- Novidades no Windbg 7
- Antigo bem-vindo do Cine Tênis Verde
- A voz
- Homem de Ferro 2 (Jon Favreau, 2010)
- Houaiss Para Babylon!
- Using TodoList and Microsoft Project together
- Mary e Max - Uma Amizade Diferente (Adam Elliot, 2009)
- Typedef arcaico
- Por que Long Pointer
# Novidades no Windbg 7
Caloni, 2010-04-01 [up] [copy]Semestre que vem deve sair uma nova versão do nosso depurador favorito. Alguns atrasos e novas definições do projeto fizeram com que tivéssemos mais um ou dois releases da finada versão 6 antes da revolução que será o **Depurador 2010**.
Entre as mudanças mais esperadas, e entre as mais inesperadas, encontramos essa pequena lista de novidades que, com certeza, deixarão o desenvolvedor de sistemas da Microsoft muito mais feliz:
Localizador automático de módulos
Hoje em dia é um trabalho um pouco tedioso encontrar qual dos drivers possuía a memória de endereço 0xB8915423, mas agora, juntando o interpretador de símbolos internos e o sistema de tooltips do Windbg, será possível passar o mouse sobre um endereço qualquer e ele mostrará imediatamente quem possui a memória, como ela foi alocada e qual seu conteúdo.
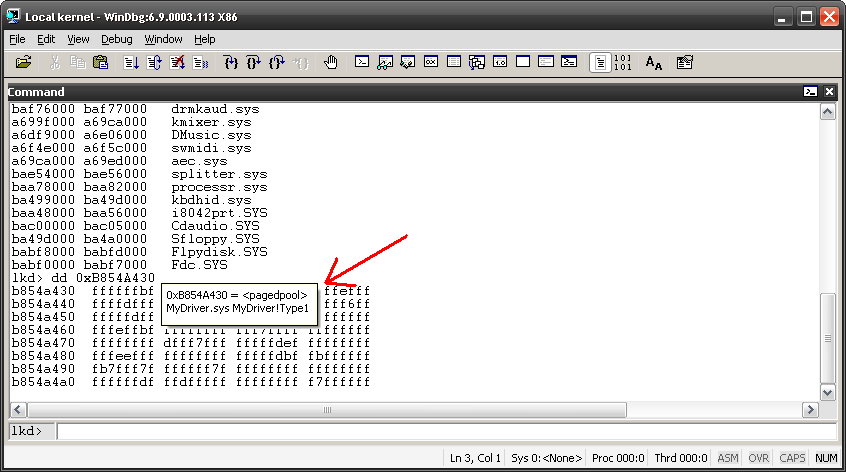
Isso só é possível, é claro, com os símbolos corretamente carregados. Algo não muito difícil se você seguir as recomendações de John Robbins. E é uma mão na roda na hora de dar um feedback instantâneo para o suporte técnico quando der uma tela azul.
Edit and Continue
Sim! Agora se o ddkbuild estiver no path do WinDbg e você **editar o código-fonte** do seu driver durante a depuração (na próxima versão a visualização não será apenas read-only) e der um step-into, automaticamente o depurador irá perguntar se deseja recompilar o projeto. Depois de ativar o processo de build, através das conexões serial/firewire/usb-debug, a nova imagem irá parar diretamente na memória kernel da máquina target.
Algumas ressalvas são colocadas pela equipe da Microsoft, no entanto. Se existirem mudanças que dizem respeito a **alocação dinâmica de memória em nonpaged-pool**, o Edit and Continue não será possível naquele momento, apenas depois do reboot.
O último item, mais esotérico de todos, promete ser lançado a partir da versão 7.1:
The BugCheck Fix Tip
Resumidamente, é um !analyze mais esperto com o algoritmo heurístico do Visual Basic .NET. Assim que for aberto um dump de tela azul e carregados os símbolos e o caminho dos fontes, a nova versão do !analyze irá verificar os valores do BugCheck gerado e, caso seja detectado que o problema está em seu driver, irá sugerir uma correção na sua função que estiver na pilha.
Microsoft (R) Windows Debugger Version 6.9.0003.113 X86
Copyright (c) Microsoft Corporation. All rights reserved.
Loading Dump File [C:\Tests\BSOD\BugCheck7F\2010-03-24ClientMemory.dmp]
Kernel Complete Dump File: Full address space is available
************************************************************
WARNING: Dump file has been truncated. Data may be missing.
************************************************************
Symbol search path is: SRV*c:\tools\symbols*http://msdl.microsoft.com/download/symbols
Executable search path is:
Windows XP Kernel Version 2600 (Service Pack 3) MP (2 procs) Free x86 compatible
Product: WinNt, suite: TerminalServer SingleUserTS
Built by: 2600.xpsp_sp3_gdr.090804-1435
Kernel base = 0x804d7000 PsLoadedModuleList = 0x8055d720
Debug session time: Wed Mar 24 17:51:39.216 2010 (GMT-3)
System Uptime: 0 days 0:05:23.843
Loading Kernel Symbols
.........................................................................................
Loading User Symbols
............
Loading unloaded module list
..........................
*******************************************************************************
* *
* Bugcheck Analysis *
* *
*******************************************************************************
Use !analyze -v to get detailed debugging information.
BugCheck 7F, {d, 0, 0, 0}
*** ERROR: Symbol file could not be found. Defaulted to export symbols for MyDriver.sys -
*** ERROR: Symbol file could not be found. Defaulted to export symbols for mfehidk.sys -
Probably caused by : MyDriver.sys ( MyDriver!KeBugCheckTest+2b )
Followup: MachineOwner
---------
0: kd> !analyze -v
*******************************************************************************
* *
* Bugcheck Analysis *
* *
*******************************************************************************
UNEXPECTED_KERNEL_MODE_TRAP (7f)
This means a trap occurred in kernel mode, and it's a trap of a kind
that the kernel isn't allowed to have/catch (bound trap) or that
is always instant death (double fault). The first number in the
bugcheck params is the number of the trap (8 = double fault, etc)
Consult an Intel x86 family manual to learn more about what these
traps are. Here is a *portion* of those codes:
If kv shows a taskGate
use .tss on the part before the colon, then kv.
Else if kv shows a trapframe
use .trap on that value
Else
.trap on the appropriate frame will show where the trap was taken
(on x86, this will be the ebp that goes with the procedure KiTrap)
Endif
kb will then show the corrected stack.
Arguments:
Arg1: 0000000d, EXCEPTION_GP_FAULT
Arg2: 00000000
Arg3: 00000000
Arg4: 00000000
Debugging Details:
------------------
BUGCHECK_STR: 0x7f_d
DEFAULT_BUCKET_ID: DRIVER_FAULT
PROCESS_NAME: cmd.eze
LAST_CONTROL_TRANSFER: from 80564dd2 to 80544e7b
STACK_TEXT:
a7f4b6a4 80564dd2 badb0d00 89679eb0 a7f40000 nt!KiSystemFatalException+0xf
a7f4b774 ba182d80 e23bb528 00000002 a7f4b86c nt!NonPagedPoolDescriptor+0xb2
WARNING: Stack unwind information not available. Following frames may be wrong.
a7f4b870 804ef19f 8a03a2e0 89665008 8972c838 MyDriver!KeBugCheckTest+0x2b
a7f4b880 b9da1876 89665008 8a0f3a80 00000000 nt!IopfCallDriver+0x31
...
a7f4b940 b9c55e4d 00000002 896651e0 8972c838 mfehidk+0x9128
a7f4b9d8 b9c70ef5 cccccccc 8a03b9f8 8a033ab0 mfehidk+0x9e4d
0012f918 4ad02d98 0014efc0 00150b00 00000000 cmd!ExecPgm+0x22b
...
0012fff0 00000000 4ad05046 00000000 78746341 kernel32!BaseProcessStart+0x23
STACK_COMMAND: kb
FOLLOWUP_IP:
MyDriver!KeBugCheckTest+0x2b
ba182d80 668945a4 mov word ptr [ebp-5Ch],ax
SYMBOL_STACK_INDEX: 2
SYMBOL_NAME: MyDriver!KeBugCheckTest+0x2b
FOLLOWUP_NAME: MachineOwner
MODULE_NAME: MyDriver
IMAGE_NAME: MyDriver.sys
DEBUG_FLR_IMAGE_TIMESTAMP: 4baa49d3
<font color="#0000ff">BugCheck Fix Tip:
-----------------
Try to remove the spin lock aquisition in MyDriver!KeBugCheckTest+2a. By doing this,
the kernel IRQL priority system will not be in starvation mode.
Tip Code: C:\Tests\MyDriver\dispatch-funcs.cpp+345</font>
Followup: MachineOwner
---------
Existem um pouco de polêmica em torno dessa funcionalidade. Alguns dizem que ela vai mais atrapalhar do que ajudar os programadores de kernel com a vinda de analistas de sistemas Júnior programando filtros de file system sem a menor discrepância entre o que é um IRP assíncrono e uma ISR. Outros dizem que existirá uma versão paga do WinDbg com essa funcionalidade, nos mesmos moldes do Visual Studio 2010, que virá com a depuração reversa no Enterprise. Essas especulações só o tempo dirá se são verdade ou não. Se eu tiver que pagar mais caro por essas features, o lobby na empresa onde eu trabalho está garantido.
# Antigo bem-vindo do Cine Tênis Verde
Caloni, 2010-04-01 cinema> <blog> [up] [copy]Atualização (2026-01-24): a partir da data original deste artigo comecei a escrever sobre cinema em um domínio próprio, que nos anos recentes acabou se juntando ao meu blogue técnico em uma massa de milhares de textos. Assim como estou fazendo a curadoria dos textos técnicos, muito menos dos mais de 1300 e lá vai cacetada textos das críticas que fiz estarão aqui no blogue. Irei poupá-los desta poluição nessa versão mais enxuta. O texto abaixo está disponível como um aviso de mudança de fase do autor que vos escreve.
Assistir filmes pode ser usado como entretenimento e fuga da realidade. E, de fato, a maioria das pessoas usa o cinema para isso (eu incluso). No entanto, como tudo na vida, esta forma automática de reagir ao conteúdo que nos é jogado para consumir não é a melhor maneira de interagir com o mundo, nem de aproveitar duas horas de lazer de sua vida.
O Cinema se construiu como parte integrante da era industrial, consequência quase que lógica do avanço do capitalismo e do fornecimento de bens e serviços para uma imensa massa que era antes excluída dos bens mais essenciais à vida humana. Isso torna tudo mais complicado, pois como pode, caro leitor, uma obra ser produzida como um produto, um empreendimento de risco, visando o lucro, e ao mesmo tempo conquistar corações e mentes, e, algumas raras vezes, elevar a comunicação audiovisual em um novo patamar estético e ser celebrado como uma nova forma de arte, talvez a mais completa e complexa que um ser humano poderá experimentar neste mundo?
Para que tudo isso faça sentido é vital que as pessoas assistam cada vez mais e mais filmes, pois apenas pela prática poderemos atingir a excelência em algo na vida. Porém, diferente de consumidores passivos, que deixam seu cérebro em uma tigela enquanto mastigam pipocas como zumbis observando a historinha que é colocada na sala escura cada vez mais cheia de pequenas telas dos celulares dos outros tipos de zumbis, é imperativo que usemos o cérebro e nossa mente como ferramentas de análise crítica do que nos é imposto pela mágica da projeção em 24 (ou 48) fps. Não aguentaremos mais os velhos formatos de uma mídia enlatada se conseguirmos projetar como consumidores ativos para quais tipos de obras dedicaremos nosso tempo e suado dinheirinho.
# A voz
Caloni, 2010-04-01 <quotes> <self> <now> [up] [copy]Perceba que a voz existe e que não é você. Liberdade é reconhecer-se como a consciência por trás da voz.
Eckhart Tolle (O Poder do Silêncio, 2004)
# Homem de Ferro 2 (Jon Favreau, 2010)
Caloni, 2010-04-03 <cinema> movies> [up] [copy]Se a primeira aventura do até então desconhecido Homem de Ferro impressionou o público, a crítica e a própria Marvel, essa continuação morna é a consolidação de Tony Stark como garoto-propaganda dessa fase. Não só isso, mas serve como o gancho que os produtores precisavam para inserir novos personagens secundários que serão mais ou menos relevantes na teia de eventos (ou colcha de retalhos) criada em torno da tão esperada estreia de Os Vingadores, filme que pretende unir uma série de heróis que terão cada um seus trabalhos solo. Uma aposta inédita que parece ter ganhado força justamente por conta da atuação surpreendente de Robert Downey Jr.
Aliás, se no primeiro filme ele consegue expressar tão bem a dualidade entre realismo e quadrinhos, aqui ele mantém sua simpática arrogância, favorecendo um roteiro menos ambicioso e mais burocrático, que se importa pelo menos em situá-lo naquele universo como um herói já consolidado. Exceto, claro, pelas preocupações monopolistas e bélicas do governo americano. Já do lado do povo... bem, ele voa em um robô de ferro. Se eu fosse um garoto, não precisaria de mais nada para adorá-lo.
Mesmo assim, ainda precisamos de um vilão nos moldes de alguém para dar porrada, e apesar do Victor criado pelo bem-vindo Mickey Rourke (O Lutador) ser um candidato à altura, seu desenvolvimento na história segue a aborrecida cartilha de arqui-inimigos ressentidos por acontecimentos passados. Mas não me leve a mal: seu ódio por Stark é bem justificado, mas não a sua execução, que lembra vilões mais descerebrados e instintivos do que poderíamos esperar do gênio que Victor seria pela sua história.
Porém, não contentes com dois conflitos - e essa é uma continuação decente da história do primeiro filme - o "coração" energético e radioativo criado por Stark se mostra instável demais. Agora ele precisa consertar isso e manter sua vida e seus poderes intactos, o que envolve dois desafios particularmente inteligentes: resgatar o passado com seu igualmente gênio pai, e ultrapassá-lo em genialidade. Um drama tão comum envolvendo pai e filho e que por isso mesmo funciona tão bem. Às vezes as melhores ideias nos filmes de super-heróis não vêm de mega-vilões.
Para finalizar, a receita básica aprendida em O Homem-Aranha de Sam Reimi. Você não mantém mais a tensão sexual entre heróis e mocinhas, mas deixa fluir. No caso do mulherengo Tony Stark, uma péssima ideia, pois tira a força ou imunidade ou influência que sua secretária aparentemente tinha sobre ele, como se fosse a única conquista inalcançável do herói. Aparentemente, o novo poder dos heróis dessa época é conseguirem o que quiserem sem muito esforço, nem arranhões, e muito menos sangue.
# Houaiss Para Babylon!
Caloni, 2010-04-08 <projects> [up] [copy]Os últimos comentários de Henrique Esteves (quando havia seção de comentários no blogue) sobre o HouaissParaBabylon me fizeram dar mais uma fuçada nele e ver se tento deixá-lo compatível com o Houaiss 3. Foram apenas algumas horas e acho que resolvi os probleminhas relacionados com a troca do registro de instalação e o nome dos arquivos que armazenam os verbetes.
Apenas para constar, segue a lista de artigos sobre este projeto:
* Conversor de Houaiss para Babylon - parte 1
* Conversor de Houaiss para Babylon - parte 2
* Segunda versão do Houaiss2Babylon
* HouaissParaBabylon versão beta
* HouaissParaBabylon versão 1.1
Foi uma odisseia e tanto. E ainda está longe de ser perfeito. Contudo, fico feliz que muitas pessoas já tenham conseguido usá-lo com sucesso e com a qualidade técnica dos meus visitantes. O Henrique, por exemplo, teve que entender o processo interno que o programa faz para renomear os arquivos do dicionário e assim conseguir a conversão. Pessoas como essa faltam na equipe de suporte técnico de programadores de baixaria.
Isso me faz lembrar que uma das motivações do programador, fora programar, é saber que os usuários usam seu programa. E saber que existem melhorias a ser feitas que vão ser úteis para esses usuários é muito legal. Por isso, continuem assim, caros usuários. E bom proveito!
Obs.: Essa versão foi testada em um Windows XP com o Houaiss 3, Babylon 8 e o Babylon Builder mais atual.
# Using TodoList and Microsoft Project together
Caloni, 2010-04-10 <computer> <english> [up] [copy]The next article about bits is still in the oven. Taking vacation (40 days) had drop me out of ideas! At the moment, I can explain the tips and tricks using TodoList to manage my team and synchronize my tasks in a Microsoft Project timesheet.
The reasons why I am using TodoList are kind of obvious: it does everything I need to organize my day to day tasks and it is portable. Meanwhile, the Project, besides not being portable (I need to carry on with me a 200 MB installer? And do install?) it uses a hard to change format and it was made to project the world, and not to be easily shared.
So, let's go. Everything we need is a current edition of TodoList and Microsoft Project. The first thing we must to do é to export the tasks we want to a default CSV, using the columns we would like to import to Project.
After that it comes the tricky thing, but not so much. We open the project to where we want to import the tasks and choose the option Open again, but this time we select our friend exported-tasks.CSV.
Before we do import, we got to create a new column that will keep the TodoList tasks IDs, to make sure that in the next imports we make we could merge datum together. So, create this column using a significant name.
Now we can go on the import process. Imagining to be the first one, let's create a inicial map for this migration:
The time we choose who is who in the columns list, we just need to setup which columns in Project are the counterpart for the columns in TodoList, and remember to allocate our special column ID.
Just more a few Nexts and voilà! We got our tasks properly imported.
But of course all this work would be useless if we had to (sigh) open the Project. To avoid this impure job, we keep on updating the project status in our tiny, tidy TodoList and, when we need, we just import the data again, but this time using a already saved map (follow the screenshots above) and setting our TodoList ID as the key. This way the tasks already present will be just updated, and the unknown tasks will be added. That's the most important trick in this post.
After I researched all this, I just found out the Project won't be necessary anymore. Lucky me. Now, if you don't have such luck, you can use this post =)
# Mary e Max - Uma Amizade Diferente (Adam Elliot, 2009)
Caloni, 2010-04-16 <cinema> <movies> [up] [copy]Tudo em "Mary e Max" é construído para tentar responder uma das perguntas emocionalmente mais ambiciosas e filosoficamente mais intrigantes que nós, passageiros desse planeta em direção à morte, nos fazemos de vez em quando: o que é a amizade?
Mary (Toni Collette), uma menina da Austrália, começa a se comunicar ao acaso através de cartas com Max (Philip Seymour Hoffman), um senhor de meia-idade de Nova York. Habitantes cada um do seu mundinho particular e distante, suas cores não se misturam, suas músicas possuem diferentes tons, suas idades são incompatíveis (o futuro de Mary é do mesmo tamanho que o passado de Max). Mesmo assim há algo que os une e a todos nós de uma maneira indissociável e misteriosa: a solidão, e uma fascinante melancolia que torna tudo triste à sua volta.
Presos ou na infância lúdica e suas dúvidas e descobertas, ou na velhice autista e seus pequenos desafios do dia-a-dia, as confissões entre esses dois seres tão díspares flui de uma maneira admirável graças à direção precisa de Adam Elliot que com a ajuda de seu montador Bill Murphy combinam luz (Gerald Thompson), som (Dale Cornelius) e uma arte (Craig Fison) em "stop motion" em sincronia com os sentimentos dos seus personagens, que florescem em torno de uma narração onisciente (Barry Humphries) que lê as tais cartas de uma forma empolgante, quase como se conhecesse a fundo cada uma dessas almas separadamente e fizesse de tudo para juntá-las em assuntos comuns. O mais maravilhoso é perceber como até assuntos corriqueiros (como o nascimento dos bebês) se tornam fascinantes nas mãos do hábil roteirista que sintetiza tudo que eles escrevem de uma maneira surpreendentemente orgânica e trivial, mas que mantém uma profundidade digna dos diálogos de Antes do Amanhecer e suas continuações.
Porém, fora a descrição contemplativa, a versão animada da imaginação de ambos é uma diversão à parte, assim como os estranhos seres, animais e humanos, que permeiam a vida dos dois. Além disso, essa não é uma história estática que foca no passado, pois temos o privilégio de acompanhar o crescimento e amadurecimento de Mary, que vai aos poucos sentindo o peso da vida. O que a mantém em movimento em vários momentos é sua amizade com Max. A recíproca é verdadeira, e conseguimos captar através de uma comédia leve que consegue tornar a morte frequente de seus peixes de estimação como uma gag tão eficiente pelas risadas quanto significativa pelo que simboliza, que o velho Max está tão perdido quanto Mary, mas que graças ao seu suporte tenta melhorar de sua doença, nem que seja um pouco a cada dia.
O que nos leva ao impecável terceiro ato, que depois de nos conquistar completamente com personagens tão verossímeis quanto atores de carne-e-osso de um drama "live action", tem a proeza de criar momentos tensos e dramáticos entre os dois mesmo mantendo a distância física que os separa. "Mary e Max" não consegue explicar do que são formadas as amizades, mas consegue descrever com perfeição a amizade desses dois, o que para mim já vale por todos nós.
# Typedef arcaico
Caloni, 2010-04-20 <computer> <blog> [up] [copy]A API do Windows geralmente prima pela excelência em maus exemplos. A [Notação Húngara] e o Typedef Arcaico são duas técnicas que, por motivos históricos, são usados a torto e a direito pelos códigos de exemplo.
Já foi escrito muita coisa sobre os prós e contras da notação húngara. Já o typedef arcaico, esse pedacinho imprestável de código, ficou esquecido, e hoje em dia traz mais dúvidas na cabeça dos principiantes em C++ do que deveria. Para tentar desobscurecer os mitos e fatos, vamos tentar explicar o que significa essa construção tão atípica, mas comum no dia-a-dia.
Vejamos um exemplo típico desse pequeno Frankenstein semântico:
typedef struct _MINHASTRUCT {
int x;
int y;
}
MINHASTRUCT, *LPMINHASTRUCT;
Bom, eu nem sei por onde começar. Talvez pelo conceito de typedef.
Typedefs
Um typedef, basicamente, é um apelido. Você informa um tipo e define "outro tipo".
typedef tipo apelido;
O tipo é tudo que fica entre o typedef e o novo nome, que deve ser um identificador válido na linguagem. Por exemplo, a empresa onde trabalho fez um typedef informal do meu nome:
typedef Wanderley Caloni Wandeco;
Se, futuramente, eu sair da empresa e entrar outro "Wanderley alguma-coisa", será possível usar o apelido novamente, bastando alterar o typedef:
typedef Wanderley Cardoso Wandeco;
_Bom, "outro tipo" é forma de dizer. Isso é uma descrição errônea em muitos livros. De fato, o compilador enxerga **o mesmo tipo com outro nome**, daí chamarmos o typedef de apelido, mesmo._
/** @file dois_apelidos.cpp */
#include <iostream>
using namespace std;
struct Struct
{
int x;
int y;
};
typedef Struct Struct1;
typedef Struct Struct2;
int main()
{
Struct1 s1;
Struct2 s2;
cout << typeid(s1).name() << endl;
cout << typeid(s2).name() << endl;
}
C:\Tests>cl /EHsc dois_apelidos.cpp
...
/out:dois_apelidos.exe
dois_apelidos.obj
C:\Tests>dois_apelidos.exe
struct Struct struct Struct
Granularidade dos tipos
Tipos simples são fáceis de entender porque possuem seus símbolos no mesmo lugar:
int x; char c; long p;
Já os tipos um pouco mais complicados permite alguma mudança aqui e acolá:
int* x; char * y; long * p;
Essa liberdade da linguagem, mesmo sendo um recurso útil, pode ser bem nocivo dependendo de quem olha o código:
int x, y; // dois inteiros int * x, y; // um ponteiro para inteiro e um inteiro int x, *y; // um inteiro e um ponteiro para inteiro int *x, y; // um ponteiro para inteiro e um inteiro
Em algumas formas da sintaxe, além de ser inevitável, gera bastante desconfiança:
// Um ponteiro para função que recebe dois inteiros e não retorna nada.
typedef void (* FP)(int, int) ;
// Um ponteiro para função que recebe dois inteiros e não retorna nada.
void (*)(int, int);
// Um cast para ponteiro para função que recebe dois inteiros e não retorna nada.
( ( void (*)(int, int)) pf )(x, y);
#include <iostream>
void func(int x, int y)
{
std::cout << x << '-' << y << '\n';
}
int main()
{
void* pf = func;
( ( void (*)(int, int) ) pf )(3, 14);
}
Structs em C++
Antigamente, as structs eram construções em C que definiam **um agregado de tipos primitivos** (ou outras structs) e que poderiam gerar variáveis desse tipo em qualquer lugar, desde que informado seu nome e que se tratasse de uma struct:
/** @file structs.cpp */
struct MyStruct { int x, y; };
void func1()
{
struct MyStruct ms;
//...
}
void func2(struct MyStruct msa)
{
//...
}
int main()
{
struct MyStruct ms;
func2(ms);
}
Para evitar toda essa digitação, os programadores usavam um pequeno truque criando um apelido para a estrutura, e usavam o apelido no lugar da struct (apesar de ambas representarem a mesma coisa).
struct MyStruct { int x, y; };
typedef struct MyStruct MS;
ou
typedef struct MyStruct { int x, y; } MS;
struct MyStruct ms1; // ainda prolixo
MS ms2; // mais simples
Com a definição da linguagem C++ padrão, e mais moderna, essa antiguidade foi removida, apesar de ainda suportada. Era possível usar apenas o nome do struct como seu tipo:
/** @file structs.cpp */
struct MyStruct { int x, y; };
void func1()
{
/*struct*/ MyStruct ms;
//...
}
void func2(/*struct*/ MyStruct msa)
{
//...
}
int main()
{
/*struct*/ MyStruct ms;
func2(ms);
}
Porém, isso vai um pouco além de quando a Microsoft começou a fazer código para seu sistema operacional. Naquela época, o padrão ainda estava se formando e existia mais ou menos um consenso de como seria a linguagem C++ (sem muitas alterações do que de fato a linguagem C já era). De qualquer forma, a linguagem C imperava bem mais que C++. Dessa forma, já era bem formada a ideia de como declarar uma struct: a forma antiga.
typedef struct _MINHASTRUCT {
int x;
int y;
}
MINHASTRUCT, *LPMINHASTRUCT;
Além do uso controverso do** _sublinhado** para nomear entidades (que no padrão foi recomendado que se reservasse aos nomes internos da biblioteca-padrão) e do uso de **MAÍUSCULAS_NO_NOME** (historicamente atribuído a nomes definidos no pré-processador), o uso do typedef atracado a um struct era muito difundido. E ficou ainda mais depois que a API do Windows foi publicada com essas definições.
Como fazer,então?
Ora, do mesmo jeito que é feito há vinte anos: sem typedefs. O próprio paradigma da linguagem, independente de padrões de APIs, de sistemas operacionais ou de projetos específicos já orienta o programador para entender o que o espera na leitura de um código-fonte qualquer. Qualquer pessoa que aprendeu o básico do básico sobre ponteiros e structs consegue ler o código abaixo:
// Papai, o que que é isso?
// Ora, filho, apenas uma definição de estrutura!
//
struct MinhaStruct {
int x;
int y;
};
// muitas linhas abaixo...
void func(MinhaStruct* ms)
{
// asterisco significa ponteiro para MinhaStruct!
}
int main()
{
MinhaStruct ms;
func(&ms);
}
Agora, para entender a forma antiga, ou você se baseou no copy&paste dos modelos Microsoftianos, ou seja, decoreba, ou você é PhD em Linguagem C/C++ e padrões históricos de linguagens legadas. Se não é, deveria começar o curso agora.
// Papai, o que que é isso?
// Ora, filho, apenas uma definição de sinônimo da struct
// _MINHASTRUCT, cujo nome não é usado, para dois nomes
// em maiúsculas, apesar se não serem defines, com uma
// nomenclatura de ponteiro que eu nunca vi na vida (obs:
// papai programa em um sistema não-Windows).
//
typedef struct _MINHASTRUCT {
int x;
int y;
}
MINHASTRUCT, *LPMINHASTRUCT;
// muitas linhas abaixo...
void func(LPMINHASTRUCT ms)
{
// o que diabos é um LP, mesmo?
}
int main()
{
MINHASTRUCT ms;
func(&ms);
}
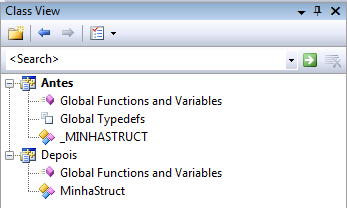
Da mesma forma, o uso de uma estrutura simples de tipos mantém a lista de nomes do seu projeto limpa e clara. Compare o visualizador de classes em projetos Windows com algo mais C++ para ter uma ideia.
É claro, essa é apenas uma sugestão. Existem vantagens em sua utilização. Existe alguma vantagem no modo antigo? Existe: a Microsoft usa, e talvez mais pessoas usem. Basta a você decidir qual deve ser o melhor caminho.
Atualização
De acordo com o leitor Adriano dos Santos Fernandes, a obrigatoriedade do nome struct após seu nome continua valendo para a linguagem C padrão, assim como no compilador GCC ocorre um erro ao tentar omiti-la. Apenas na linguagem C++ essa obrigatoriedade não existe mais.
Eu não fiz meus testes, mas confio no diagnóstico de nosso amigo. A maior falha do artigo, no entanto, é usar a linguagem C como base, quando na verdade ele deveria falar sobre o uso desses typedefs em C++. Esse erro também foi corrigido no original.
API do Windows geralmente prima pela excelência em maus exemplos. A [Notação Húngara]: http://pt.wikipedia.org/wiki/Nota%C3%A7%C3%A3o_h%C3%BAngara
# Por que Long Pointer
Caloni, 2010-04-21 <computer> <blog> [up] [copy]Esse artigo continua a explicação sobre os typedefs arcaicos, já que ainda falta explicar por que diabos os ponteiros da Microsoft começam com LP. Tentei explicar para [minha pupila] que, por ser código dos anos 80, as pessoas usavam LP para tudo, pois os CDs ainda não estavam tão difundidos.
/** @brief Para instanciar um Bozo. @date 1982-02-21 */
typedef struct _BOZO {
char helloMsg[100]; /* definir para "alô, criançada, o bozo chegou..." */
float currentTime; /* definir para 5e60 */
}
BOZO, *LPBOZO;
/** @brief Para instanciar um Pokemon. @date 1996-03-01 */
typedef struct _PIKACHU
{
char helloMsg[100]; // setar para "pika, pika pikachuuuuuuu..."
int pokemonID; // setar para 24
}
PIKACHU, *CDPIKACHU;
Não colou. Então vou tentar explicar do jeito certo.
Antigamente, as pessoas mandavam cartas umas para as outras. Carta, para você, caro leitor de quinze anos, era um e-mail implementado em hardware.
Para mandar um e-mail, usamos o nome da pessoa e o domínio em que seu e-mail é endereçado, ex: nome-da-pessoa@dominio.com.br. Para mandar uma carta usamos duas informações básicas: o nome da rua e o número da casa.

Consequentemente enviamos dois comandos ao carteiro: meu amigo, vá para a rua tal. Chegando lá, encontre o número 1065.
Considere que estamos falando do mesmo bairro ou cidade, o que na minha analogia seria um computador e sua memória. Para enviar cartas para outros bairros em outras cidades (outros computadores em outras redes) teríamos que informar também outros dados, como nome da cidade e CEP.
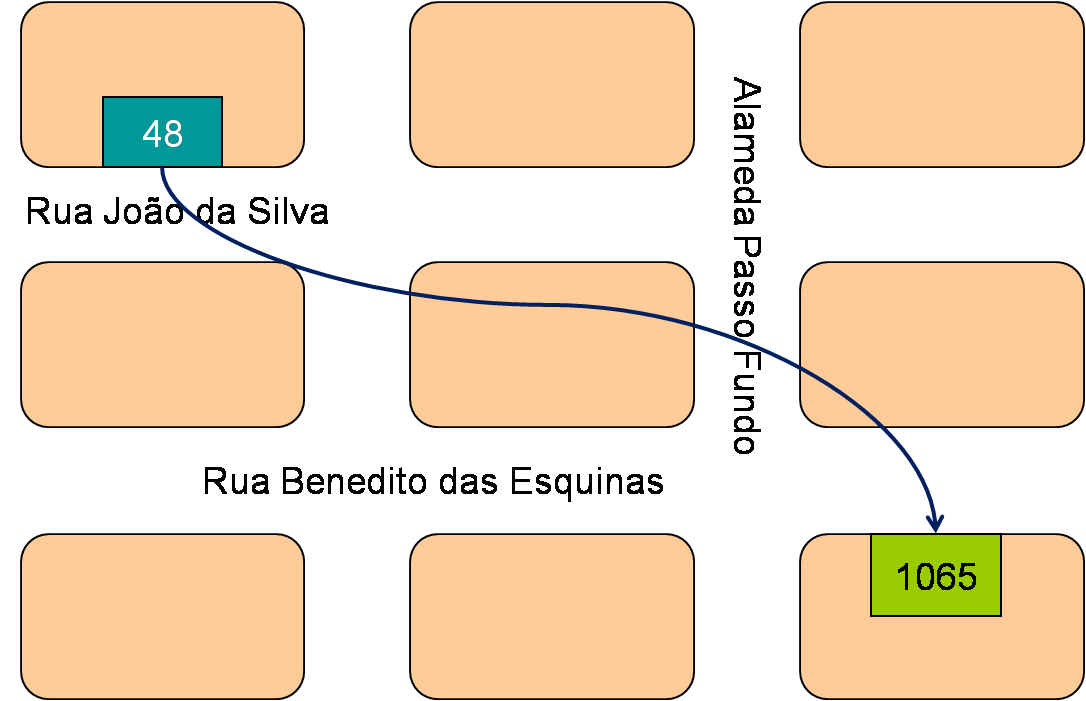
Nesse exemplo também podemos usar o Juquinha do bairro para entregar a carta e economizarmos 10 centavos.
Agora, repare que interessante: em uma rua, cabem no máximo N casas. Se você tentar construir mais casas vai acabar invadindo o espaço de outra rua.
E, já que estamos falando do endereço do destinatário, já podemos relevar que esse endereço constitui um ponteiro em nossa analogia. Se você está usando dois dados para informar o endereço, então estamos falando de um ponteiro longo, long pointer, ou LP!

Long Pointers
Na terminologia Intel para as plataformas 16 bits, a memória do computador era acessível através de segmentos (ruas) e offsets (números), que eram pedaços da memória onde cabiam no máximo N bytes. Para conseguir mais bytes é necessário alocar memória em outro segmento (outra rua).
Os ponteiros que conseguiam fazer isso eram chamados de long pointers, pois podiam alcançar uma memória mais "longa". Os ponteiros que apenas endereçavam o offset (número) eram chamados, em detrimento, short pointers, pois podiam apenas apontar para a memória do seu segmento (rua).
Ora, se seu destinatário está na mesma rua que você, tudo que você tem a dizer ao Juquinha é: "Juquinha, seu moleque, entrega essa carta no número 1065, e vai rápido!". Nesse caso você está usando um short pointer.
Porém, no exemplo que demos, o destinatário está em outra rua. Se o Juquinha entregar a carta no número 1065, mas na rua errada, estará errando o destinatário. Por isso é que você deve usar um long pointer e falar para o Juquinha do segmento!
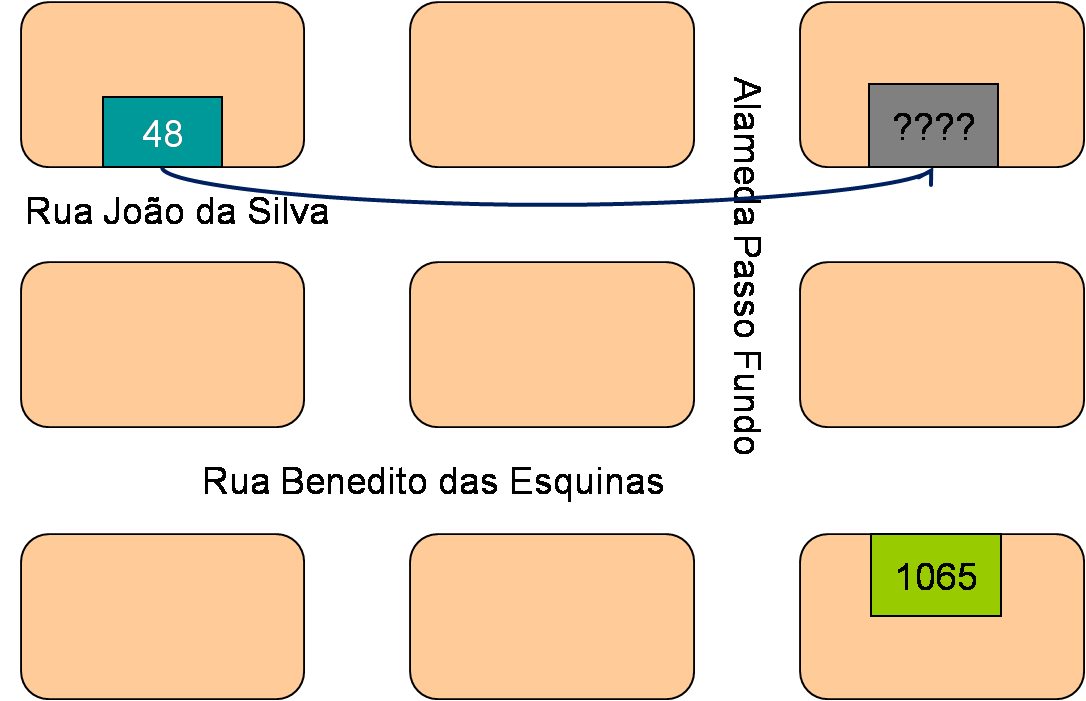
"Juquinha, seu moleque safado, entrega essa carta no Segmento 0xAC89, Offset 0x496E. E vê se anda logo!"
Essa frase era muito usada nos anos 80, com seus 16 bits e tudo mais.
Voltando ao Windows
Com toda essa analogia, fica fácil perceber que o Windows não cabe em uma rua só. Seus aplicativos precisam de muitas ruas para rodar. Isso exige que todos seus ponteiros sejam long, pois do contrário o Juquinha estará entregando as cartas sempre nos endereços errados. Dessa forma, foi estipulado o typedef arcaico padrão para todos os tipos da API que usasse LP (Long Pointer) como prefixo:
typedef unsigned long WORD, *LPDWORD; typedef const char* LPCSTR; typedef <coloque-seu-tipo-aqui> APELIDO, *LPAPELIDO;
E é por isso que, historicamente, todos os ponteiros para os apelidos da API Win32 possuem sua contraparte LP.
Com a era 32 bits (e mais atualmente 64 bits) os endereços passaram a ser flat, ou seja, apontam para qualquer lugar na memória. Se eu quisesse continuar minha analogia falaria que é o equivalente a uma coordenada GPS, também muito na moda, e que pode apontar para qualquer lugar do planeta. Eu, por exemplo, já trabalhei <del>trabalho</del> perto das coordenadas -23.563596,-46.653885, o que eu costumo dizer que fica bem próximo do Paraíso =).
Largando velhos hábitos
De uns anos pra cá, existem novos typedefs nos headers que permitem o uso dos apelidos Win32 apenas com um P inicial.
typedef unsigned long WORD, *LPDWORD, *PDWORD; typedef const char *LPCSTR, *PCSTR; typedef <coloque-seu-tipo-aqui> APELIDO, *LPAPELIDO, *PAPELIDO;
A escolha é livre. Assim como com o typedef arcaico.
os typedefs arcaicos, já que ainda falta explicar por que diabos os ponteiros da Microsoft começam com LP. Tentei explicar para [minha pupila]: http://www.caloni.com.br/basico-do-basico-ponteiros
[2010-03] [2010-05]