- Preconceito
- História do Windows - parte 4.0
- O passado torto de um programador por acaso
- Antidebug: Detectando Attach
- Guia básico de controle de código (Source Safe)
- Aquisição de recurso é inicialização
- Hook de COM no WinDbg
- A mobilidade das variáveis no printf
- Why is my DLL locked?
- Introdução ao C++ Builder...Turbo C++
- Developer: you need to know English!
# Preconceito
Caloni, 2007-09-01 <quotes> <self> <now> [up] [copy]Reduzir uma pessoa a um conceito já é uma forma de violência.
Tolle, Eckhart (O Poder do Agora, 1997)
# História do Windows - parte 4.0
Caloni, 2007-09-04 <computer> [up] [copy]Em meio a uma febre de consumismo, no dia 24 de agosto de 1995, foi lançado a revolução no sistema gráfico da Microsoft: a interface do Windows 95. Ela foi considerada muito mais amigável que suas versões anteriores. Ainda possuía a vantagem de não necessitar mais de uma instalação prévia do DOS, passou a suportar nomes de arquivos longos, incluir suporte a TCP/IP e dial-up networking integrados. Muitas mudanças foram feitas no sistema em si, como a passagem para 32 bits (como já vimos, parcial) e o novo conceito de threads, que é o que veremos com mais detalhes neste artigo.
Bem, o "novo conceito" de threads já havia sido implementado no Windows NT desde o seu rascunho e já existia no início do projeto, mas não no velho Windows 3.1 de 16 bits, que foi a versão anterior ao 95. Parte dos requisitos do sistema foi que ele seria compatível com o NT no nível de aplicativo, o que de fato aconteceu.
Para esse milagre da multiplicação das threads acontecer a Microsoft foi obrigada a portar boa parte do código de 16 bits para 32 e entrar em modo protegido. Mesmo assim, um legado razoável do MS-DOS permaneceu debaixo dos panos suportando o novo sistema operacional através de suas interrupções e código residente. Ou seja, havia ainda partes do SO rodando em modo real.
Com o lançamento da nova versão do NT foi necessário modernizar a interface para ser compatível com o Windows 95, o que fez com que o Windows 4.0 fosse mais bonitinho. No entanto, o núcleo dos dois sistemas era completamente diferente. Enquanto um era 32 bits puro desde o primeiro int main, o outro era um sistema de compatibilidade para fornecer um Windows caseiro que fosse vendável e desse à Microsoft o retorno financeiro esperado. Deu certo por um bom tempo, até a chegada do Windows XP, que uniu as duas famílias de sistemas operacionais, pois descontinuou o Windows ME e tornou o Windows 2000 Professional mais amigável para o uso geral.
E como funciona o sistema de threads? Uma thread é uma linha de execução de código. Ser um sistema multithreading significa que ele permite que múltiplas linhas de execução de código rodem em paralelo e, dependendo do número de processadores, ao mesmo tempo.
Porém, em uma plataforma com apenas um processador, como é natural supor, apenas uma thread roda de cada vez. Para dar a impressão de rodar ao mesmo tempo o tempo de execução das threads é dividido entre elas, de forma que aparentemente todas elas rodam ao mesmo tempo. Essa unidade de divisão do tempo de execução é conhecido como quantum, ou Time Slice, e é caracterizado como o tempo em que uma thread fica rodando até que outra thread tome o seu lugar, ou seja, ocorra uma troca de contexto (switch context). Quando uma thread é criada ela ganha seu primeiro time slice (se não iniciar suspensa) e divide o tempo de processamento com outras threads que executam no mesmo processador.
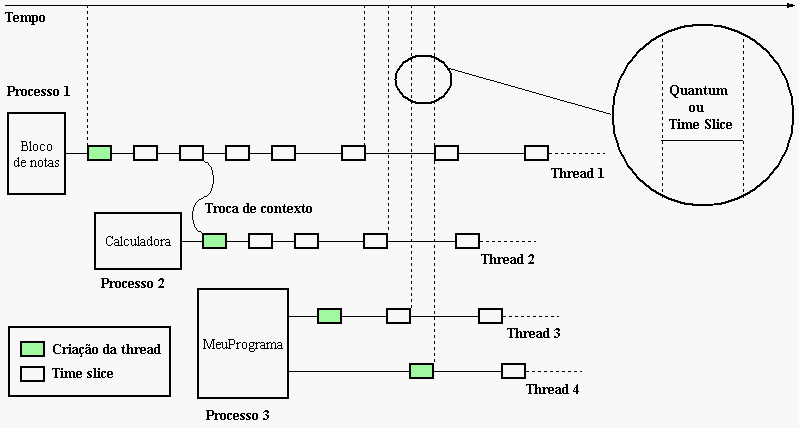
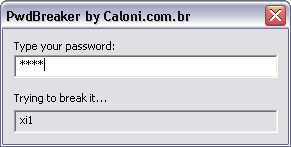
Para exemplificar o uso de threads imagine um programa que quebra senhas por força bruta. Funciona assim: enquanto uma thread fica cuidando das mensagens da janela, como digitação e movimentação do mouse e janela, uma segunda thread irá ficar constantemente tentanto descobrir sua senha digitada por tentativa e erro. Toda vez que é alterado um caractere na senha, a thread quebradora reinicia seu trabalho.
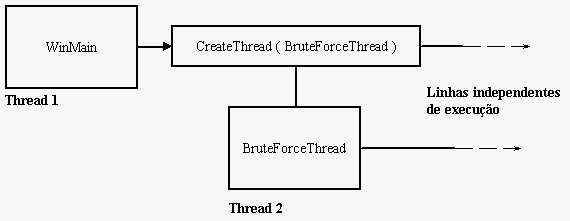
Todo programa inicia com uma thread que roda seu int main. A criação de uma nova thread é feita através da chamada da função API CreateThread.
void StartBruteForceThread()
{
g_bruteForceThread = CreateThread(NULL,
0,
BruteForceThread,
NULL,
0,
&g_bruteForceThreadId);
}
Para quem está acompanhando a série de artigos sobre o Windows deve lembrar que assim como na criação de janelas, na criação de uma thread é passada uma função de callback. Só que diferente de uma função de janela, essa função não é executada na mesma thread que criou a janela, mas é um novo "int main" para uma nova linha de execução, que irá rodar em paralelo com a primeira. Essa segunda linha de execução termina quando retornamos dessa função, que no nosso exemplo é nunca, mas poderia ser quando fosse terminada sua tarefa.
Bom, acho que para explicar o uso de um sistema multithreading em um artigo só não basta. Mas para explicar por que sua senha deve ter mais de três caracteres, acho que é o bastante. Até a próxima.
# O passado torto de um programador por acaso
Caloni, 2007-09-06 [up] [copy]Observação: este é um artigo não-técnico, o que quer dizer que você pode se deparar com termos desconhecidos. Procure ter à mão um dicionário de pessoas comuns.
Sabe aquele senso comum de que adolescente não sabe o que quer da vida? Pois é, naquela época eu não sabia mesmo. Quando iniciei minha vida queria ser desenhista. Então descobri que não conseguia desenhar sem uma régua, o que me levava a crer que seria engenheiro. Mas engenheiro de quê? Bom, como esse tipo de pergunta tem um nível de complexidade além dos limites de uma criança de 12 anos, decidi que decidiria isso na minha oitava série.
Então a oitava série chegou. Fascinado com o conceito de átomos e camadas de elétrons decidi que iria ser químico. Procurei e logo achei um curso técnico de química industrial para o segundo grau. Comecei a estudar para o chamado "vestibulinho", empolgado com a idéia de vir a trabalhar em uma fábrica usando jaleco.
Até aquele breve momento, tudo ia bem na mente daquele promissor químico de sucesso.
Até que num belo dia minha mãe aparece com um folheto onde, escrito em letras garrafais, conseguia-se ler com um pouco de esforço: "curso de computação". Computação é mexer com computadores. Até então só tinha visto computadores em filmes de ficção científica e nas bibliotecas da cidade (os velhos sistemas Unisys, ainda de pé na minha velha e boa São Bernardo).
Mexer com computadores (naquele folheto) até que parecia ser uma coisa legal.
E lá fui eu ficar algumas horas por semana sentado à frente daquela tela verde digitando comandos em inglês. Wordstar, Lotus 1-2-3 e o tal do MS-DOS. Havia um segundo laboratório na escola, este mais novo, onde repousava intocado um outro sistema operacional. Diziam ser revolucionário, e que vinha com um novo dispositivo futurístico conhecido como mouse (em Portugal chamavam de rato). Era uma pequena caixa com dois botões conectados à CPU por um fio (tecnicamente seu rabo). Mexemos uma única vez no final de nosso curso com o tal de Windows 3.1, o sistema operacional que vinha nesses micros novos. Foi apenas um rápido e impagável momento de test drive.
Mas, por um motivo que até hoje desconheço, gostei do tal do MS-DOS. Eu dava comandos para o computador e ele obedecia! Achei fascinante! Me diverti muito durante os três meses do curso.
E voltei a estudar para o vestibulinho de químico.
Porém, eis que chega o final de ano e pergunto para o meu amigo o que ele vai fazer.
-- "Processamento de Dados!" -- "Hummm... computadores." -- "Isso!"
Mas que coisa, hein. Balancei, balancei, e acabei mudando minha decisão do início do ano: iria tentar o curso de PD.
E foi assim. Fizemos o vestibulinho. Meu amigo não passou, mas a família dele tinha recursos, colocou ele em uma escola técnica particular. Eu também não passei. A nota de corte era 38. Tirei 37. Por um ponto fiquei sem opções de estudo. Então procurei por vagas em escolas técnicas. Minha mãe encontrou uma, onde existiam dois cursos: magistério e contabilidade.
-- "Magistério é legal. E se não for legal, pelo menos tem um monte de mulher."
Mas dessa vez meu lado numérico falou mais alto, e acabei ficando na sala mais chata. Prestei para contabilidade. Passei fácil.
E agora, após esse breve relapso, tudo estava em paz na mente daquele ~~contador~~ contabilista de futuro.
Dois anos se passaram. Balanços, balancetes, ativos e passivos. Mas nem tudo eram números. Tive uma professora de literatura que era ótima (no sentido bondoso da palavra). Ela me ensinou a ler estes livros não-técnicos que tanto encantam o pessoal de humanas. Também me ensinou a escrever de maneira não-vexatória, já prevendo naquela época que teria que me esforçar para ser um blogueiro de sucesso.
Naquela época comecei a escrever bastante. Gastei uns dez livros de 100 páginas rabiscando palavras. Desejava ser escritor, ficar rico e famoso e reponder às cartas dos fãs. Então lia e escrevia literatura. Quer dizer, eu acreditava que escrevia literatura. Um contador brincando de escritor.
O tempo passou, o ano final chegou e começava a despontar a grande dúvida: o que prestar no vestibular?
Naquele momento, meu lado letrado foi mais forte.
-- "Quero ser escritor, logo, vou fazer letras. Deve ser bem legal! Mas se não for bem legal, pelo menos tem um monte de mulher."
E comecei a estudar para o vestibular. Apenas um vestibular. Fuvest. Se não passasse ficaria a Deus dará. O que me importunava bastante àquela época da vida: depois de 13 anos de escola eu havia ficado um tanto condicionado a comparecer em sala de aula todos os dias de semana da minha vida.
Foi um período interessante. Matemática, Português, História, Geografia, Inglês, Química, Física, Biologia. Livros e mais livros viviam em minha mochila. Para minha sorte, meu emprego era de office-boy, o que me garantia por lei poder ler o dia inteiro, todos os dias, na fila do banco. Algumas noites também. E algumas madrugadas também. Foi um sufoco. Quase não termino meu curso.
Mas terminei. E passei. E de repente lá estava eu no antro da perdição, o início de tudo: FFLCH (lê-se "fefeléche"). E o subsolo era de fato um antro: xadrez, MPB, sebos, discussões filosóficas e muita fumaça. No meio das revoluções estratégicas do pessoal do CAELL eu me sentia extremamente "humanizado", seja lá o que isso for. E, sim, pela primeira vez na vida, milhares de mulheres interessantes passarelavam pelos corredores dos pensadores da palavra.
-- "Viva a linguística!"
Tudo estaria bem na cabeça daquele promissor "professor de português das escolas da rede pública de ensino" se não fosse o meu lado numérico.
Comprei um computador. E isso mudou minha vida. Cada vez mais a quantidade de livros de informática que eu carregava comigo ultrapassava o número de sonetos de Camões ou as prosas modernísticas de Guimarães Rosa que estudava no momento.
Desde aquele dia, o vício tem me acompanhado cronicamente, religiosamente, todo dia.
Larguei a faculdade. Comecei a me dedicar inteiramente aos livros sobre computadores, programação e "como as coisas funcionam". Quebrei algumas vezes meu computador. Metade delas eu mesmo consegui consertar.
Aprendi como o sistema funciona por dentro enquanto tentava encontrar mais e mais conteúdo com a chegada da internet. Era mágico. Conhecimento infinito! Como não amar uma coisa dessas?
Então descobri que ser hacker era algo muito bacana. E a linguagem que os hackers usam é a linguagem C. Então eu aprendi C, de cabo a rabo. Li o padrão. Sabia de cor algumas passagens. Virei um evangélico: "não atribuirás uma expressão não-const para um lvalue". No meio dos meus estudos tentava quebrar alguns programas. Metade eles eu consegui.
Entre internet, programação, pornografia online e os primeiros memes (em modo texto) encontro a usenet, grupos de news, e no meio deste um grupo de programadores C e C++. Começo a ler freneticamente as dúvidas das pessoas. Eu mesmo começo a responder várias destas dúvidas. Entre IRC e news vou criando uma identidade virtual.
No meio das inúmeras mensagens encontro uma proposta de emprego. Aquilo era algo meio alienígena para mim. "Eles vão me pagar pra eu ficar me divertindo o dia inteiro?". Sim, era isso mesmo. Havia empresas que pagavam um (bom) dinheiro para que resolvessem os problemas que eles precisavam serem resolvidos. Bastava ter uma curiosidade infinita e força de vontade de transformar o desconhecido em conhecimento. E aplicar.
Tremi nas bases nesse meu primeiro emprego. Foi a entrevista mais importante da minha vida. Felizmente conheci um old timer igualmente fascinado por tecnologia como eu. Naquele breve momento em que eu confessei meu amor pela linguagem C e por programação houve comunicação real. E eu fui contratado mesmo sem sequer ter pisado em uma faculdade nem trabalhado na área.
Na minha primeira semana o desafio era desenvolver uma DLL em C que servisse de callback para uma chamada específica do shell do Windows. E todo o conhecimento sobre o padrão da linguagem C não serviu de nada. Eu tive que aprender um monte de coisas novas na raça. E aquilo era empolgante. Continua sendo até hoje.
Depois de uns anos começo a escrever um blogue. E desde então o ser em que me transformei vos fala através daqui. E assim foi. Como é que o pessoal de humanas fala mesmo? Ah, sim: o resto é história.
# Antidebug: Detectando Attach
Caloni, 2007-09-10 <computer> <projects> antidebug> <closed [up] [copy]Hoje foi um belo dia para engenharia reversa e análise de proteções. Dois ótimos programas vieram ao meu conhecimento: um monitor de chamadas de API e um monitor de chamadas de COM (complementando o primeiro, que não monitora funções depois que CoCreateInstance foi chamado). Além de que no site do primeiro programa - de algum entusiasta do bom e velho Assembly Win32, diga-se de passagem - encontrei o código-fonte para mais uma técnica antidebugging, o que nos leva de volta para a já consagrada série de técnicas antidepuração.
O objetivo dessa proteção é detectar se, após o executável ter sido iniciado, algum depurador metido a besta tentou atachar-se no processo criado, ou seja, tentou iniciar o processo de depuração após o aplicativo já ter iniciada a execução. Isso é possível - de certa forma trivial - na maioria dos depuradores (se não todos), como o Visual Studio e o WinDbg. Diferente da técnica de ocupar a DebugPort, que impede a ação de attach, a proteção nesse caso não protege diretamente; apenas permite que o processo saiba do suposto ataque antes de entregar o controle ao processo depurador.
O código que eu encontrei nada mais faz do que se aproveitar de uma peculiaridade do processo de attach: ao disparar o evento, a função ntdll!DbgUiRemoteBreakin é chamada. Ora, se é chamada, é lá que devemos estar, certo? O código, então, insere um breakpoint hardcoded no início dessa função para capturar esse evento. Para compilar o código basta chamar o compilador seguido do linker, lembrando que precisamos da user32.lib linkada para chamar a função API MessageBox. Após o programa ter sido executado qualquer tentativa de attach irá exibir uma mensagem de detecção seguida pelo capotamento do programa.
Existem inúmeras maneiras de fazer a mesma coisa. O exemplo citado é o que é chamado comumente nas rodinhas de crackers de shellcode, que é um nome bonitinho para "array de bytes que na verdade é um assembly de um código que faz coisas interessantes". Shellcode for short =).
Maneiras alternativas de fazer isso são:
1. Declarar uma função _naked_ no Visual Studio, criar uma função vazia logo após e fazer continha de mais e menos para chegar ao tamanho que deve ser copiado.
2. Criar uma estrutura cujos membros são _opcodes_ disfarçados. Dessa forma é possível no construtor dessa estrutura preencher os valores corretamente e usá-la como uma "função móvel".
Ambas possuem prós e contras. Os contras estão relacionados com a dependência do ambiente. Na primeira alternativa é necessário configurar o projeto para desabilitar o "Edit and Continue", enquanto no segundo é necessário alinhar a estrutura em 1 byte.
Seja qual for a solução escolhida, ao menos temos a vantagem do impacto no sistema de nosso aplicativo ser praticamente nulo, pois isolamos em duas funções - AntiAttachAbort e InstallAntiAttach - um hook de uma API local (do próprio processo) que supostamente nunca deveria ser chamada em um binário de produção. Além do mais, existem maneiras mais a la C++ de fazer coisas como "live assembly". Mas isso já é matéria para futuros e excitantes artigos =D.
# Guia básico de controle de código (Source Safe)
Caloni, 2007-09-12 <computer> [up] [copy]O primeiro passo para se passar no Teste do Joel é possuir algum tipo de controle de código. E ele está mais do que certo. Não existe nada mais frustrante do que não ter exatamente o código-fonte da versão que está rodando no cliente ou não saber o que mudou desde que a versão foi entregue. Esse tipo de coisa pode acabar com uma empresa ou fazer com que ela fique muito mal vista no mercado.
Porém, independente do mercado, existe um bom motivo para o desenvolvedor possuir algum tipo de controle de código: controle. Se você ou sua equipe não conseguem corrigir todos os bugs, pelo menos saberão o que já foi feito. Se você achou um bug que não existia antes da versão 10, o histórico das mudanças entre a versão estável 9 e a versão não-tão-estável 10 vai te dar uma pista muito boa de onde o problema pode ter sido gerado. Visto dessa forma, não importa muito o tamanho da equipe ou da organização. O importante de um bom código é que suas mudanças estejam sempre registradas, visíveis e disponíveis a qualquer um.
Um controle de código para uma pessoa só não precisa ser nada muito sofisticado, sendo que um amontoado de ZIPs pode dar conta do recado. Porém, a partir do momento em que o número de desenvolvedores aumenta para dois ou mais, aí o controle baseado em ZIPs começa a ruir, e é necessário usar uma ferramenta mais apropriada. Existem algumas opções, que vai do gosto e necessidades de cada um:
- Visual Source Safe ou VSS não é gratuito nem robusto o suficiente para agüentar toneladas de código-fonte, mas vem junto do Visual Studio e pode ser apropriado para empresas de porte pequeno ou médio (e empresas de um programador só).
- Concurrent Version System ou CVS é um sistema fonte aberto, gratuito e robusto. Suficiente para agüentar toneladas de código-fonte e equipes de vários andares. Atualmente está sendo substituído gradualmente pelo
- Subversion ou SVN, um substituto moderno do antigo CVS; igualmente gratuito e poderoso, está rapidamente se tornando a opção predominante.
Vou explicar aqui os principais passos para começar a utilizar um controle de código usando como exemplo o Source Safe versão 2005 que, apesar de não ser gratuito, é muito usado em empresas que programam para Windows e já utilizam o Visual Studio há muito tempo.
Antes de qualquer coisa é necessário criar uma base de dados onde estarão os fontes. Para isso a primeira execução do programa irá exibir um assistente que irá guiá-lo pelos poucos e simples passos para a criação de uma nova base.
O processo é bem simples, baseado em Next, Next, até que você chega em momento de decisão, onde deve escolher qual dos dois métodos de controle de fonte irá utilizar:
- Lock-Modify-Unlock Model. O modelo clássico do Source Safe, permite que apenas um programador altere um fonte de cada vez. Se você é novo nesse negócio de controle de fonte, recomendo essa opção, que é a mais indolor. Em equipes pequenas costuma funcionar. E esse é o modelo que iremos utilizar aqui.
- Copy-Modify-Merge Model. Esse novo modelo segue o princípio do CVS e do Subversion. Nele todos podem alterar ao mesmo tempo qualquer código-fonte. Porém, na hora de subir as modificações de volta para a base é necessário um passo intermediário conhecido como merge. É onde são resolvidos conflitos, caso algum desenvolvedor tenha feito modificações no mesmo local que você. Geralmente é escolhida uma ou mais pessoas para gerenciar essa parte do processo. Esse modelo tem funcionado bastante em projetos de fonte aberto e de empresas grandes.
Agora que a base está criada, o próximo passo é torná-la disponível a todos. A maneira mais fácil de fazer isso é criando um compartilhamento na rede (de preferência oculto) e divulgando às pessoas interessadas. É claro que você, como bom administrador, irá ter que criar os usuários que irão acessar a base.
Após esse processo de integração, os usuários podem começar a usar o Source Safe através da primeira opção do início do assistente (Database Selection).
Antes de começar a mexer nos fontes, o Source Safe pede que você defina um diretório raiz onde começa a ramificação de pastas dos seus fontes. Isso pode ser feito pela opção File, Set Working Folder (Ctrl + D). A partir daí, cada pasta é chamada de projeto (project) no Source Safe. Para criar novos projetos/pastas, use a opção "File, Create Project". Para adicionar novos arquivos, "File, Add Files". Cada usuário pode definir seu próprio diretório de trabalho por máquina, mas geralmente é uma boa idéia mantê-los todos utilizando a mesma pasta.
Após adicionar os arquivos do projeto, é possível fazer modificações usando a opção check-out. O check-out quer dizer que os fontes saem (OUT) da base e são copiados com direito de escrita para seu disco local. Após feitas as modificações, usa-se a opção check-in para subir as modificações para o banco. O check-in quer dizer que as modificações feitas no disco local entram (IN) na base. Cada operação feita com esses dois passos é armazenada no histórico do Source Safe, e podem ser utilizadas para voltar versões antigas, comparar versões antigas novas, etc.
Quando todos os fontes que subirem constituirem uma alteração madura, compilável, testada pelo desenvolvedor e pronta para ser repassada para os testadores, deve-se criar um rótulo, ou label, para que futuramente essa versão possa ser facilmente identificada entre os milhões de modificações de fonte que sua equipe irá fazer ao longo do tempo. Se essa versão se tornar uma "entregável", pode-se utilizar o rótulo para obter exatamente a versão entregue a qualquer momento, independente de quantas modificações terem sido feitas depois. Essa marcação de fontes pode ser muito útil na ocorrência de incêndios, e todos sabemos que eles ocorrem com mais freqüência do que gostaríamos. Por isso é importante estar preparado.
Se você chegou até aqui, quer dizer que está realmente interessado em controlar seus fontes. Parabéns! O controle de fontes vem com algumas vantagens. Vamos supor que já exista uma versão estável no Source Safe e você precisa fazer alguma correção/teste como prova de conceito. Esse tipo de fonte normalmente seria descartável, mas agora que você possui uma ferramenta de controle de fonte funcionando, isso não é necessário.
Se é necessário desenvolver uma prova de conceito, pode-se optar por criar uma ramificação do fonte, ou branch. Essa opção cria um novo projeto no Source Safe com fontes existentes, mantém o histórico de modificações, mas gera uma nova linha de vida do fonte. Qualquer modificação feita em um branch fica nesse branch, seja o principal ou secundário. É possível também no futuro juntar dois branchs.
Agora, se a modificação é um simples teste durante a depuração, pode ser feito o check-out para modificações temporárias. Se mais tarde for decidido que as modificações não serão efetuadas na base, basta executar a opção undo check-out, que volta o fonte da base para o disco local e mantém a versão intacta. Use essa opção com cuidado, pois quaisquer modificações no disco local serão perdidas.
Agora que os fontes estão vivendo tranqüilamente no controle de fontes, é possível executar builds automatizados de tempos em tempos. Isso garante a estabilidade do seu projeto, pois junto dos builds é possível fazer testes, tanto da compilação em si quanto depois de compilado.
O Source Safe possui uma ferramenta em linha de comando que faz as mesmas operações que a versão gráfica, além de possuir uma série de interfaces COM que podem ser usadas para interagir com o controle de fontes através de scripts. Além de outras ferramentas de automação de builds que podem ser integradas, como o NAnt e o CruiseControl.
O resumo da ópera é: cuide bem dos seus fontes. Muito trabalho, tempo e dinheiro são despendidos com desenvolvimento. Não cuidar do resultado de tudo isso é como botar fogo no estoque de uma fábrica.
# Aquisição de recurso é inicialização
Caloni, 2007-09-14 <computer> <ccpp> [up] [copy]O título desse artigo é uma técnica presente no paradigma da programação em C++, razão pela qual não temos o operador finally. A idéia por trás dessa técnica é conseguirmos usar recursos representados por objetos locais de maneira que ao final da função esses objetos sejam destruídos e, junto com eles, os recursos que foram alocados. Podemos chamar de recursos aquele arquivo que necessita ser aberto para escrita, o bitmap que é exibido na tela, o ponteiro de uma interface COM, etc. O nosso exemplo é sobre arquivos:
#include <stdio.h>
class File
{
public:
File(char* name)
{
m_file = fopen(name, "r");
}
~File()
{
fclose(m_file);
}
FILE* m_file;
};
int UseFile()
{
File config("config.txt");
// using config.txt
return 0; // config.m_file released
}
Ignorei tratamento de erros e a dor de cabeça que é a discussão sobre inicializações dentro do construtor, matéria para um outro artigo. Fora os detalhes, o que temos é (1) uma classe que se preocupa em alocar os recursos que necessita e no seu fim desalocá-los, (2) uma função que usa um objeto dessa classe, alegremente apenas preocupada em usar e abusar do objeto. A demonstração da técnica reside no fato que a função não se preocupa em desalocar os recursos alocados pelo objeto config. Algo óbvio, desejável e esperado.
Para vislumbrarmos melhor a utilidade dessa técnica convém lidarmos com as famigeradas exceções. A possibilidade de nossa função ou alguma função chamada por essa lançar uma exceção enquanto nosso objeto está ainda construído -- e com o recurso alocado -- faz com que seja vital a classe do objeto ter sido bem construída a ponto de prever essa situação e liberar os recursos no destrutor. Daí o uso da técnica se torna necessário.
Por outro lado, ao usarmos objetos, devemos ter plena confiança nas suas capacidades de gerenciar os recursos que foram por eles alocados. Só assim se tem liberdade o suficiente para nos concentrarmos no código da função e solenemente ignorarmos a implementação da classe que estamos utilizando. Afinal, temos que considerar que muitas vezes o código-fonte não está disponível. Veja a mesma função com uma chance de desvio incondicional (o lançamento de uma exceção):
void BlowUpFunction()
{
// things aren't that good, so...
throw Scatadush();
}
int UseFileEx()
{
File config("config.txt");
BlowUpFunction(); // exception thrown:
// config.m_file is
// automagically released
return 0;
}
Nesse exemplo tudo funciona, certo? Até se a exceção for lançada, o recurso será desalocado, pois o objeto é destruído. Isso ilustra como várias técnicas de C++ podem conviver harmoniosamente. Mais que isso, se ajudam mutuamente. O que seria das exceções se não existissem os construtores e destrutores? Da mesma forma, os recursos são alocados e desalocados baseado na premissa de construção e destruição de objetos. Por sua vez, essa premissa vale em qualquer situação, existindo ou não exceções.
Agora, e se a exceção de BlowUpFunction é lançada e a classe File não está preparada para fechar o arquivo no destrutor? Esse é o caso da versão 2 de nossa classe File, logo abaixo. Apesar de ser a segunda versão ela foi piorada (acontece nas melhores famílias e classes):
class File2
{
public:
void Open(char* name)
{
m_file = fopen(name, "r");
}
void Close()
{
fclose(m_file);
}
FILE* m_file;
};
int UseFile2()
{
File2 config;
config.Open("config.txt");
BlowUpFunction(); // exception thrown:
// the resource was
// NOT released
config.Close(); // resource released
return 0;
}
Nesse caso o código de UseFile2 acaba deixando um recurso alocado por conta de uma exceção que ocorreu em uma função secundária chamada lá pelas tantas em um momento delicado demais para ocorrerem exceções. Note que o destrutor de File2 é chamado assim como o de File, só que este não libera os recursos do objeto. Ele não usa a técnica RAII (Resource Acquisition Is Initialization, ou o título do artigo em inglês).
Nesse tipo de classe o convívio com exceções gera um dilema: onde está o erro? Como consertá-lo? Se o problema é encontrado numa hora apertada e temos cinco minutos para revolver isso, capturar a exceção causada por BlowUpFunction é uma boa idéia. Só que nem sempre as soluções de cinco minutos são as mais maduras. Podemos não saber muito bem o que fazer com esse tipo de exceção, por exemplo. Isso geraria um tratamento de erro ou redundante se tratarmos ali mesmo o Scatadush, já tratado em um escopo mais externo, ou fragmentado se apenas desalocarmos o recurso de File2 e relançarmos a exceção. Eu nem diria fragmentado, pois estamos tratando um erro inventado, se considerarmos que é função dos objetos desalocarem os recursos que foram por eles mesmos alocados.
A opção que dura mais de cinco minutos pode evitar futuras dores de cabeça: arregaçar as mangas e refazer a classe File2 observando o princípio de RAII. Possivelmente algo na interface deverá ser alterado, o que causará a alteração de mais códigos-fonte que utilizam essa classe. Alterar mais códigos-fonte significa testar novamente mais partes do software, algumas nem de perto relacionadas com o problema em si. Ou seja, não é cômodo, mas é íntegro. Sabendo que futuras funções que usarem essa classe já estarão corretas, mesmo que uma exceção seja lançada e não seja capturada, é um dado significativo: representa produtividade futura.
A decisão sobre qual solução é a melhor está muito além do escopo desse artigo, pois obviamente cada caso é um caso. Mas não custa nada pensar um pouco sobre C++ quando se estiver programando. E "aquisição de recurso é inicialização" faz parte do modo de pensar dessa linguagem.
# Hook de COM no WinDbg
Caloni, 2007-09-18 <computer> [up] [copy]Continuando com o tema hooks no WinDbg vamos aqui "hookear" e analisar as chamadas de métodos de um objeto COM. O que será feito aqui é o mesmo experimento feito para uma palestra de engenharia reversa que apresentei há um tempo atrás, mas com as opções de pause, rewind, replay e câmera lenta habilitadas.
Antes de começar, se você não sabe nada sobre COM, não deveria estar aqui, mas nunca é tarde para aprender. Pra começar, vamos dar uma olhada na representação da interface IUnknown em UML e em memória:
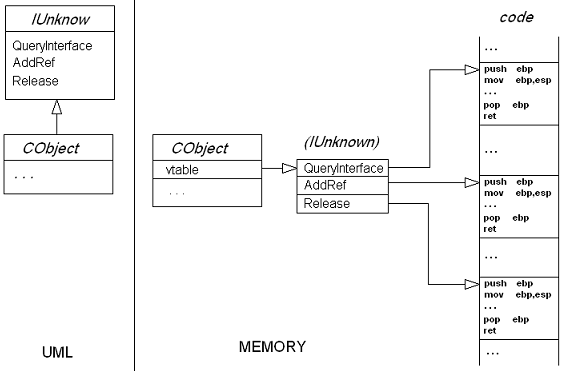
Como podemos ver, para implementar o polimorfismo os endereços das funções virtuais de uma classe são colocados em uma tabela, a chamada vtable, famosa tanto no COM quanto no C++. Existe uma tabela para cada classe-base polimórfica, e não para cada objeto. Se fosse para cada objeto não faria sentido deixar esses endereços "do lado de fora" do leiaute. E não seria nada simples e elegante fazer uma cópia desse objeto.
Assim, quando você chama uma função virtual de um objeto o código em assembly irá chamar o endereço que estiver na posição correspondente ao método chamado dentro da vtable. Se você chama AddRef, por exemplo, que é o segundo método na tabela, será chamado o endereço da posição número dois. Com isso, mesmo desconhecendo de que tipo é o objeto a função certa será chamada porque existe um ponteiro para essa tabela no início da interface.
Sabendo de tudo isso, agora sabemos como teoricamente proceder para colocar uns breakpoints nessas chamadas:
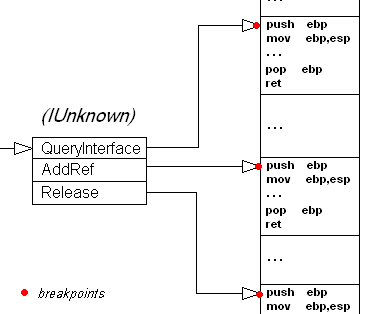
Note que o breakpoint não é colocado dentro da tabela, o que seria absurdo. Uma tabela são dados e dados geralmente não são executados (eu disse geralmente). Porém, usamos a tabela para saber onde está o começo da função para daí colocar a parada nesse endereço, que por fazer parte do código da função é (quem diria!) executado.
Agora vamos sair da teoria e tentar fazer as coisas mais ou menos parecidas na prática. O nosso sorteado desse artigo foi o IMalloc, a interface de alocação de memória do COM, que existe desde a época em que não se sabia direito pra que esse tal de COM iria servir. O IMalloc é definido como se segue:
MIDL_INTERFACE("00000002-0000-0000-C000-000000000046")
IMalloc : public IUnknown
{
public:
virtual void *STDMETHODCALLTYPE Alloc(
/* [in] */ SIZE_T cb) = 0;
virtual void *STDMETHODCALLTYPE Realloc(
/* [in] */ void *pv,
/* [in] */ SIZE_T cb) = 0;
virtual void STDMETHODCALLTYPE Free(
/* [in] */ void *pv) = 0;
virtual SIZE_T STDMETHODCALLTYPE GetSize(
/* [in] */ void *pv) = 0;
virtual int STDMETHODCALLTYPE DidAlloc(
void *pv) = 0;
virtual void STDMETHODCALLTYPE HeapMinimize(void) = 0;
};
Nesse experimento, como iremos interceptar quando alguém aloca ou desaloca memória, nossos alvos são os métodos Alloc e Free. Para saber onde eles estão na tabela, é só contar, começando pelos métodos do IUnknown, que é de quem o IMalloc deriva. Se houvessem mais derivações teríamos que contar da primeira interface até a última. Portanto: QueryInterface um, AddRef dois, Release três, Alloc quatro, Realloc cinco, Free seis. OK. Contar foi a parte mais fácil.
Agora iremos precisar interceptar primeiro a função que irá retornar essa interface, pois do contrário não saberemos onde fica a vtable. Nesse caso, a função é a ole32!CoGetMalloc. Muitas vezes você irá usar a ole32!CoCreateInstance(Ex) ou a CoGetClassObject diretamente na DLL que pretende interceptar. Outras vezes, você receberá o ponteiro em alguma ocasião diversa. O importante é conseguir o ponteiro de alguma forma.
Nesse exemplo iremos obter o ponteiro através de um aplicativo de teste trivial, ignorando todas aquelas proteções antidebugging que podem estar presentes no momento da reversa, feitos por alguém que lê meu blog (quanta pretensão!):
/** @brief A stupid sample to
show WinDbg COM hooking! */
#include <windows.h>
#include <objbase.h>
#include <objidl.h>
int main()
{
CoInitialize(NULL);
IMalloc* malloc = 0;
if( CoGetMalloc(1, &malloc) == 0 )
{
if( void* pAlloc
= malloc->Alloc(0x1000) )
{
malloc->Free(pAlloc);
}
malloc->Release();
}
CoUninitialize();
}
Vamos fazer de conta que é desnecessário dizer como se compila o fonte acima.
cl /c imalloc-hook.cpp link imalloc-hook.obj ole32.lib
Agora é só depurar!
Abra o WinDbg. Na opção "File, Open Executable" selecionamos a nossa vítima, cujo nome você escolhe na hora de compilar o fonte acima. Aqui ele irá chamar imalloc-hook.exe. A seguir, colocamos um breakpoint na função da ole32, mandamos rodar, e esperamos a parada do código:
0:000> bp ole32!CoGetMalloc 0:000> bl 0 e 774ddcf8 0001 (0001) 0:**** ole32!CoGetMalloc 0:000> g Breakpoint 0 hit ModLoad: 76360000 7637d000 C:WINDOWSsystem32IMM32.DLL ... ModLoad: 746e0000 7472b000 C:WINDOWSsystem32MSCTF.dll eax=0012ff7c ebx=00000000 ecx=775e67f0 edx=775e67f0 esi=00000001 edi=00403374 eip=774ddcf8 esp=0012ff70 ebp=0012ffc0 iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 ole32!CoGetMalloc: 774ddcf8 8bff mov edi,edi
Maravilha. Alguém chamou a função que queríamos (quem será?). Agora podemos dar uma olhada na pilha e no protótipo da CoGetMalloc:
HRESULT CoGetMalloc(DWORD dwMemContext, LPMALLOC *ppMalloc); 0:000> dd esp L3 0012ff70 0040101d 00000001 0012ff7c 0:000> dd poi(esp+8) L1 0012ff7c 00000000
Como podemos ver nos parâmetros da pilha o nosso chamador passou certinho o valor 1 no campo reservado e um ponteiro no segundo parâmetro para uma área onde, se der tudo certo, será escrito o endereço de um IMalloc, que podemos chamar carinhosamente de this. De início vemos que a variável está zerada. Agora vamos executar a função até a saída e examinar os resultados.
0:000> bp /1 /c @$csp @$ra;g Breakpoint 1 hit eax=00000000 ebx=00000000 ecx=775e6034 edx=775e67f0 esi=00000001 edi=00403374 eip=0040101d esp=0012ff7c ebp=0012ffc0 iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 IMalloc+0x101d: 0040101d 85c0 test eax,eax 0:000> dd 0012ff7c L1 ; o endereço da variável 0012ff7c 775e6034 ; o endereço da interface 0:000> dd 775e6034 L1 ; onde está a vtable? 775e6034 775e600c ; o endereço da vtable 0:000> dd 775e600c 775e600c 77562cfb 774dcf29 774dcf29 774dd00d ; a vtable ! ! ! 775e601c 774dd665 774dcfe8 774dd400 77562d46 ; a vtable ! ! ! 775e602c 77562d6e 775e6034 775e600c 774c0000 ; a vtable ! ! ! 775e603c 00000000 00000000 00154d70 774cbff4 775e604c 00000000 00000000 00000000 00000000 ...
E não é que tudo deu certo? A variável foi preenchida, e partir dela demos uma espiadela nos endereços das funções da vtable. Nós pegamos o valor da variável que foi preenchida (o endereço da interface) e obtemos os seus primeiros 4 bytes (o endereço da vtable) e listamos o seu conteúdo (a própria vtable!). Agora basta usarmos o resultados de nossas contagens lá em cima e colocarmos os breakpoints nas funções corretas. E mandar rodar. E analisar os resultados.
0:000> bp 774dd00d ".echo IMalloc::Alloc" 0:000> bp 774dcfe8 ".echo IMalloc::Free" 0:000> g IMalloc::Alloc eax=775e6034 ebx=00000000 ecx=775e600c edx=774dd00d esi=00000001 edi=00403374 eip=774dd00d esp=0012ff70 ebp=0012ffc0 iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 ole32!IsValidIid+0xe4: 774dd00d 8bff mov edi,edi 0:000> dd esp L3 0012ff70 <strong>00401031 775e6034 00001000</strong> ; o this é nosso, e foi pedido para alocar 4KB (0x1000) 0:000> bp /1 /c @$csp @$ra;g ; Step Out para pegar o retorno Breakpoint 3 hit eax=001597f0 ebx=00000000 ecx=7c9106eb edx=00150608 esi=00000001 edi=00403374 eip=00401031 esp=0012ff7c ebp=0012ffc0 iopl=0 nv up ei pl nz na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206 IMalloc+0x1031: 00401031 85c0 test eax,eax 0:000> reax eax=001597f0 ; esse é o endereço da memória alocada g IMalloc::Free eax=774dcfe8 ebx=00000000 ecx=775e6034 edx=775e600c esi=00000001 edi=00403374 eip=774dcfe8 esp=0012ff70 ebp=0012ffc0 iopl=0 nv up ei pl nz na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206 ole32!IsValidIid+0xbf: 774dcfe8 8bff mov edi,edi 0:000> dd esp L3 0012ff70 <strong>00401041 775e6034 001597f0</strong> ; nosso this e endereço alocado (pedindo pra desalocar) g ; é isso aí
Note que a função pode eventualmente ser chamada internamente (pelo próprio objeto) ou até por outro objeto que não estamos interessados em interceptar (lembre-se que os métodos de uma classe são compartilhados por todos os objetos). Por isso é importante sempre dar uma olhada no primeiro parâmetro, que é o this que obtemos primeiramente.
Com isso termina o nosso pequeno experimento de como é possível interceptar chamadas COM simplesmente contando e usando o WinDbg. OK, talvez um pouquinho a mais, mas nada de quebrar a cabeça.
# A mobilidade das variáveis no printf
Caloni, 2007-09-20 <computer> <ccpp> [up] [copy]O printf (e derivados) tem sérios problemas por conta de sua falta de tipagem. Não vou aqui dizer que cout é a alternativa óbvia e melhorada porque não é. Mas isso é uma discussão que eu não deveria começar aqui. E não começarei. Portanto, ignorem essa linha =).
O erro mais comum de todos é a passagem de tipo na string de formatação diferente da variável passada:
void f(wchar_t* arg)
{
printf("%s", arg);
return 0;
}
Isso costuma ser mais comum quando existem centenas de milhares de parâmetros na chamada, o que confunde o programador (e o leitor de certos blogues especializados em confundir). Imagine um printf em que a string de formatação é algo como "%s%d%s%f%s%d%f%d%s%f%s%d". Agora imagine os parâmetros passados e a necessidade dos tipos baterem um a um. É, você entendeu o drama.
O segundo erro que me lembro que costuma dar muitos problemas é a passagem de tipo inteiro de tamanho diferente:
char ch = getc();
printf("%d", ch);
É mais sutil, também costuma confundir no meio de vários parâmetros, e pode ser detectado utilizando a técnica de transformar tudo em assembly, pois com isso temos dica de tipagem ao empilhar os argumentos na saída do arquivo asm. É claro que hoje em dia existem compiladores muito espertos, que detectam na hora o que você está digitando e a cagada que isso vai dar depois de compilado. Mas, assumindo que você não tem toda essa tecnologia ao seu dispor, ou está mesmo interessado em entender como as coisas funcionam, e não apenas seguir o manual do seu ambiente de desenvolvimento preferido, essa é uma maneira interessante de analisar o que ocorre com o seu código. Agora, a pergunta que não quer calar: por que isso acontece?
Funções com quantidade variável de argumentos como o printf devem interpretar os argumentos que ele sabe que são passados para entender quais os outros argumentos que estão na pilha. Ele interpreta a string de formatação e vai "comendo" os argumentos passados na pilha. Se a string informa que existe um int de 32 bits, mas na verdade existe um de 64, ele vai comer apenas 32 bits da pilha, deixando os próximos 32 para o desastre iminente.
Dica: se você encontrar problemas de crash ou corrompimento de pilha e houver um printf ou derivados, como funções de logs que confiam no printf, experimente desabilitar a chamada dessas funções e ver se o problema permanece. Isso pode ser feito pelo preprocessador:
#define printf #define sprintf #define LOG
Ao definir os nomes das funções usadas para nada não haverá a chamada da função, apesar do código compilar exatamente igual, exceto a chamada. Ou seja, se houver problemas em algum printf ele sumirá. A partir daí é só ir comentando e descomentando as partes do código até encontrar.
# Why is my DLL locked?
Caloni, 2007-09-24 <computer> <english> [up] [copy]The Windows code responsible to call DllMain for each loaded and unloaded DLLs uses an exclusive access object, the so-called mutex, to synchronize its calls. The result is that inside a process just one DllMain can be called at a given moment. This object-mutex is called "loader lock" into the Microsoft documentation.
I wrote a silly code that represents quite well what I've seen in lots of production code. For many times I was unable to realize what was going on (whether because I didn't know about the loader lock or the code readability was too bad). The code say by itself: calling CreateThread inside DllMain must lock your execution forever.
A simple victim of all this can be an executable using a poorly written DLL, just like the code above:
int main()
{
printf("load dll");
HMODULE lockDll = LoadLibrary(_T("dll_lock.dll"));
if( lockDll )
{
Sleep(2000);
printf("free dll");
FreeLibrary(lockDll), lockDll = NULL;
printf("done");
}
}
It is important to remember that a DllMain dependant code is a very, very bad thing. Nevertheless, there are some particular cases the only place to run our code is inside DllMain. In these cases, when detected, try to run a side by side communication with your locked thread using an event object (or equivalent) before it really returns. Using this craft the thread can warn the waiting thread that the important thing to be done is done, and the waiting thread can go to sleep and stop waiting forever locked threads.
Among the classic Matt Pietrek posts in Microsoft Journal there is in the 1999 september edition a short one about DLL initialization. That is the more sucint, didatic and simple text about this question.
# Introdução ao C++ Builder...Turbo C++
Caloni, 2007-09-26 <computer> cppbuilder> [up] [copy]Após mais de um ano de tentativas, finalmente consegui instalar e iniciar com sucesso o Borland Developer Studio. Esse foi o nome pomposo dado pela Borland para a "continuação" do velho C++ Builder e seus parentes, o Delphi e o C# Builder.
Existem muitas coisas novas ainda para ver, mas não é a usabilidade. Assim como a IDE antiga, é fácil de sair mexendo e fazendo janelas, no bom estilo WYSIWYG dos produtos da Borland.
Para quem começa a desenvolver aplicativos com interface para Windows, deve saber que uma das coisas mais produtivas que já inventaram foi o Visual Basic. De fato, o VB permite que virtualmente qualquer pessoa com conhecimentos mínimos de informática torne-se um gabaritado programador de telinhas.
Porém, com o tempo você percebe que cada ferramenta tem suas vantagens e desvantagens. Uma desvantagem do VB era a falta de flexibilidade. Outra era que a linguagem usada não favorecia muito aqueles que se aventuravam chamando a Win32 API diretamente dos seus programas. Era possível, sim, mas enfadonho e nem sempre as coisas funcionavam como o esperado.
Para as pessoas que chegam nesse nível de necessidade, existem basicamente duas escolhas:
1. Permanecer no mundo Microsoft e usar MFC + Win32 API, passando a programar na linguagem em que foi feito o Windows (C/C++).
2. Tentar usar o Delphi, a evolução do Turbo Pascal para Windows, da Borland, que pode ser considerado mais flexível que o VB, mas ainda assim usa uma linguagem alienígena (no sentido de que ainda não é a linguagem nativa do SO).
3. Mudar de sistema operacional e esquecer esse negócio de loop de mensagens (eu disse duas escolhas, certo?)
Bom, eis que surge o C++ Builder: uma ferramenta idêntica ao Delphi, contudo que oferece a linguagem C++ para que todas aquelas pessoas recém-saídas da faculdade e ansiosas por entrar no mercado de trabalho esqueçam aquele papo de Pascal e passem a usar a linguagem da indústria. Pelo jeito, era mais ou menos essa a visão da Borland quando lançaram o produto.
Desde o princípio, o C++ Builder foi lançado em revistas de informática em versões para estudantes, o que estimulava as pessoas financeiramente menos capacitadas (estudantes, como eu) a cada vez mais utilizar essa ferramenta de programação para desenvolver aplicativos Windows, já que, além de não ser pago como o Visual Basic e o Visual C++, não era nem tão limitado quando o primeiro nem tão complicado quanto o segundo. E estava sempre entre os programas completos para serem testados na revista que acabou de chegar na banca. Nossa, como era divertido programar por prazer!
O mais impressionante no Builder era que desde o começo, na versão 1, já tínhamos aquela palheta maravilhosa cheio de todos os controles que já faziam parte do Windows 95. Tudo isso por causa de uma estratégia simples e eficaz: os componentes são os mesmos do Delphi. O que o C++ Builder adicionou foi uma camada de interface para que C++ e Object Pascal conversassem. O resultado disso é espantoso: é possível programar em C++ puro, chamar APIs diretamente, e ainda usar os componentes em Delphi, além de também poder desenvolver em Delphi e mesclar ambas as linguagens em um projeto. É possível até usar herança entre componentes escritos em Delphi e C++ Builder.
Quando entrei na Scua comecei a trabalhar profissionalmente com o C++ Builder, ao desenvolver o aplicativo de administração do software de controle de acesso. Na época não tínhamos muito tempo para perder desenvolvendo tudo em Win32 API ou usar algo mais rústico como a MFC, que é mais parecido com a finada biblioteca OWL do que com a VCL (a biblioteca visual de componentes usada pela Borland para Delphi e Builder). E não, usar Visual Basic não era uma alternativa. Como a produtividade estava em jogo, hoje tenho certeza que fizemos uma boa escolha.
Eu gostava do C++ Builder antigo: sem frescura de registrar componentes e sem necessidade de instalação. Até hoje uso a versão 1.0 para brincar de vez em quando, pois é relativamente pequena; apenas copio para uma pasta e ainda funciona muito bem.
Mas desde que o mundo gerenciado veio à tona, para instalar esse singelo produto da Borland você vai precisar de alguns pré-requisitos da Microsoft:
1. Microsoft .NET Framework SDK 1.1
2. Visual J# .NET Redistributable Package 1.1
3. Microsoft XML 4.0 SP2 Parser and SDK
Se for necessária mais alguma instalação, não se preocupe: o Borland Turbo C++ Instalation Wizard irá te avisar no momento da instalação, que deverá ser a última a ser realizada.
Após tudo isso instalado, finalmente conseguiremos rodar nossa ferramenta RAD. Aliás, antes que eu me esqueça, RAD é uma abreviação para Rapid Application Development.
Se você nunca usou essa ferramenta, ao abrir o ambiente, irá se deparar com vários elementos que precisam ser nomeados e explicados para fazer algum sentido. Mesmo que muitas coisas sejam novas, algumas devem estar sempre gravadas em sua memória:
Sempre que você clicar em algum componente gráfico para ser editado - como uma janela, um botão, uma lista - o Object Inspector será o lugar para editá-lo. Ele está dividido em propriedades e eventos. Propriedades são as características gráficas e comportamentais do componente que está sendo editado. Eventos especificam métodos para tratar as ações recebidas de algum componente (ex: clique de um botão).
A palheta é onde estão todos os componentes que podem ser usados no momento para a edição do programa. Existe uma infinidade deles, tais como: botões, menus, caixas de seleção, listas de itens, barras de rolagem, listas de ações, imagens, rótulos, grupos de botões, e assim vai a valsa. Para usá-los, basta arrastar para uma janela e editar suas propriedades.
Onde estão todos os meus arquivos? O Gerenciador de Projetos está aí para ajudá-lo. Todas as units (unidades de código) e forms (janelas) que você criar no projeto estará visível para fácil acesso. É muito importante saber organizar um projeto, pois conforme se avança, ele tende a se tornar maior e mais complexo. Junto do Gerenciador de Projetos existe o seu ajudante, o Structure. Na visão de design, o Structure irá mostrar os controles inseridos nas janelas; na visão de unit, o Structure irá mostrar os includes, macros, classes e funções do código-fonte exibido no momento.
Update: este foi um overview geral por cima do que era o C++ Builder há mais de dez anos. Não consegui validar um projeto antigo na IDE porque as ferramentas da Borland seguiram por caminhos muito tortos e a versão mais nova (que instalei) não conseguiu importar. De qualquer forma, fica o post legado.
# Developer: you need to know English!
Caloni, 2007-09-28 [up] [copy]Eu realmente gostei desse negócio de tagging. =)
Aproveitando o comentário do Ferdinando sobre o novo sistema de tradução eletrônica do MSDN, lanço aqui algumas dicas para aprender a tão falada língua de Shakespeare. Acredite, se você deseja ser um melhor programador, inglês é fundamental.
O aprendizado de qualquer idioma deve estar focado em um objetivo. Se o objetivo é se comunicar, conversação é importante. Se você deseja ser um business man, um vocabulário mais específico deve ser aprendido. No nosso caso, em que a santa leitura técnica de cada dia é a necessidade básica, alguns passos básicos em inglês instrumental é um ótimo começo para começar a desvendar 80% da internet.
Note, contudo, que inglês instrumental não é muito bem visto por escolas conceituadas de idiomas, tanto por ensinar um inglês limitado quanto por criar vícios de linguagem. O importante a lembrar nesse caso é: estamos usando o inglês como uma ferramenta de compreensão de textos que são úteis para nosso trabalho. Se o interesse/necessidade do inglês for maior, deve-se passar para as próximas dicas.
Seguem alguns primeiros passos para começar a se aventurar:
- Procure estudar as palavras mais faladas no idioma.
- Aprenda as regrinhas para saber 400 palavras de lambuja.
- Use e abuse dos prefixos e sufixos de ambos os idiomas, pois geralmente seguem as mesmas regras.
- Mantenha um dicionário de expressões mais comuns nos textos que você lê. Aprenda-as.
Como todo bom aprendizado, a parte mais importante é a prática. E nada melhor para praticar do que ler pra caramba, certo? Isso quer dizer que você terá algumas tarefas diárias a partir de agora:
- Compre um dicionário inglês-português dos mais simples, seja o tradicional ou o eletrônico. Se não tiver dinheiro nem para isso, então use os disponíveis na internet.
- Escolha um artigo ou notícia e leia-o em um só dia. Para não desanimar, recomendo que seja relativamente curto e seja de um tema que muito te interesse. Pode até ser uma notícia curta do Slashdot.
- No começo tente traduzir um ou dois parágrafos desse mesmo artigo. Com o tempo, aumente o número de parágrafos até conseguir traduzir o texto inteiro.
Se sua necessidade do inglês era apenas ler textos técnicos pode parar por aqui. Mas nem sempre o conteúdo está escrito. Pode ser que existam palestras interessantíssimas do Channel9 ou podcasts de informática que você simplesmente não pode perder. Nesse caso, não há uma dica melhor do que imitar as crianças quando aprendem suas línguas nativas: ouça pessoas falando em inglês.
Isso, aliada à sua prática diária de leitura de artigos, pode ser complementada se prestar atenção sempre na pronúncia correta das palavras que vai aprendendo. Muitas pessoas se tornam exímias leitoras de textos em inglês, mas não conseguem entender uma frase comum do dia-a-dia. Isso ocorre porque o inglês escrito difere em muito das regras de pronúncia do português escrito, o que gera muita confusão na hora de falar o fonem lido. Felizmente, na maioria dos dicionários existe sempre a transcrição fonética no início de cada vocábulo. É importante usá-la, e pelo menos uma vez você mesmo tentar pronunciar a palavra de sua boca.
Nesse momento, o importante é fazer a transição escrito-falado. Por isso, tente ouvir podcasts em que o texto falado está disponível para leitura. Dessa forma é possível acompanhar os dois. Eu costumava ouvir o Word for the Wise da Merriam-Webster, por ser curto e interessante. Mas o ideal é unir o útil ao agradável, e nisso com certeza um podcast de tecnologia seria muito melhor.
Trapaceando: no começo, é comum haver divergências de pronúncia ou falta da capacidade de ouvir (listening). Você pode sempre apelar para as pronúncias disponíveis nos dicionários online, como o Merriam-Webster. Ouça um milhão de vezes para pegar o jeito.
Depois de obter um feeling básico sobre o que é escrito e o que é falado pode-se partir para estudos mais ousados e voltados para o aprendizado da língua de fato. Sabendo da facilidade que já obtivemos em traduzir textos e ouvir, considero as tarefas abaixo ideais para chegarmos ao tão sonhado language aquisition:
- Ouvir música em inglês e ler a letra (original e traduzida). Uma boa banda para começar são os Beatles, cujo inglês britânico é fácil de entender.
- Assistir filmes em inglês com legenda (traduzida e original). Você pode começar com as comédias românticas que são lançadas quinzenalmente; como esse tipo de filme não prima pelo roteiro, eles se tornam um prato cheio para iniciantes.
- Assistir filmes em inglês sem legenda. Tente assistir filmes falados em diferentes lugares para ir pegando o ponto em comum, ou seja, no meio de todos os sotaques do mundo inteiro o idioma é sempre o mesmo. Descubra-o.
Nesse ponto há uma ressalva: é natural não entender patavina do que as pessoas estão falando no começo do aprendizado. Mas o importante é nunca deixar de ouvir. Com o tempo, nossos ouvidos aos poucos vão sendo treinados para perceber as sutilezas da língua falada, e começamos a abrir nosso leque de conhecimento linguístico. Experimente!
Existem inúmeros recursos hoje em dia para que duas pessoas em qualquer lugar do mundo consigam se comunicar pela grande rede. Afinal, depois de tanto aprender a ler e escutar, é hora de soltar o verbo:
- Participe de fóruns de discussão, de preferência sobre temas que te interessam muito.
- Comece a participar em salas de bate-papo de maneira passiva, apenas "ouvindo" o que os outros digitam.
- Comece a interagir em salas de bate-papo, de preferência com pessoas que também estão aprendendo inglês.
- Tome uma dose de coragem e instale o Skype ou outro programa de conversação e comece a freqüentar salas de conversação.
- Quando perder a vergonha, passe a se corresponder com pessoas que falem inglês em uma conversa mano a mano ("e aê manu, certu?").
Como eu disse no começo desse artigo, cada pessoa tem seu objetivo em aprender uma língua. Cumprido esse objetivo, acredito que já podemos nos dar por satisfeitos. Contudo, quando se começa a aprender de fato uma língua é comum as pessoas acharem que chegarão na linha de chegada ao final do curso, ou ao conseguirem o tão sonhado certificado de proficiência. São marcos, não tenha dúvida. Mas não são o ponto onde se pode parar e descansar pelo resto da vida. Assim como usamos o português no dia-a-dia, o inglês também deve ser usado diariamente. Se não for usado, ele irá aos poucos perdendo lugar em nossas memórias, até o momento em que será necessário recomeçar de um ponto muito distante da linha de chegada que haviamos acreditado ter alcançado para sempre.
A última dica que deixo para vocês é: usem sempre o que aprenderam. A falta de uso é desperdício do tempo passado adquirindo o conhecimento.
Good luck! =)
[2007-08] [2007-10]