Como podemos ver, não é nenhuma magia negra a responsável por fazer os ponteiros de métodos e de membros funcionarem em C++. Porém, eles não são ponteiros ordinário que costumamos misturar a torto e a direito. Essa distinção na linguagem é importante para manter o código "minimamente sadio".
# Detectando hooks globais no WinDbg (SetWindowsHookEx)
Caloni, 2007-11-09 <computer> [up] [copy]Nada como um comando prático para aprender rapidamente uma técnica. Nesse caso, tive que usar o seguinte comando para localizar o momento em que um executável instala um hook global: bp user32!SetWindowsHookExA "j poi(esp+4*4) 'g' ; '.echo *** GLOBAL HOOK ***; g'".
Vamos analisar cada um desses subcomandos um a um.
No WinDbg é possível definir um ou mais comandos que são executados quando um breakpoint é acionado. Esses comandos ficam entre aspas duplas e podem conter as mesmas coisas que digitamos na linha de comando. Alguns comandos, porém, são mais úteis que outros nesse contexto. Por exemplo, o comando ".echo". Podemos digitar .echo na linha de comando do WinDbg. O que acontece?
0:000> .echo O que acontece? O que acontece?
Exatamente o que o comando se dispõe a fazer: imprimir seus argumentos na tela. E qual a vantagem nisso? Nenhuma, se estamos na linha de comando, mas muita se estivermos colocando um breakpoint onde queremos contar o número de vezes que passamos por lá, o comando tem serventia:
0:000> bp $exentry ".echo Passou pelo main; g" 0:000> g ModLoad: 5cb70000 5cb96000 ShimEng.dll ModLoad: 774e0000 7761d000 ole32.dll ... ModLoad: 5ad70000 5ada8000 UxTheme.dll Passou pelo main ModLoad: 74720000 7476b000 MSCTF.dll ...
Se essa mensagem fosse exibida mais de uma vez, poderíamos supor que é possível existir algum tipo de infecção na execução do aplicativo, como quando o código inicial carrega o original e volta a executar o mesmo ponto.
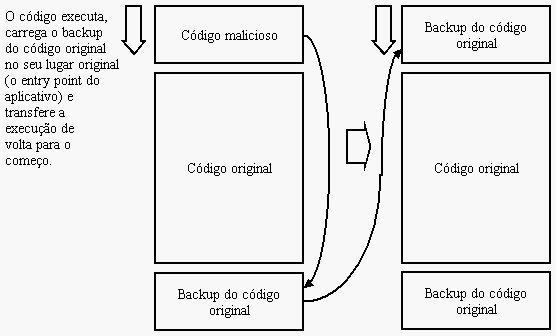
O objetivo aqui é "preparar o terreno" (ficar residente) antes que o código original seja executado. Com um simples breakpoint e um simples .echo conseguimos visualizar esse tipo de ataque. Outra possibilidade é que se trata daqueles executáveis "empacotados" por meio de algum encriptador de códigos como UPX, que desempacota o código e reexecuta o ponto de entrada do executável. Claro que esse é apenas um uso que podemos fazer desses comandos.
Aprendi o comando j antes do .if, por isso acabo usando mais o primeiro, mas ambos possuem similaridades. O formato desse comando é exatamente como um "if-else":
j Expression Command1 ; Command2 j Expression 'Command1' ; 'Command2'
Se Expression for verdadeiro, Command1 será executado; do contrário, Command2 será. Se você não precisa do else basta usar um comando vazio ' '. A escolha é sua em usar aspas simples ou nada. Se usar aspas simples, é possível colocar mais de um comando, que foi o que eu fiz no else: '.echo *** GLOBAL HOOK ***; g'".
Tudo depende do uso que você fizer desde comando. Algumas peculiaridades existem com relação ao uso de aspas duplas, simples, sem aspas, com ponto-e-vírgula, etc, mas são coisas que, como diz meu amigo Thiago, "só se aprende na dor".
Lembram-se de nossa peregrinação pela pilha de chamadas quando fizemos um hook na função MessageBox pelo WinDbg? Aqui é a mesma coisa, pois estou analisando um parâmetro passado na pilha (esp): o ID da thread para onde vai o hook.
HHOOK SetWindowsHookEx(
int idHook,
HOOKPROC lpfn,
HINSTANCE hMod,
DWORD dwThreadId);
Relembrando nosso passeio pela pilha, ao entrar em uma função stdcall, os primeiros 4 bytes são o endereço de retorno, os próximos o primeiro parâmetro e assim por diante. O que quer dizer que poi ( esp + (4 * 4) ). É o apontado do quarto parâmetro (4*4) que está sendo verificado. Concluindo, se o parâmetro dwThreadId for igual a zero, estamos diante de um hook global, e é o momento em que meu .echo vai exibir na tela "*** GLOBAL HOOK ***". Do contrário, a execução vai continuar silenciosamente.
# MouseTool
Caloni, 2007-11-13 <english> <projects> [up] [copy]Well, as most of you already know, I really don't like mice. Nevertheless I respect the users who use it and like it. That is the reason why I am writing a little more about it. This time, I going to show a program I use every day: MouseTool, for the users who does not use the mouse and like it.
The program main purpose is to avoid clicking the mouse, simulating a click every time the user stops to move the cursor. Just this: simple, efficient and mouseless =).
There are some options like drag-and-drop and double-click, both available through the program. You can choose to use a keyboard shortcut or the mode state, where you can switch the program default among simple-click, double-click and drag-and-drop.
MouseTool was originally a open source tool. That means the lastest open source code is available, right? Wrong. Actually, I was unable to find it in every place I looked for.
Fortunately, my friend Marcio Andrey has got the source, and just like me, he wanted to make it available to everyone who would like to use it and change it.
Let's make use of this source and show how to explore a code not written by us. Normally the first things to do are: download the compacted file and extract the files into a new folder. So we find the project file (in this case, MouseTool.dsw) and try to open it. The result is a total failure, because I believe no one use the Visual Studio version that opens this kind of file (it will convert it to another one).
Normally open source projects programmers are used to get the source code files, modify them, use them, publish them and all. But this is not always true about strict Windows commercial programmers.
Given the source files, we can explore some interesting parts we'd like to do someday in our own programs. And the main part is: we have the source, but not the copyright.
Click in the link in the end of the post and make good use of it.
Update: MouseTool now has a home page and a Source Forge project! Its new name is GMouseTool.
# SDelete
Caloni, 2007-11-15 <computer> [up] [copy]Minha vida tem que ser portátil. Existem pelo menos três lugares diferentes onde costumo ficar com um computador (não o mesmo). Por causa disso, os dados mais relevantes e que precisam fazer parte do meu sistema biológico eu carrego comigo pra cima e pra baixo em meu PenDrive e MP3Player.
Até aí tudo bem. Quer dizer, mais ou menos. Dados relevantes costumam ser sensíveis, e busco sempre manter todos os arquivos sensíveis encriptados ou com uma senha específica do programa que o abre. O grande problema mesmo é que eu sei que operações no sistema de arquivos costumam deixar lastros do que já foi escrito um dia, e que é possível reaver esses dados com um pouco de persistência e sorte. É nessa hora que entra a praticidade do SDelete, uma ferramenta da SysInternals.
Desde a versão NT o Windows segue as diretivas de segurança do C2, o que entre outras coisas quer dizer que o a reutilização de um objeto no sistema operacional será protegida. Um objeto aqui está para representar recursos da máquina em geral, como páginas de memória e setores do disco. Quando um programa pede um setor de disco livre (ou uma página de memória) para uso próprio, o Windows apaga qualquer conteúdo remanescente naquele espaço de memória, evitando assim que exista uma maneira do atacante obter dados de terceiros (e.g. arquivos protegidos ou memória do sistema) sem autorização.
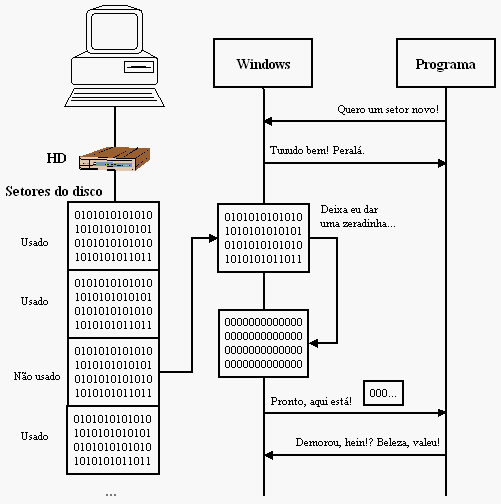
Ou seja, desde que o Windows esteja no comando, os dados escritos por um programa não estarão disponíveis ao usuário por meio do reaproveitamento dos setores. Ficou claro?
Se ficou claro, deve ter notado o "desde que o Windows esteja no comando". Essa é uma condição sine qua non, mas que nem sempre é verdadeira. Um atacante que tenha acesso físico ao dispositivo de armazenamento (e.g. meu PenDrive) pode certamente usar outro sistema operacional (ou até mesmo o Windows em condições especiais) e vasculhar os dados que eu já apaguei, pois estes, como mostra a figura, não são apagados de fato até que um programa peça o espaço ocupado por eles.
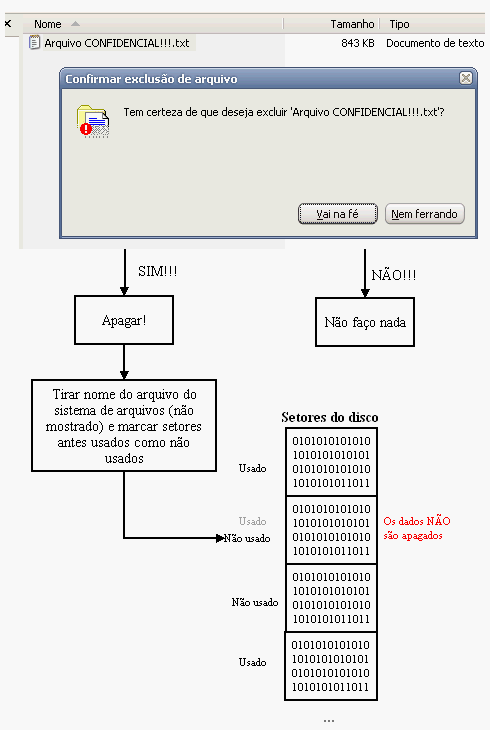
Para esse tipo de problema eu costumo usar um programinha esperto chamado SDelete (de Secure Delete). O que ele faz é zerar os setores não usados, da mesma forma com que o Windows faz quando um programa pede um setor não usado. Para isso, basta especificar um ou mais arquivos: sdelete `<nome-do-arquivo>`.
Uma outra coisa que ele faz, muito útil quando comecei a usá-lo, é apagar todos os setores não usados que existem no disco inteiro (ou uma pasta inteira). Com isso podemos começar uma vida nova. Apenas tome muito cuidado nessa hora para especificar o comando, pois um errinho no comando pode realmente fazer você começar uma vida nova: sdelete -c -s p.
O SDelete segue o padrão DOD 5220.22-M, o que quer dizer que ele está dentro das especificações da indústria que garantem a confidencialidade dos dados apagados. Além do mais, você pode especificar quantas "passadas" nos setores você deseja, para evitar aqueles ataques mais rebuscados em que é analisada a impedância das trilhas físicas de um disco magnético para obter os dados que uma vez estavam lá. É claro que isso não deve valer muito a pena se você está usando um PenDrive com memória flash =).
# História do Windows - parte 5.1
Caloni, 2007-11-19 <computer> [up] [copy]Chega às lojas no dia 25 de outubro de 2001 a unificação entre as plataformas de uso doméstico e corporativo do sistema. O Windows XP, de Windows eXPerience, usa o kernel de 32 bits de seus antecessores Windows NT e Windows 2000. É vendido em duas edições: Home e Professional Edition. O design do sistema foi totalmente remodulado para suportar ao mesmo tempo a facilidade de uso do usuário doméstico e a robustez e confiabilidade dos clientes corporativos. Essa é minha versão favorita da História do Windows e junto do Windows 7 uma das edições mais robustas já feitas.
Oriundo do Projeto Luna um dos grandes trunfos nessa versão do Windows foi (mais uma vez) a "revolução gráfica", baseada em um redesenho do velho conceito de desktop dos sistemas operacionais da Microsoft, em destaque o uso de temas e a total compatibilidade com a grande maioria das placas 3D. Sim, esse Windows foi feito pra jogar. Do ponto de vista da arquitetura, pouca coisa mudou, e essa versão mudou internamente de 5.0 (Windows 2000) para 5.1 (Windows XP). Ou seja, praticamente um patch de correção glorificado pelo departamento de marketing.
Agora, além do sistema 32 bits que todos já conheciam, é lançada a primeira versão 64 bits do Windows, o Windows XP 64-bit Edition. Na época a Intel se preparava para o fracasso de mercado que foi o Intel Itanium (IA-64) e esse Windows suportava essa nova arquitetura. Na verdade, o projeto foi além das expectativas e aplicou sua primeira versão do Windows-on-Windows 64-bit (WOW64), que permitia a execução de aplicativos 32 bits (x86) em cima da nova plataforma. Isso era feito pela tradução literal do código do assembly antigo para o assembly novo, além de outras técnicas auxiliares. (Atualmente essa versão do Windows não é mais suportada.)
Como se tornou uma prática desde os tempos do Windows NT, a versão para servidores é sempre lançada algum tempo depois da versão para estações de trabalho. Assim foi com o Windows NT Server, o Windows 2000 Server e agora com o Windows XP, rebatizado em sua versão servidores para Windows 2003 Server, cujo código é uma evolução do XP original.
Da mesma forma, com o lançamento da versão 64 para a plataforma x86, uma nova versão do Windows foi criada: a Windows XP Professional x64 Edition. Baseada no código do Windows 2003 Server SP1, essa nova versão se aproveitava da compatibilidade do x86-64 com a velha plataforma e otimizava a interação e execução dos velhos aplicativos 32, usando uma versão melhorada do WOW64, que se aproveitava da possibilidade de ficar trocando entre os modos 32 e 64 durante a execução dos aplicativos.
No decorrer dessa história avançamos uns bons 20 anos até agora. Muita coisa que deveria ter sido falada não foi, e muita coisa que não merecia ser mencionada, foi. Após esta versão outras foram criadas, mas o grande merge foi de fato o Windows XP, que lançou a plataforma NT pura para os usuários caseiros finais.

Não falarei mais aqui sobre a "outra ramificação" do Windows, aquela constituída por Windows 95, 98 e ME. Não falarei do processo antitruste contra a Microsoft por conta da venda do sistema operacional com o Internet Explorer e Media Player embutidos; não discursarei sobre os protestos dos consumidores quando a Microsoft cobrou pela versão de atualização do Windows 98, o Second Edition; muito menos esbravejarei sobre a raiva dos usuários pelo superaquecimento do processador por conta do Windows ME e sua duvidável interface revolucionária.
Pelo contrário. Acho que é uma boa hora para adentrar mais ainda nas entranhas da arquitetura NT e entender algumas coisas até então inexploradas.
Na eterna briga entre sistemas operacionais, uma categoria bem abastada (principalmente as discussões Tanenbaum x Torvalds diz respeito aos sistemas monolíticos e aos baseados em microkernel. Basicamente os sistemas monolíticos possuem todo o seu código executando em modo privilegiado, inclusive os device drivers. Nos sistemas baseados em microkernel, no entanto, existe apenas uma fina camada de interface rodando em modo privilegiado, que serve de interação entre todos os serviços, driver e aplicativos e o hardware.
O problema em si não é a organização dos componentes do sistema operacional em torno de um ou de outro design, mas o que isso implica em termos de eficiência. Se o Windows fosse desenvolvido com kernel monolítico todos seus componentes internos acessariam tudo disponível no modo kernel, o que tem o potencial de ser mais rápido. Já um sistema microkernel abstrai mais a comunicação entre os diferentes componentes do sistema.
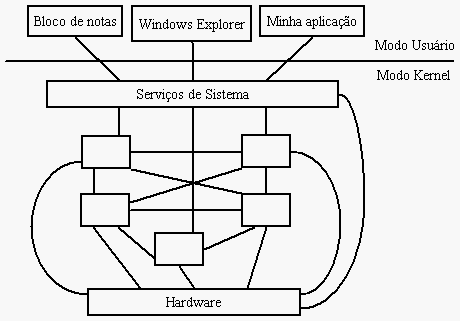
Ao ser projetado o objetivo do Windows nunca foi ser um sistema operacional de microkernel, embora umas boas almas tenham clamado o contrário. No entanto, sua organização monolítica foi feita de tal forma que uma visão lógica do sistema operacional nos diria que a tentativa original foi dividir os serviços em camadas e componentes (servidores), de forma que as camadas superiores pudessem confiar nos serviços das camadas inferiores, tal como é em uma pilha TCP/IP.
Porém, as coisas não são tão simples assim. O SO inteiro não é feito dessa forma. Foram usados diversos modelos para a organização do sistema, e é fácil perceber isso se enxergamos o todo através de várias visões. Quando isso acontece se enxerga o caos, que é o que temos quando só pensamos em módulos acessando módulos e código arbitrário rodando em kernel mode. Contudo, podemos analisar o resultado lógico da divisão em camadas em um kernel monolítico.
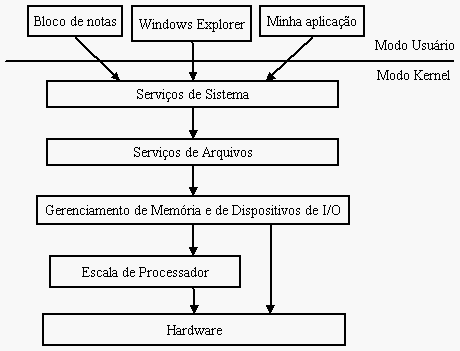
Dessa forma é possível existir uma organização no mesmo código, mesmo esteja toda em código privilegiado. Basta que os pontos de comunicação entre os módulos esteja bem definido e documentado. O problema dessa abordagem é o acesso, que não é protegido de fato, e eventuamente vão existir existir diversos atalhos (documentados ou não) para alcançar as coisas de maneira mais rápida, para o bem da velocidade.
Uma última e terceira visão, baseada em componentes, divide o código em gerenciadores e provedores de serviços. Conceitualmente essa divisão permitiria a migração de todo o código não-crítico para user mode, embora não seja o que ocorre. Essa divisão foi feita inicialmente e mantida apenas para serviços não-críticos que pudessem rodar em código não-privilegiado e a manutenção dos subsistemas: Win32, POSIX, MS-DOS. Nessa última visão conseguimos ainda visualizar um microkernel, mas é importante notar que não estamos falando aqui do conceito puro e formal que definimos no início da explicação.
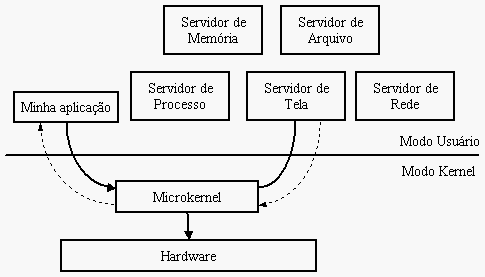
O esboço final, dessa forma, ficou sendo um sistema operacional dividido em componentes, com a maioria rodando em modo privilegiado (kernel mode), cuja divisão lógica primária tende a ser em camadas. É muito importante ter essa visão da coisa conforme nos aprofundamos nos mistérios do ring0, ou kernel mode, que controla tudo isso.
Agora esqueça essa viagem teórica de arquitetura. Para a organização dos recursos do sistema foi adotado um outro modelo, semelhante (embora não seja) ao conceito de orientação a objetos. Nesse modelo, os recursos são organizados em entidades identificáveis em sua maioria por um ponteiro opaco (kernel) ou um identificador, chamado de handle (user mode). Todos os recursos recebem o mesmo tratamento, embora se refiram a coisas extremamente diferentes, como um arquivo, uma porta de rede, um pedaço de memória, um processo e uma janela.
Essa organização foi adotada principalmente pela sua grande vantagem de minimizar mudanças, uma vez que as informações sobre os recursos são armazenadas em estruturas opacas, isto é, elas existem, porém não são acessíveis a todos. Isso permite que elas sofram mudanças internas no decorrer do tempo sem impactar para seus usuários. Essa é a abordagem pragmática que tem feito com que mesmo contando já décadas, o projeto Windows consiga avançar rapidamente junto com a tecnologia disponível para que o sistema operacional não fique parado no tempo. O que o futuro nos reserva depende apenas dos fatores externos.
# Usando a libc nativa do Windows
Caloni, 2007-11-21 <computer> [up] [copy]Por padrão, todo projeto no Visual Studio depende da libc. Isso quer dizer que, mesmo que você não use nem um mísero printf em todos os projetos criados, está atrelado a essa dependência. Em tempos onde fazer um "Hello World" pode custar 56 KB em Release - Visual Studio 2005, configuração padrão sem "buffer security check" - vale a pena economizar alguns KBytes que não se vão usar. Principalmente se essa possibilidade existe desde o cavernoso Windows 95.
Crie um novo projeto console Win32 vazio (File, New, Project, blá blá blá) e coloque um código de Hello, World nele. Configure para ele usar uma runtime estática e veja o tamanho do executável gerado. Aqui após configurar um projeto ordinário que compila um executável console ordinário que não depende de runtimes novas (exceto a kernel32.dll) meu arquivo está com 96 KB.
#include <stdio.h>
int main()
{
puts("oi, mundo!\n");
}
Desde o Windows 95, existe uma DLL na pasta de sistema chamada msvcrt.dll com a maioria das funções da libc disponíveis para link dinâmico. Só que, com o uso padrão do Visual C++, é usada sempre a biblioteca que vem junto com o ambiente, com suas trocentas funções (e consequentes bytes enche-linguiça). Porém, é possível utilizar diretamente a msvcrt.dll distribuída no diretório do sistema se criarmos uma LIB de importação para ela.
Tudo que você precisa fazer é gerar um msvcrt.def com as funções exportadas por essa dll usando o comando dumpbin.exe /exports msvcrt.dll e gerar uma lib de importação com o comando lib.exe passando no parâmetro /DEF o arquivo gerado. Abaixo um exemplo de como deve estar esse arquivo antes do comando lib /def:msvcrt.def:
LIBRARY msvcrt EXPORTS _CrtCheckMemory _CrtDbgBreak ... wprintf_s wscanf wscanf_s
Depois desse último passo geramos a LIB que precisávamos e agora só falta integrar com o projeto. Copie o msvcrt.lib para o diretório do projeto e configure no projeto esse arquivo na lista de LIBs a serem incluídas (Properties, Linker, Input, Additional Dependencies). Lembre-se de ignorar todas as LIBs padrão (Linker, Input, Ignore All Default Libraries). Para evitar unresolved external em frescuras de segurança ignore as firulas de checagem (C/C++, Code Generation, Buffer Security Check, e Basic Runtime Checks em Debug). Antes de mais nada deixe explícito o nome da função de entrada de seu programa para main, pois do contrário ele irá usar um bootstrap que inicia a libc (Linker, Advanced, Entry Point), compile e linke. E voilà!
E agora o tamanho final de nosso executável passou para espantosos 3 KB! Isso a princípio parece ótimo e dá vontade de usar em todos os projetos, mas existe um porém ainda não resolvido: as limitações da falta de um runtime. Essa é uma solução bem bobinha que não tem nada a ver com uma solução profissional 100% garantida e com suporte técnico 24 horas. Algumas coisas não vão funcionar, como inicialização de variáveis estáticas, exceções, redirecionamento de entrada/saída, etc. Contudo, para projetos simples e pequenos, isso não deverá ser um problema. No entanto, eu não garanto qualquer coisa que advier de compilações inspiradas neste artigo.
# Carregando DLLs arbitrárias pelo WinDbg
Caloni, 2007-11-23 <computer> [up] [copy]Durante meus testes para a correção de um bug me deparei com a necessidade de carregar uma DLL desenvolvida por mim no processo depurado. O detalhe é que o processo depurado é de terceiros e não possuo o fonte. Portanto, as opções para mim mais simples são:
- Usar o projeto RmThread para injetar a DLL (nesse caso iniciando o processo através dele).
- Fazer um módulo wrapper para uma DLL qualquer e ser carregado de brinde.
- Usar o WinDbg e brincar um pouco.
Por um motivo desconhecido a terceira opção me pareceu mais interessante =).
A seqüência mais simples para carregar uma DLL através do WinDbg na época que escrevi este post era chamar kernel32!LoadLibrary através de um código digitado na hora, o que podemos chamar de live assembly (algo como "assembly ao vivo"). Porém, essa simples seqüência que contém um pouco mais que uma dúzia de passos hoje teria que ser feito em assembly 64 bits e é um pouco mais complicado. Para quem ainda quer se divertir dessa forma por esse caminho irei deixar as instruções para 32 bits.
Devemos parar a execução, voltar para um ponto seguro do código com o comando gu (que volta para a função chamadora e evita perda de estado dos registradores) e armazenar o local seguro em um registrador temporário (o WinDbg tem 20 deles, $t0 até $t19).
gu r$t0 = @$ip
Note que usamos dois pseudo-registradores ($t0, o primeiro registrador temporário do WinDbg, e $ip, o registrador que aponta para a próxima instrução que será executada), mas só um deles possue o prefixo '@'. Esse prefixo diz ao WinDbg que o que segue é um registrador. Como o comando r já é usado com registradores, é desnecessário usá-lo para $t0. Se usarmos sintaxe C++ esse prefixo é obrigatório, enquanto na sintaxe MASM não. Porém, se não usarmos esse prefixo em registradores não-comuns (como é o caso para $ip) o WinDbg primeiro tentará interpretar o texto como um número hexadecimal. Ao falhar, tentará interpretar como um símbolo. Ao falhar novamente, ele finalmente irá tratá-lo como um registrador. A diferença na velocidade faz valer a pena digitar um caractere a mais. Faça a prova!
Parada a execução em um local seguro e armazenado o IP, em seguida podemos alocar memória para entrar o código em assembly da chamada, além do seu parâmetro, no caso o path da DLL a ser carregada. Para a alocação usamos o comando .dvalloc, para a escrita de uma string o comando eza (ANSI) ou ezu (UNICODE). Em seguida usamos o comando a para escrever o código assembly da chamada à função kernel32!LoadLibrary e uma interrupção 3 (breakpoint) para termos uma maneira conveniente de parada.
.dvalloc 0x1000 Allocated 1000 bytes starting at 000001d9`abd20000 eza 000001d9`abd20000 "c:\\tools\\tioclient.dll" 0:000> a 000001d9`abd20000+0x100 000001d9`abd20100 call KERNEL32!LoadLibraryA 000001d9`abd20105 int 3 000001d9`abd20106
Note que estamos usando a versão ANSI do LoadLibrary, aquela que termina com A. Sendo assim, escrevemos uma string ANSI como parâmetro usando o comando eza.
O último passo seria chamar a função previamente "editada". Para isso basta mudarmos o endereço da próxima instrução para o começo de nosso código, definir os parâmetros nos registradores (no caso apenas um, a string em rcx) e mandar executar, pois ele irá parar automaticamente no breakpoint que definimos "na mão", o int 3 digitado. Após a execução devemos voltar o ponteiro usando nosso backup no registrador $t0.
0:000> r$ip = 0x00280000+0x100 0:000> g ModLoad: 10000000 10045000 c:\\tools\\tioclient.dll (398.d90): Break instruction exception - code 80000003 (first chance) eax=10000000 ebx=7ffdd000 ecx=7c801bf6 edx=000a0608 esi=001a1f48 edi=001a1eb4 eip=0028010a esp=0007fb24 ebp=0007fc94 iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 0028010a cc int 3 0:000> r$ip = $t0 *** WARNING: Unable to verify checksum for C:tempMinhaDllInvasora.dll 0:000> g ModLoad: 5cb70000 5cb96000 C:\WINDOWS\system32\ShimEng.dll ModLoad: 6f880000 6fa4a000 C:WINDOWS\AppPatch\AcGenral.DLL ModLoad: 76b40000 76b6d000 C:WINDOWS\system32\WINMM.dll ModLoad: 774e0000 7761d000 C:WINDOWS\system32\ole32.dll ...
Como pudemos ver pela saída, a DLL foi carregada e agora temos a possibilidade de chamar qualquer código que lá esteja. Como fazer isso? Provavelmente usando o mesmo método aqui aplicado. Live-assembly é o que manda 8).
# Carregando DLLs arbitrárias pelo WinDbg ou como escrever script para WinDbg
Caloni, 2007-11-27 <computer> [up] [copy]Como pudemos ver no artigo anterior o processo para carregar uma DLL pelo WinDbg é muito extenso, enfadonho e sujeito a erros. Além de desatualizado (com comandos de assembly 32 bits). Por esse motivo, e para tornar as coisas mais divertidas, resolvi transformar tudo aquilo em um simples script que pode ser executado digitando apenas uma linha. Tenha em mente que este artigo continua desatualizado usando assembly 32 bits e hoje é uma mera curiosidade para aprendizado do passado. E se trata do meu primeiro script grande para o WinDbg, por isso, peço que tenham dó de mim =).
Um script no WinDbg nada mais é que uma execução em batch: um arquivo texto cheio de comandos que poderíamos digitar manualmente, mas que preferimos guardar para poupar nossos dedos. Existem quatro maneiras diferentes de chamar um script no WinDbg, todas muito parecidas, variando apenas se são permitidos espaços antes do nome do arquivo e se os comandos são condensados, isto é, as quebras de linhas substituídas por ponto-e-vírgula para executar tudo em uma linha só.
- $
- $>
- $$
- $$>
- $$>a
- $>
A ajuda do WinDbg descreve as diferenças dos comandos acima de forma adversa, afirmando que os comandos '<' não condensam as linhas e os '><' o fazem, quando na realidade é o contrário. Não se deixe enganar por esse detalhe. No caso do script desse artigo, utilizaremos a última forma, pois precisamos de um argumento para funcionar: o nome da DLL. Caso você não digite esse argumento, a ajuda do script será impressa:
How to use: $$>a<path\LoadLibrary.txt mydll.dll $$>a<path\LoadLibrary.txt c:\\path\\mydll.dll $$>a<path\LoadLibrary.txt "c:\\path with space\\mydll.dll"
Não há qualquer dificuldade. Tudo que você tem que fazer é baixar o script que carrega DLLs e salvá-lo em um lugar de sua preferência. Depois é só digitar o comando que carrega scripts, o path de nosso script e o nome da DLL a ser carregada em uma das três formas exibidas. Eu costumo criar uma pasta chamada "scripts" dentro do diretório de instalação do Debugging Tools, o que quer dizer que posso simplesmente chamar todos meus scripts (ou seja, 1) dessa maneira:
$$>a<scripts\LoadLibrary.txt mydll.dll
Abaixo um pequeno teste que fiz carregando a DLL do Direct Draw (ddraw.dll) na nossa vítima de plantão:
windbg notepad.exe Microsoft (R) Windows Debugger Version 6.8.0004.0 X86 Copyright (c) Microsoft Corporation. All rights reserved. CommandLine: notepad.exe Symbol search path is: SRV*C:\Symbols*http://msdl.microsoft.com/downloads/symbols Executable search path is: ModLoad: 01000000 01014000 notepad.exe ModLoad: 7c900000 7c9b0000 ntdll.dll ModLoad: 7c800000 7c8f5000 C:\WINDOWS\system32\kernel32.dll ... ModLoad: 73000000 73026000 C:\WINDOWS\system32\WINSPOOL.DRV (8e8.214): Break instruction exception - code 80000003 (first chance) eax=001a1eb4 ebx=7ffdf000 ecx=00000000 edx=00000001 esi=001a1f48 edi=001a1eb4 eip=7c901230 esp=0007fb20 ebp=0007fc94 iopl=0 nv up ei pl nz na po nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202 ntdll!DbgBreakPoint: 7c901230 cc int 3 0:000> $$>addraw.dll ModLoad: 73bc0000 73bc6000 C:\WINDOWS\system32\DCIMAN32.dll ModLoad: 76390000 763ad000 C:\WINDOWS\system32\IMM32.DLL ModLoad: 629c0000 629c9000 C:\WINDOWS\system32\LPK.DLL ModLoad: 74d90000 74dfb000 C:\WINDOWS\system32\USP10.dll Freed 0 bytes starting at 00280000 eax=001a1eb4 ebx=7ffdf000 ecx=00000000 edx=00000001 esi=001a1f48 edi=001a1eb4 eip=7c901230 esp=0007fb20 ebp=0007fc94 iopl=0 nv up ei pl nz na po nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202 ntdll!DbgBreakPoint: 7c901230 cc int 3
Simples e indolor. Vamos agora dar uma olhada no script completo e dissecar as linhas pausadamente. Dessa forma entenderemos como a função inteira funciona e como usar os comandos isoladamente para criar novos scripts.
$$
$$ @brief Loads a module inside the debuggee process.
$$ @author Wanderley Caloni <wanderley@caloni.com.br>
$$ @date 2007-11
$$
.if( ${/d:$arg1} )
{
r $t2 = @$ip
.foreach /pS 5 ( addr { .dvalloc 0x1000 } ) { r$t0 = addr }
r $t1 = @$t0 + 0x100
eza @$t0 "${$arg1}"
.echo Trying to load the following module:
da @$t0
$$ push $ip
eb @$t1 0x68
ed @$t1 + 0x01 @$t2
$$ pushfd
eb @$t1 + 0x05 0x9c
$$ pushad
eb @$t1 + 0x06 0x60
$$ push $t0
eb @$t1 + 0x07 0x68
ed @$t1 + 0x08 @$t0
$$ call LoadLibrary
eb @$t1 + 0x0c 0xe8
ed @$t1 + 0x0d ( kernel32!LoadLibraryA - @$t1 - 0x11 )
$$ popad
eb @$t1 + 0x11 0x61
$$ popfd
eb @$t1 + 0x12 0x9d
$$ ret
eb @$t1 + 0x13 0xc3
r $ip = @$t1
bp /1 @$t2 ".dvfree @$t0 0"
g
}
.else
{
.echo How to use:
.echo $$>a<path\LoadLibrary.txt mydll.dll
.echo $$>a<path\LoadLibrary.txt c:\\path\\mydll.dll
.echo $$>a<path\LoadLibrary.txt "c:\\path with space\\mydll.dll"
}
Como podemos ver, ele é um pouco grandinho. Por isso mesmo que ele é um script, já que não precisamos, sempre que formos usar este comando, ficar olhando para o fonte. Por falar em olhar, uma primeira olhada revela a seguinte estrutura:
.if( ${/d:$arg1} )
{
...
}
.else
{
...
}
Qualquer semelhança com as instruções em C não é mera coincidência. Essa estrutura de fato verifica se o resultado dentro do .if é verdadeiro. No caso o script verifica se o primeiro parâmetro foi passado, já que os argumentos são acessíveis através dos alias (apelidos) $arg1 - $argn. Essa maneira de usar os argumentos passados no WinDbg ainda não foi documentada, mas encontrei essa dica em um artigo do Roberto Farah, um grande escritor de scripts para o WinDbg.
Da mesma forma, o que não deve ser nenhuma surpresa, o WinDbg suporta comentários. Todas as linhas que contêm '$$' isoladamente são comentários, e seu conteúdo da direita é ignorado, salvo se for encontrado um ponto-e-vírgula. A primeira coisa que fazemos para carregar a DLL é salvar o estado do registrador IP, que indica onde está a próxima instrução:
r $t2 = @$ip
Feito isso, usamos um comando não tão comum, mas que pode ser muito útil nos casos em que precisamos capturar algum dado da saída de um comando do WinDbg e usá-lo em outro comando. A estrutura do .foreach deixa o usuário especificar dois grupos de comandos: o primeiro grupo irá gerar uma saída que pode ser aproveitada no segundo grupo.
.foreach /pS 5 $$pula; ( addr $$alias; { .dvalloc 0x1000 $$saída; } ) { r$t0 = addr }
A opção "/pS 5" diz ao comando para pular 5 posições antes de capturar o token que será usado no próximo comando. Os tokens são divididos por espaço. Sendo a saída de ".dvalloc 0x1000" o "Allocated 1000 bytes starting at 00280000". Pulando 5 posições iremos capturar o endereço onde a memória foi alocada. E é isso mesmo que queremos!
1 2 3 4 5 6 Allocated 1000 bytes starting at 00280000
O sinônimo do endereço (alias) se torna "addr", apelido que usamos ao executar o segundo comando, que armazena o endereço no registrador temporário $t0:
r$t0 = addr
Após alocada a memória, gravamos o parâmetro de LoadLibrary, o path da DLL a ser carregada, em seu início.
eza @$t0 "${$arg1}"
O código assembly que irá chamar fica um ponto à frente, mas na mesma memória alocada.
r $t1 = @$t0 + 0x100
Conforme as técnicas vão cada vez ficando mais "não-usuais", mais difícil fica achar um nome para a coisa. Essa técnica de escrever o assembly de um código através de escritas em hexadecimal dentro de um script do WinDbg eu chamei de "script assembly". Se tiver um nome melhor, não se acanhe em usá-lo. E me deixe saber =).
$$ push $ip eb @$t1 0x68 ed @$t1 + 0x01 @$t2 $$ pushfd eb @$t1 + 0x05 0x9c $$ pushad eb @$t1 + 0x06 0x60 $$ push $t0 eb @$t1 + 0x07 0x68 ed @$t1 + 0x08 @$t0 $$ call LoadLibrary eb @$t1 + 0x0c 0xe8 ed @$t1 + 0x0d ( kernel32!LoadLibraryA - @$t1 - 0x11 ) $$ popad eb @$t1 + 0x11 0x61 $$ popfd eb @$t1 + 0x12 0x9d $$ ret eb @$t1 + 0x13 0xc3
Cada comentário de uma instrução em assembly é seguido pela escrita dessa instrução usando o comando e. Se trata de um código bem trivial, fora alguns detalhes que merecem mais atenção.
Os comandos acima servem para salvar e restaurar o estado dos registradores e das flags de execução. Isso permite que possamos executar o código virtualmente em qualquer posição que pararmos no código depurado, já que retornamos tudo como estava ao final da execução do LoadLibrary. É claro que isso não garante que o código estará 100% estável em todas as condições, mas já ajuda um bocado.
Uma chamada através do opcode call (código em hexa 0xe80c) é bem comum e se trata de uma chamada relativa, baseada no estado do Instruction Pointer atual mais o valor especificado. Por isso mesmo que fazemos o cálculo usando o endereço de onde será escrita a próxima instrução, que é o valor que teremos em IP quando este call for executado:
( kernel32!LoadLibraryA - @$t1 - 0x11 )
Quando o código estiver completamente escrito na memória alocada, um disassembly dele retornará algo parecido com o código abaixo:
push offset ntdll!DbgBreakPoint (7c901230) ; empilhamos o IP atual (endereço de retorno) pushfd ; salva estado das flags atual pushad ; salva estado dos registradores atual push 8F0000h ; empilha endereço do path da dll a ser carregada call kernel32!LoadLibraryA (7c801d77) ; chamamos LoadLibraryA popad ; restaura estado dos registradores popfd ; restaura estado das flags ret ; retorna para o ponto onde o depurador parou (no caso, 7c901230)
Você pode ver com seus próprio olhos se editar o script comentando o último comando (g), executando o script e executando o disassembly do IP.
u @$ip
Somos um script bem comportado (na medida do possível) e por isso colocamos um breakpoint temporário no final para, quando retornarmos para o código atual, desalocarmos a memória usada para a escrita e execução das instruções.
bp /1 @$t2 ".dvfree @$t0 0"
Eu não me responsabilizo por qualquer (mau) uso do script aqui disponibilizado, assim como as eventuais perdas de código-fonte, trilhas de HD e placas de memória RAM pela sua execução. Assim sendo, bom divertimento.
O criador do DriverEntry me questionou se não seria mais fácil, em vez de escrever todos os opcodes em hexa, usar o comando a, que permite entrar o código assembly diretamente a partir de um endereço especificado. Essa realmente é uma ótima idéia, e de fato eu tentei isso no começo de meus testes. Porém, infelizmente para scripts isso não funciona bem. A partir do comando a o prompt fica esperando uma entrada do usuário, não lendo o assembly que estaria no próprio script. Pior ainda, a escrita do assembly não permite usar os registradores temporários, como $t0 ou $t1, o que nos força a escrever um código dependende de valores constantes. Por esses motivos, tive que apelar para o comando e, que é a forma mais confusa de escrever e entender assembly. Nesse tipo de edição é vital comentar bem cada linha que se escreve.
# Desenhando em C++ Builder
Caloni, 2007-11-29 <computer> <cppbuilder> [up] [copy]Uma das partes mais fáceis e divertidas de se mexer no C++ Builder é a que lida com gráficos. A abstração da VCL toma conta da alocação e liberação dos objetos gráficos da GDI e nos fornece uma interface para desenhar linhas e figuras geométricas, mexer com bitmaps, usar fontes etc. Concomitantemente, temos acesso ao handles "crus" da Win32 API para que possamos chamar alguma função esotérica necessária para o seu programa, o que nos garante flexibilidade suficiente.
Vamos fazer da área da janela principal uma tela onde possamos desenhar. Para isso, só precisamos fazer duas coisas em nosso programa: saber quando o mouse está com algum botão pressionado e desenhar quando ele estiver sendo "arrastado".
Saber o estado dos botões é trivial, podemos capturar isso nos eventos OnMouseDown e OnMouseUp e guardar em alguma variável.
//...
private:
bool mouseDown; // essa variável guarda o estado do mouse...
//...
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
mouseDown = false; // ... e é importante iniciá-la
}
void __fastcall TForm1::FormMouseUp(TObject *Sender, TMouseButton Button,
TShiftState Shift, int X, int Y)
{
mouseDown = false;
}
void __fastcall TForm1::FormMouseDown(TObject *Sender, TMouseButton Button,
TShiftState Shift, int X, int Y)
{
Canvas->PenPos = TPoint(X, Y); // mais tarde veremos o porquê disso
mouseDown = true;
}
Saber quando o mouse está sendo arrastado também é um passo trivial, uma vez que temos esse evento (OnMove) para tratar no controle da janela.
Para desenhar, todo formulário e mais alguns controles gráficos possuem um objeto chamado Canvas, do tipo TCanvas (duh). Essa classe representa uma superfície de desenho que você pode acessar a partir de seus métodos. Isso é a abstração do conhecido device context da GDI, tornando a programação mais fácil. O desenho de uma linha, por exemplo, é feito literalmente em uma linha de código.
void __fastcall TForm1::FormMouseMove(TObject *Sender, TShiftState Shift,
int X, int Y)
{
if( mouseDown )
{
Canvas->LineTo(X, Y);
}
}
O método LineTo() desenha uma linha do ponto onde está atualmente a caneta de desenho até a coordenada especificada. Esse é o motivo pelo qual no evento OnMouseDown alteramos a propriedade PenPos do Canvas para o ponto onde o usuário pressiona o botão do mouse.
Voila! Temos o nosso Personal PaintBrush, com toda a tosquisse que menos de 10 linhas de código podem fazer. OK, ele não é perfeito, admito, mas pode ser melhorado. Temos o código-fonte =).
Um dos problemas nele reflete o comportamento de gráficos em janelas no Windows. Seja o que for que tenhamos desenhado sobre uma janela, seu conteúdo é perdido ao ser sobrescrito por outra janela. Isso porque a memória de vídeo da área de trabalho é compartilhada entre todas as janelas do sistema (isso muda com o advento do "Avalon"). Precisamos, então, sempre repintar o que é feito durante a execução do programa.
Se precisamos repintar, logo precisamos saber tudo o que o usuário fez até então. Uma das técnicas mais baratas no quesito memória para salvar o estado gráfico de uma janela é guardar um histórico das operações realizadas sobre sua superfície e executá-las novamente ao repintar a janela. A GDI é rápida o bastante para que o custo de processamento não seja sentido na maioria dos casos. Para o nosso _Paint_, apenas um array de coordenadas origem-destino já dá conta do recado:
//...
private:
bool mouseDown; // essa variavel guarda o estado do mouse
std::vector<TRect> mouseHistory; // um TRect guarda duas posicoes XY
//...
// ...
{
if( mouseDown )
{
// guardando a pincelada para reproduzi-la depois
mouseHistory.push_back( TRect(Canvas->PenPos, TPoint(X, Y)) );
Canvas->LineTo(X, Y);
}
}
//...

[2007-10] [2007-12]