- Alquimia
- Como ser um melhor desenvolvedor em 2008
- CppCon III
- Como ter um melhor blogue em 2008
- Analisando Dumps com WinDbg e IDA
- Temas no WinDbg
- Encontrando as respostas do Flash Pops
- Otimização em funções recursivas
- Terceiro encontro C++
- Keychanger de criança
- RmThread: rode código em processo vizinho
- Compartilhando variáveis com o mundo
# Alquimia
Caloni, 2008-01-01 <quotes> <self> <now> [up] [copy]Capte o interior e ele vira exterior.
A realidade principal está no interior: mantenha-o limpo.
Torne-se um alquimista: transforma o metal em ouro, o sofrimento em consciência, a infelicidade em iluminação.
Tolle, Eckhart (O Poder do Agora, 1997)
# Como ser um melhor desenvolvedor em 2008
Caloni, 2008-01-02 [up] [copy]Aproveitando que está se aproximando meu prazo final para minhas resoluções de seis meses atrás, e o DQ já fez o checklist dele, vou dar uma espiada na minha lista de desejos atual e fazer uma nova lista para 2008.
1. Fazer um curso de memorização
Comecei, fiz vários exercícios, mas ainda não acabei todas as aulas. Descobri que a memória pode ser muito mais bem treinada do que realmente é, e existem técnicas bem pensadas que fazem isso sem muito mais esforço do que apenas tempo despendido. De fato todos nós já temos uma memória incrível, só precisamos treiná-la adequadamente.
Como comecei e ainda não parei considero esta tarefa realizada (começar e ganhar ritmo é o mais difícil) e estendido para 2008 inteiro.
2. Fazer um curso de leitura dinâmica
Comecei, fiz quase todos os exercícios e terminei. De fato melhorou em muito minha capacidade de concentração na hora de ler um texto rápido, embora eu ainda fique com muito sono quando faço isso. O importante agora é nunca deixar de treinar, e melhorar cada vez mais o poder dos movimentos oculares.
3. Aprender o meu ritmo
Não existe milagre, mas existem coisas que podemos fazer para ajudá-lo a acontecer. Foi isso que aprendi durante minhas inúmeras tentativas de dominar o tempo e o espaço no desenvolvimento de software. Aprendi muita coisa, inclusive que escritórios não foram criados para serem lugares produtivos, e quase sempre é necessário se defender dos riscos que a internet faz para a saúde.
Enfim, essa tarefa também terminou. Agora é só manutenção constante e disciplinada.
Por fim, considero se achar melhor depois de ter melhorado um ou dois itens da vida profissional uma "escrutinisse", tão inútil quanto achar-se já um desenvolvedor muito bom. Porque a qualquer hora podemos cometer novamente aquelas besteiras que fazíamos há cinco anos, e a qualquer hora podemos ter idéias brilhantes. O importante, na minha opinião, é aprender exatamente por que erramos e por que acertamos. Aprender exatamente, e lembrar-se disso, pode ser um enorme catalisador de anos de depuração aleatória.
"Cada problema que eu resolvo se torna uma regra que serve mais tarde para resolver outros problemas." - Rene Descartes
4. Lista inusitada de tarefas
Sem estar na lista previamente concebida comecei a fazer outras coisas de maneira mais eficiente, relacionado ao trabalho ou não:
- Aprender o leiaute do teclado Dvorak. Treino todo dia cinco minutos há três meses a digitação usando esse leiaute, porque é mais simples, mais rápido e dói menos os dedos.
- Anotar todas as coisas importantes. Seja uma idéia nova, uma idéia sobre uma idéia, ou até mesmo melhoramentos em algum software que dou manutenção, é importante manter tudo anotado, porque sabe-se lá quando isso vai ser usado. Mas, quando for, quem vai se lembrar?
- Bloguear constantemente. Apesar dos sacrifícios que isso às vezes causa, é edificante nunca "deixar a bola cair". Minha regra é sempre publicar um artigo dia sim, dia não durante a semana. Em uma semana começo na segunda, em outra na terça, e assim sucessivamente. Tem funcionado desde que reiniciei o blogue há seis meses, e espero que continue assim.
- Usar novo controle de versão em casa. Há um mês mais ou menos conheci o Mercurial, que é um sistema de controle de versão muito leve e não-centralizado, duas coisas que fazem uns sininhos soarem em minha cabeça. Ele é baseado conjunto de modificações e merge, duas coisas a que não estou acostumado e me forcei a aprender.
Não é muito difícil definir essa lista, pois ela na verdade são as mesmas duas listas que citei anteriormente. Comecei a fazer essas coisas seis meses atrás. Para um fumante de fato parar, uns cinco anos de abstinência é um bom indicador. Acredito que, para um hábito se enraizar, um ano e meio pode ser de bom tamanho.
# CppCon III
Caloni, 2008-01-04 ccppbr> [up] [copy]O ano de 2008 promete. Pelo menos no começo.
Está marcado para dia 19 desse mês em São Paulo o terceiro encontro de programadores C++, cujas informações mais atualizadas você poderá acompanhar em nossa wiki. A grade de eventos, pelo menos por enquanto, é essa:
* 09:30 a 10:00 - Introdução e Apresentação dos Membros do Encontro
* 10:00 a 11:00 - C++ com WxWidgets por Ivo Nascimento
* 11:00 a 11:30 - Debate
* 11:30 a 11:45 - Coffee break
* 11:45 a 12:45 - C++0x - Novas características de suporte a projetos de bibliotecas genéricas por Pedro Lamarão
* 12:45 a 13:15 - Debate
* 13:15 a 14:30 - Almoço
* 14:30 a 15:30 - Threads no CPP ISO - Wanderley Caloni
* 15:30 a 16:00 - Debate
* 16:00 a 16:15 - Coffee break
* 16:1 a 17:00 - Fórum sobre a Organização do Grupo de Usuários e da C/C++ Conference Brasil
* 17:30 a 00:00 - C/C++ Beer Meeting!
Conto com a participação de todos que se interessam, usam ou aprendem sobre essas fabulosas linguagens de programação. Vamos levantar a moral de C++ no cenário brasileiro!
Errata: na verdade o que ocorreu dia 19 foi um encontro de C++ com direito a palestras e coffee break, o que de certa forma invalida o nome CppCon. Futuramente teremos o que poderemos chamar de conferência C++, no sentido amplo do termo. Te espero lá.
# Como ter um melhor blogue em 2008
Caloni, 2008-01-08 [up] [copy]Não é exatamente uma receita de bolo, tampouco uma lista de regras imutáveis. Na verdade, apenas algumas dicas que o criador do termo (we)blog deu sobre como ele imagina que os blogueiros deveriam se comportar em relação aos seus blogues. Entre os toques, ele inicialmente comenta que o princípio de um weblog é ser um histórico dos sítios que navegamos, e que eventualmente podemos publicar conteúdo original. Bem, esse humilde blogue faz exatamente o oposto, acreditando que o conteúdo publicado aqui em português dificilmente será encontrado na web, além de que me sinto um inútil se não colaborar com o mundo usando o conhecimento que aprendi e aprendo no dia-a-dia.
Por isso mesmo, aqui vão as dicas traduzidas, que encontrei no blogue de Lino Resende, verbatim (com meus comentários ao final de cada item):
1. Um blog verdadeiro é um log de todos os sítios que você gostaria de salvar ou dividir.
- Então, hoje, o del.icio.us é melhor para os bloggers do que o próprio Blogger. Isso seria como se os blogues fossem sítios de pesquisadores do google, o que não deixa de ser meia-verdade.
2. Você pode, é claro, colocar links sobre você fora do seu blog, mas se o blog tem mais posts originais do que links, recomendo aprender um pouco de humildade.
- É um golpe bem dado ao Caloni.com.br. Bom, espero ser mais humilde em 2008 =).
3. Se fizer uma pequena procura antes de postar, vai descobrir que alguém já falou do seu assunto e melhor do que você.
- Isso eu faço, mas, como já disse, conteúdo em português é mais escasso, o que compensa a publicação de artigos sobre assuntos já tratados em outras línguas.
4. Seja você mesmo, sem suprimir links que não o tratem favoravelmente. Seus leitores querem saber quem efetivamente você é.
- Essa dica é particularmente difícil para blogues técnicos, como o meu e de muita gente. No entanto, nós tentamos não parecer bots, acredite!
5. Você pode melhorar o título das páginas que sugere quando as descrever e dar o link. Assegure-se de sua descrição fará os leitores se lembrarem dela, reconhecendo páginas que já visitaram ou quando a visitarem novamente.
- Essa é mais fácil de fazer.
6. Use sempre algum adjetivo para descrever sua própria reação à página que recomenda (ótima, imaginativa, clara, útil).
- Essa dica foi clara e útil. Além de imaginativa e ótima, claro.
7. Dê os créditos à fonte que você usou. Assim, seus leitores podem conferi-la e "moverem-se para cima".
- Essencial, especialmente, mais uma vez, se tratando de blogues técnicos.
8. Cuidado com os problemas de formatação estranha, múltiplas páginas com histórias, textos muito longos, etc. Não esconda o link principal entre outros auxiliares, mal identificados ou pobres.
- Essa dica é mais para weblogs de fato. Eu passo.
9. Escolha alguns autores favoritos ou celebridades e crie um feed no Google News, acompanhando novas menções a eles. Assim, outros fãs podem segui-los através do seu blog.
- Você pode seguir os que sigo através da minha Home Page (update 2021-04-18: hoje em dia não sigo mais nada, mas links específicos existem nos posts; quem diria, acabei ficando mais blogger com o passar do tempo). Eventualmente compartilho posts através do Google Reader. Update 2021-04-18: não mais =(
10. Reindique seus links favoritos de tempos em tempos para quem os perdeu, esquece ou o está lendo pela primeira vez.
- Essa é uma coisa que está faltando aqui no Caloni.com.br, que é a manutenção dos artigos antigos. Prometo me esforçar mais em 2008. Promessa de ano-novo =).
É isso. Concorda, discorda, sem corda? Imagino que a dica que mais me afetou foi aquela sobre humildade, lá no começo. Digo isso porque ainda está martelando na minha cabeça, pronta para transformar este blogue em algo mais democrático e transparente.
# Analisando Dumps com WinDbg e IDA
Caloni, 2008-01-10 <computer> [up] [copy]Apesar de ser recomendado que 100% dos componentes de um software esteja configurado corretamente para gerar símbolos na versão release, possibilitando assim a visualização do nome das funções internas através de um arquivo de dump (despejo) gerado na ocorrência de um crash, essa verdade só ocorre em 80% das vezes. Quis Murphy que dessa vez a única parte não "simbolizada" fosse a que gerou a tela azul em um Intel Quad Core que estou analisando esses dias.
Para incluir um programa novo em nosso leque de opções, vamos usar dessa vez uma ferramenta chamada IDA, um disassembler estático cujo nome é uma clara homenagem à nossa primeira programadora da história. E, é lógico, o WinDbg não poderá ficar de fora, já que ele será nosso analisador de dumps.
Tecnicamente falando, um dump nada mais é do que o conjunto de informações relevantes de um sistema em um determinado momento da execução, geralmente logo após um crash, onde tudo pára e morre. No caso do Windows, o crash é chamado de BSOD, Blue Screen Of Death, ou Tela Azul da Morte (bem macabro, não?). Do ponto de vista do usuário, é aquela simpática tela azul que aparece logo após o travamento da máquina.
Em algumas máquinas, essa tela nem mais é vista, pois o Windows XP é configurado automaticamente para exibir um simpático reboot que joga todos os seus dados não-salvos naquele momento para o limbo (ou, como diria meu amigo Thiago, para o "céu dos dados não-salvos antes de uma tela azul").
Dumps podem ser abertos por um depurador que entenda o tipo de dump gerado (Visual Studio, WinDbg, OllyDbg, IDA, sd, etc). Se estamos falando de aplicativos que travaram, o Visual Studio pode dar conta do recado. Se é realmente uma tela azul, o WinDbg é o mais indicado. Para abrir um dump no WinDbg, tudo que temos que fazer é usar o item do menu "File, Open Crash Dump" ou digitar direto da linha de comando: windbg -z meu-crash-dump-do-coracao.dmp.
Após alguns segundos, o WinDbg irá imprimir uma saída cheia de detalhes parecendo o terminal de um filme de raquerismo. Não se preocupe, com o tempo cada detalhe fará mais sentido (ou não). Geralmente a melhor idéia depois de abrir o dump é seguir o conselho do próprio WinDbg e usar o comando !analyze -v, e mais um monte de informações será plotada na tela. Se o arquivo aberto for um minidump ele irá conter apenas a pilha de chamada que causou a tela azul, o estados dos registradores e algumas informações sobre módulos carregados no kernel. A partir daí podemos extrair algumas informações úteis:
- O código do Bug Check. Esse é talvez o mais importante, pois pode resolver rapidamente o nosso problema. Procurando na ajuda do WinDbg pelo código do erro (obs: execute o link pelo explorer) conseguimos ter algumas dicas de como evitar esse erro: "The MAXIMUMWAITOBJECTSEXCEEDED bug check has a value of 0x0000000C. This indicates that the current thread exceeded the permitted number of wait objects". Mais sobre isso pra depois.
- Os dados da pilha. Pela pilha de chamadas, podemos não apenas saber se nosso driver está no meio com cara de culpado, como, através dos _offsets_, descobrir em que função ele se enfiou para dar no que deu.
- A última chamada do kernel antes do nosso driver pode indicar-nos que evento foi o responsável por iniciar todo o processo de cabum. Nesse caso, IopLoadDriver nos dá uma ótima dica: foi na hora de carregar o nosso driver.
Com isso em mãos, mesmo sem símbolos e nomes de funções no código, conseguiríamos achar o código responsável pelo BSOD. Porém, vamos imaginar por um momento que não foi tão fácil assim e fazer entrar em cena outra ferramenta indispensável nessas horas: o Interactive Disassembler.
No site do IDA podemos encontrar o download para uma versão gratuita do IDA, isso se usado com objetivos não-comerciais. Ou seja, para você que está lendo esse blogue por aprendizado, não terá nenhum problema você baixar essa versão e fazer alguns testes com seu driver favorito.
O funcionamento básico do IDA é bem básico, mesmo. Simplesmente escolhemos um executável para ele destrinchar e nos mostrar um assembly bem amigável, com todos os nomes de funções que ele puder deduzir. Como não temos os símbolos do próprio executável, as funções internas ganham "apelidos", como sub6669, loc13F35 e por aí vai. Isso não importa, já que temos nomes amigáveis de APIs para pesquisar no código-fonte e tentar encontrar as funções originais em C.
Pois bem. Como manda o figurino, o primeiro ponto do assembly que temos que procurar é o ponto em que uma função interna é chamada logo após IopLoadDriver, mydriver+0x4058. Por coincidência (ou não, já que essa é a função do IopLoadDriver), se trata da função inicial do executável, ou seja, provavelmente a função DriverEntry no código-fonte (obs: estamos analisando um driver feito para plataforma NT).
No dump que analisei o ponto de retorno é logo após uma chamada à função sub113F0, que não sei qual é. No entanto, o que eu sei é que logo no início é chamada a função IoIsWdmVersionAvailable, o que já nos permite fazer uma correlação com o código-fonte original. Após a chamada à IoIsWdmVersionAvailable, a próxima e última chamada de uma função é o que procuramos. Dessa forma, podemos ir caminhando até o ponto onde o driver chama o sistema operacional.
mydriver+offset: call ds:KeInitializeDpc mov edx, dword_13000 ... push 1 call sub_11BE0 push eax call sub_117D0.text:000114D7 add esi, 0D9Ch push esi ... mydriver+offset: push 0 ... push ebx push edi call ds:KeWaitForMultipleObjects mov eax, [esp+30h+var_14] mov edi, ds:ExFreePoolWithTag ... mov ecx, [esp+20h] push 0
Por sorte o caminho não foi tão longo e cheguei rapidamente no ponto onde é chamada a função KeWaitForMultipleObject que, de acordo com o WinDbg e com a OSR, pode gerar uma tela azul se esperarmos por mais de três objetos e não especificarmos um buffer no parâmetro WaitBlockArray. Agora podemos olhar no fonte e ver por quantos objetos esperamos e tirar nossa própria conclusão do que está acontecendo.
//...
count = 0; // processors
mask = KeQueryActiveProcessors();
maskAux = mask;
while( maskAux )
{
if( maskAux & 1 )
count++;
maskAux >>= 1;
}
//...
KeWaitForMultipleObjects(count,
waitObjects,
WaitAll,
UserRequest,
KernelMode,
TRUE,
NULL,
NULL);
ExFreePool(...);
ExFreePool(...);
ExFreePool(...);
//...
Ora, ora. O número de processadores influencia no número de objetos que estaremos esperando na função de espera. Esse seria um bom motivo para gerar um MAXIMUMWAITOBJECTSEXCEEDED em máquinas onde existe mais de 3 processadores ativos, não? Talvez seja uma boa hora para atualizar esse código e torná-lo compatível com os novos Quad Core.
É importante, durantes os testes de desenvolvimento, sempre manter em dia uma versão debug (para o mundo kernel mode, versões checked) para que os primeiros problemas, geralmente os mais bestinhas, sejam pegos de forma rápida e eficiente. No entanto, um bom desenvolvedor não se limita a depurar com código-fonte. Ele deve estar sempre preparado para enfrentar problemas de falta da versão certa, informação pela metade, situação não-reproduzível. Para isso que servem as ferramentas maravilhosas que podemos usar no dia-a-dia. O IDA é mais uma das que deve estar sempre no cinto de utilidades do bom "debugador".
# Temas no WinDbg
Caloni, 2008-01-14 <computer> [up] [copy]Desde a versão 6.4.7.2 que o WinDbg fornece uma subpasta chamada Themes, onde lá estão diversos workspaces configurados. Existe até um passo-a-passo de como organizar esses temas e escolher o seu favorito. Segue algumas dicas de como transformar corretamente sua área de trabalho para depuração (e mantê-la).
O WinDbg salva suas configurações no registro. Para apagar os valores previamente gravados, rode o seguinte comando:
reg delete HKCU\Software\Microsoft\WinDbg
Você pode gravar um tema, rodar o WinDbg (sem parâmetros), ver se gosta do que viu, e tentar novamente. Quando estiver satisfeito com a aparência, fique com ela e comece o próximo passo.
Nas depurações do dia-a-dia algumas configurações devem estar sempre muito bem configuradas, para que torne seus momentos de desespero porque nada está funcionando mais agradáveis. Por isso, assim que escolher seu tema preferido trate de configurar os seguintes itens:
- Diretórios de símbolos. Você pode começar com .symfix, que vai montar uma string padrão, e adicionar mais diretórios com .sympath+.
- Diretórios de código-fonte. Coloque a raiz dos seus projetos principais. Com o tempo, se você mexe muito nos seus diretórios, é necessário fazer uma manutenção desse valor.
- Diretórios de executáveis. Basicamente é o mesmo do diretório de símbolos.
Depois de configurar tudo isso, ajuste as janelas na melhor maneira e proporção que achar mais agradável. Esse será o último passo, pois depois você irá fechar o WinDbg e salvar o workspace, que a partir daí será o padrão sempre que abrir o depurador.
Para que os arquivos fonte caiam no lugar que você escolheu, durante a configuração, abra um código-fonte e coloque no lugar que gostaria de ver todos os fontes listados, junto com um placeholder (um arquivo C usado como localizador, existem 5 dentro da pasta themes). Após isso, feche o código-fonte, mas mantenha o placeholder. Depois é só fechar o WinDbg salvando as configurações. Tudo deve funcionar como previsto (ou você esqueceu alguma coisa).
Como esses passos deram algum trabalho, trate de salvar as configurações, caso tenha que usá-las em outras máquinas ou restaurá-las caso algo de ruim aconteça com seu SO (como quando você depura seus drivers na mesma máquina em que desenvolve, por exemplo).
reg save HKCU\Software\Microsoft\WinDbg c:\Tools\DbgTools\Themes\MyTheme.reg
Leia a documentação do WinDbg sobre temas (dentro de Themes, Themes.doc). Foi de lá que eu fiz a tradução e adaptação dos passos mais importantes. E esqueça do Visual Studio =)
# Encontrando as respostas do Flash Pops
Caloni, 2008-01-16 <computer> [up] [copy]Existia uma série de jogos no sítio da UOL chamado Flash Pops onde você deve acertar o nome de filmes, programas de televisão, entre outros, que vão da década de 40 até a atualidade. É divertido e viciante fazer pesquisa na internet para encontrar os resultados, ainda mais quando já se é viciado em cinema. Ficamos jogando, eu e minha namorada, por semanas a fio. Quase chegamos a preencher tudo, e por um bom tempo ficamos travados para terminar. Então começamos a apelar para o Google e o IMDB até os limites do razoável. Nesse fim de semana, por exemplo, chegamos a assistir um filme de madrugada onde tocou rapidamente um trecho de uma das músicas que faltava no jogo sobre televisão. No dia seguinte procuramos a trilha sonora do filme, ouvimos faixa a faixa e procuramos o nome da música no Google, para finalmente encontrar o resultado.
Essa foi a última resposta "honesta". Depois resolvi apelar para o WinDbg =)
A primeira coisa que pensei a respeito desse jogo foi que ele não seria tão ingênuo a ponto de colocar as respostas em texto aberto, do contrário, qual seria a graça, certo? Errado! Bom, no final das contas, um passo-a-passo bem simples me levou a encontrar a lista de respostas.
A primeira coisa a fazer é carregar o jogo na memória do navegador. Em seguida, seguindo meu raciocínio inicial, digitei a primeira resposta do jogo.
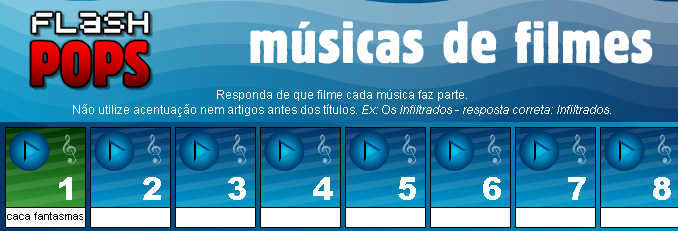
A partir daí, podemos "atachar" o WinDbg no processo do navegador e rastrear a memória do processo.
windbg -pn firefox.exe
Então, como eu dizia, não faça isso em casa enquanto estiver digitando um artigo de seu blogue dentro do navegador. Ele vai travar!
windbg %programfiles%\Mozilla Firefox\firefox.exe
OK. A primeira coisa é procurar pela string digitada, na esperança de achar a estrutura que escreve as respostas de acordo com a digitação. Isso pode ser feito facilmente graças ao WinDbg e ao artigo de Volker von Einem que ensina como procurar strings por toda a memória de um processo (mais tarde iremos também usar o comando-bônus do comentário de Roberto Farah).
0:017> s -a 0 0fffffff "caca fantasmas" 0575f458 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 63 caca fantasmas.c 057fb950 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 00 caca fantasmas..
Interessante. Dois resultados. Olhando o primeiro deles, vemos que encontramos o que queríamos sem nem mesmo tentar quebrar alguma chave de criptografia.
0:017> db 0575f458 0575f458 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 63 caca fantasmas.c 0575f468 61 63 61 2d 66 61 6e 74-61 73 6d 61 73 00 63 61 aca-fantasmas.ca 0575f478 c3 a7 61 20 66 61 6e 74-61 73 6d 61 73 00 63 61 ..a fantasmas.ca 0575f488 c3 a7 61 2d 66 61 6e 74-61 73 6d 61 73 00 67 68 ..a-fantasmas.gh 0575f498 6f 73 74 62 75 73 74 65-72 73 00 41 72 72 61 79 ostbusters.Array 0575f4a8 00 6d 75 73 31 00 6a 61-6d 65 73 20 62 6f 6e 64 .mus1.james bond 0575f4b8 00 30 30 37 00 6d 75 73-32 00 6d 69 73 73 69 6f .007.mus2.missio 0575f4c8 6e 20 69 6d 70 6f 73 73-69 62 6c 65 00 6d 69 73 n impossible.mis
O segundo, porém, não parece uma lista de respostas, mas sim a resposta que acabamos de digitar no navegador.
0:017> db 057fb950 057fb950 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 00 caca fantasmas.. 057fb960 5f 6c 65 76 65 6c 30 2f-6d 75 73 36 32 3a 6d 00 _level0/mus62:m. 057fb970 00 00 00 00 24 44 82 05-20 40 82 05 32 3a 6d 00 ....$D.. @..2:m. 057fb980 00 00 00 00 6c 49 82 05-68 45 82 05 00 00 00 00 ....lI..hE...... 057fb990 00 00 00 00 b4 4e 82 05-b0 4a 82 05 00 00 00 00 .....N...J...... 057fb9a0 00 00 00 00 24 74 85 05-20 70 85 05 00 00 00 00 ....$t.. p...... 057fb9b0 00 00 00 00 6c 79 85 05-68 75 85 05 00 00 00 00 ....ly..hu...... 057fb9c0 70 6f 72 63 65 6e 74 6f-00 63 65 72 74 61 73 00 porcento.certas.
Para se certificar, rodamos novamente o navegador, apagamos a resposta e refazemos a busca.
0:017> g (864.dc0): Break instruction exception - code 80000003 (first chance) eax=7ffda000 ebx=00000001 ecx=00000002 edx=00000003 esi=00000004 edi=00000005 eip=7c901230 esp=03c3ffcc ebp=03c3fff4 iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=0038 gs=0000 efl=00000246 ntdll!DbgBreakPoint: 7c901230 cc int 3 0:017> s -a 0 0fffffff "caca fantasmas" 0575f458 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 63 caca fantasmas.c
De fato, a lista de respostas é tudo que encontramos.
Assim como no artigo sobre carregamento de DLLs arbitrárias, vamos usar o muito útil comando .foreach, que caminha em uma lista de resultados de um comando para executar uma lista secundária de comandos. Apenas para relembrar, a sintaxe do foreach é a seguinte:
.foreach [Options] ( Variable { InCommands } ) { OutCommands }
* Variable. Um nome que usamos no OutCommands. Representa cada token do resultado de InCommands.
* InCommands. Um ou mais comandos que executamos para gerar uma saída na tela. Essa saída será usada em OutCommands, onde Variable é substituído por cada token da saída.
* OutCommands. Um ou mais comandos executados usando a saída na tela de InCommands.
Para o .foreach, um token é uma string separada por espaço(s). A saída dos comandos do WinDbg nem sempre vai gerar algo que podemos usar diretamente, como no caso da busca que fizemos inicialmente. Apenas para demonstração, vamos imprimir todos os tokens da saída de nosso comando.
.foreach ( answerList { s -a 0 0fffffff "caca fantasmas" } ) { .echo answerList }
0575f458
63
61
63
61
20
66
61
6e-74
61
73
6d
61
73
00
63
caca
fantasmas.c
Isso acontece porque ele utilizada cada palavra separada por espaços da saída da busca.
0575f458 63 61 63 61 20 66 61 6e-74 61 73 6d 61 73 00 63 caca fantasmas.c
Por isso usamos a flag `-[1]`, que faz com que o comando imprima apenas o endereço onde ele encontrou a string.
0:017> s -[1]a 0 0fffffff "caca fantasmas" 0x0575f458
Enfim, vamos ao que interessa. Para imprimir todas as strings que representam as respostas, podemos simplesmente, no OutCommands, fazer uma nova busca por string, só que dessa vez genérica, dentro de uma faixa razoável (digamos, 4KB).
0:006> .foreach ( answerList { s -[1]a 0 0fffffff "caca fantasmas" } ) { s -sa answerList L1000 }
059ff458 "caca fantasmas"
059ff467 "caca-fantasmas"
059ff47a "a fantasmas"
059ff48a "a-fantasmas"
059ff496 "ghostbusters"
059ff4a3 "Array"
059ff4a9 "mus1"
059ff4ae "james bond"
059ff4b9 "007"
059ff4bd "mus2"
059ff4c2 "mission impossible"
059ff4d5 "missao impossivel"
059ff4e7 "miss"
059ff4ed "o impossivel"
059ff4fa "missao imposs"
059ff509 "vel"
059ff50d "miss"
059ff513 "o imposs"
059ff51d "vel"
059ff521 "mus3"
059ff526 "carruagens de fogo"
059ff539 "charriots of fire"
059ff54b "chariots of fire"
...
Bom, vou parar o dump por aqui, já que, entre os leitores, pode haver quem queria se divertir primeiro do jeito certo =)
Vimos que o jogo é facilmente quebrável porque armazena as respostas em texto claro. Uma solução alternativa seria utilizar um hash com colisão próxima de zero. Com isso bastaria trocar as respostas possíveis por hashs possíveis e armazená-los no lugar. Quando o usuário digitasse, tudo que o programa precisaria mudar era gerar um hash a partir da resposta do usuário e comparar com o hashs das respostas válidas.
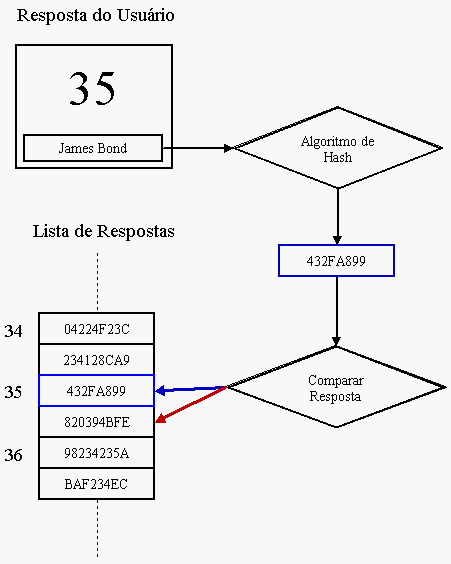
Por uma incrível coincidência, esse truquezinho eu aprendi com meu amigo Thiago há poucos dias, que está lendo o livro Reversing. Simples, porém funcional.
# Otimização em funções recursivas
Caloni, 2008-01-18 <computer> [up] [copy]O livro que estou lendo, Dominando Algoritmo com C, como o próprio nome diz, fala sobre algoritmos em C. Os primeiros capítulos são praticamente uma revisão para quem já programou em C, pois tratam de coisas que programadores com mais de cinco anos de casa devem ter na memória cachê (listas, pilhas, recursão, etc). Porém, tive uma agradável surpresa de achar um truque muito sabido que não conhecia, chamado de tail recursion. Fiz questão de testar nos dois compiladores mais conhecidos e eis o resultado.
Imagine uma função recursiva que calcula o fatorial de um número. Apenas para lembrar, o fatorial de um número n é igual a n * n-1 * n-2 * n-3 até o número 1. Existem implementações iterativas (com um laço for, por exeplo) e recursivas, que no caso chamam a mesma função n vezes.
int factorial(int n)
{
if (n > 1)
return factorial(n - 1) * n;
else
return 1;
}
int main()
{
return factorial(1000);
}
Para ver o overhead de uma função dessas, compilamos com a opção de debug e depuramos no CDB.
>cl /Zi recursive-factorial1.c
>cdb recursive-factorial1.exe
Microsoft (R) Windows Debugger Version 6.8.0004.0 X86
Copyright (c) Microsoft Corporation. All rights reserved.
CommandLine: recursive-factorial1.exe
Symbol search path is: SRV*C:\Symbols*\\symbolserver\OSSYMBOLS
Executable search path is:
ModLoad: 00400000 0041e000 recursive-factorial1.exe
ModLoad: 7c900000 7c9b0000 ntdll.dll
ModLoad: 7c800000 7c8f5000 C:\WINDOWS\system32\kernel32.dll
(594.700): Break instruction exception - code 80000003 (first chance)
eax=00241eb4 ebx=7ffdb000 ecx=00000000 edx=00000001 esi=00241f48 edi=00241eb4
eip=7c901230 esp=0012fb20 ebp=0012fc94 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
ntdll!DbgBreakPoint:
7c901230 cc int 3
0:000> bp factorial
*** WARNING: Unable to verify checksum for recursive-factorial1.exe
0:000> l+*
WARNING: Line information loading disabled
Source options are ffffffff:
1/t - Step/trace by source line
2/l - List source line at prompt
4/s - List source code at prompt
8/o - Only show source code at prompt
0:000> g
Breakpoint 0 hit
> 2: {
0:000> p
> 3: if (n > 1)
0:000>
> 4: return factorial(n - 1) * n;
0:000>
Breakpoint 0 hit
> 2: {
0:000>
> 3: if (n > 1)
0:000>
> 4: return factorial(n - 1) * n;
0:000>
Breakpoint 0 hit
> 2: {
0:000>
> 3: if (n > 1)
0:000>
> 4: return factorial(n - 1) * n;
0:000>
Breakpoint 0 hit
> 2: {
0:000>
> 3: if (n > 1)
0:000>
> 4: return factorial(n - 1) * n;
0:000>
Breakpoint 0 hit
> 2: {
0:000>
> 3: if (n > 1)
0:000>
> 4: return factorial(n - 1) * n;
0:000>
Breakpoint 0 hit
> 2: {
0:000>
> 3: if (n > 1)
0:000> k
ChildEBP RetAddr
0012ff28 00401035 recursive_factorial1!factorial+0x3
0012ff34 00401035 recursive_factorial1!factorial+0x15
0012ff40 00401035 recursive_factorial1!factorial+0x15
0012ff4c 00401035 recursive_factorial1!factorial+0x15
0012ff58 00401035 recursive_factorial1!factorial+0x15
0012ff64 0040105d recursive_factorial1!factorial+0x15
0012ff70 00401268 recursive_factorial1!main+0xd
0012ffc0 7c816fd7 recursive_factorial1!__tmainCRTStartup+0x15f
0012fff0 00000000 kernel32!BaseProcessStart+0x23
0:000>
Ou seja, conforme chamamos a função recursivamente, a pilha tende a crescer. Agora imagine todo o overhead da execução, que precisa, a cada chamada, gerar um stack frame.
A mesma coisa podemos notar se compilarmos o mesmo fonte no GCC e depurarmos pelo GDB. Aliás, a primeira participação especial do GDB nesse blogue =)
$ gcc -g recursive-factorial1.c $ gdb a.exe GNU gdb 6.5.50.20060706-cvs (cygwin-special) Copyright (C) 2006 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i686-pc-cygwin"... (gdb) break factorial Breakpoint 1 at 0x401056: file recursive-factorial1.c, line 3. (gdb) run Starting program: /cygdrive/c/temp/a.exe Loaded symbols for /cygdrive/c/WINDOWS/system32/ntdll.dll Loaded symbols for /cygdrive/c/WINDOWS/system32/kernel32.dll Loaded symbols for /usr/bin/cygwin1.dll Loaded symbols for /cygdrive/c/WINDOWS/system32/advapi32.dll Loaded symbols for /cygdrive/c/WINDOWS/system32/rpcrt4.dll Breakpoint 1, factorial (n=1000) at recursive-factorial1.c:3 3 if (n > 1) (gdb) step 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=999) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=998) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=997) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=996) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=995) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=994) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) Breakpoint 1, factorial (n=993) at recursive-factorial1.c:3 3 if (n > 1) (gdb) 4 return factorial(n - 1) * n; (gdb) backtrace #0 factorial (n=993) at recursive-factorial1.c:4 #1 0x00401068 in factorial (n=994) at recursive-factorial1.c:4 #2 0x00401068 in factorial (n=995) at recursive-factorial1.c:4 #3 0x00401068 in factorial (n=996) at recursive-factorial1.c:4 #4 0x00401068 in factorial (n=997) at recursive-factorial1.c:4 #5 0x00401068 in factorial (n=998) at recursive-factorial1.c:4 #6 0x00401068 in factorial (n=999) at recursive-factorial1.c:4 #7 0x00401068 in factorial (n=1000) at recursive-factorial1.c:4 #8 0x004010b3 in main () at recursive-factorial1.c:11 (gdb)
Isso acontece porque o compilador é obrigado a montar um novo stack frame para cada chamada da mesma função, já que os valores locais precisam manter-se intactos até o retorno recursivo da função. Porém, existe uma otimização chamada de tail recursion, que ocorre se, e somente se (de acordo com meu livro):
- A chamada recursiva é a última instrução que será executada no corpo da função.
- O valor de retorno da chamada não é parte de uma expressão.
Note que ser a última instrução não implica em ser a última linha da função, o importante é que seja a última linha executada. No nosso exemplo, isso já é fato, só que usamos o retorno em uma expressão.
return factorial(n - 1) * n; // o retorno da chamada recursiva // é parte de uma expressão
Por isso é necessário desenvolver uma segunda versão do código, que utiliza dois parâmetros para que aconteça a situação de tail recursion.
int factorial(int n, int a)
{
if (n < 0)
return 0;
else if (n == 0)
return 1;
else if (n == 1)
return a;
else
return factorial(n - 1, n * a);
}
int main()
{
return factorial(1000, 1);
}
Nessa segunda versão, a chamada da função recursiva não mais é parte de uma expressão, e continua sendo a última instrução executada. Agora só temos que compilar com a opção de otimização certa em ambos os compiladores e testar.
Para o Visual Studio, podemos usar a flag /Og (otimização global).
>cl /Zi /Og recursive-factorial2.c
>cdb recursive-factorial2.exe
...
bp factorial
g
...
Breakpoint 0 hit
eax=003235f0 ebx=7c80abc1 ecx=00000001 edx=0041c560 esi=00000002 edi=00000a28
eip=00401020 esp=0012ff68 ebp=0012ffc0 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
recursive_factorial2!factorial:
00401020 55 push ebp
0:000> l+*
WARNING: Line information loading disabled
Source options are ffffffff:
1/t - Step/trace by source line
2/l - List source line at prompt
4/s - List source code at prompt
8/o - Only show source code at prompt
0:000> p
> 3: if (n < 0)
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000>
> 7: else if (n == 1)
0:000>
> 10: return factorial(n - 1, n * a);
0:000>
> 5: else if (n == 0)
0:000> k
ChildEBP RetAddr
0012ff64 0040105c recursive_factorial2!factorial+0x10
0012ff70 00401266 recursive_factorial2!main+0xc
0012ffc0 7c816fd7 recursive_factorial2!__tmainCRTStartup+0x15f
0012fff0 00000000 kernel32!BaseProcessStart+0x23
0:000>
Como podemos ver, após n chamadas, a pilha continua apenas com uma chamada a factorial.
Para o GCC, a opção é mais explítica, e funciona da mesma forma.
$ gcc -g -foptimize-sibling-calls recursive-factorial2.c
$ gdb a.exe
...
(gdb) break factorial
...
(gdb) run
...
Breakpoint 1, factorial (n=1000, a=0) at recursive-factorial2.c:3
3 if (n < 0)
(gdb) step
5 else if (n == 0)
(gdb)
7 else if (n == 1)
(gdb)
10 return factorial(n - 1, n * a);
(gdb)
11 }
(gdb)
factorial (n=1, a=6695656) at recursive-factorial2.c:10
10 return factorial(n - 1, n * a);
(gdb)
factorial (n=999, a=0) at recursive-factorial2.c:2
2 {
(gdb)
Breakpoint 1, factorial (n=999, a=0) at recursive-factorial2.c:3
3 if (n < 0)
(gdb)
5 else if (n == 0)
(gdb)
7 else if (n == 1)
(gdb)
10 return factorial(n - 1, n * a);
(gdb)
11 }
(gdb)
factorial (n=1, a=6695656) at recursive-factorial2.c:10
10 return factorial(n - 1, n * a);
(gdb)
factorial (n=998, a=0) at recursive-factorial2.c:2
2 {
(gdb)
Breakpoint 1, factorial (n=998, a=0) at recursive-factorial2.c:3
3 if (n < 0)
(gdb)
5 else if (n == 0)
(gdb)
7 else if (n == 1)
(gdb)
10 return factorial(n - 1, n * a);
(gdb)
11 }
(gdb)
factorial (n=1, a=6695656) at recursive-factorial2.c:10
10 return factorial(n - 1, n * a);
(gdb)
factorial (n=997, a=0) at recursive-factorial2.c:2
2 {
(gdb)
Breakpoint 1, factorial (n=997, a=0) at recursive-factorial2.c:3
3 if (n < 0)
(gdb)
5 else if (n == 0)
(gdb)
7 else if (n == 1)
(gdb)
10 return factorial(n - 1, n * a);
(gdb)
11 }
(gdb)
factorial (n=1, a=6695656) at recursive-factorial2.c:10
10 return factorial(n - 1, n * a);
(gdb)
factorial (n=996, a=0) at recursive-factorial2.c:2
2 {
(gdb)
Breakpoint 1, factorial (n=996, a=0) at recursive-factorial2.c:3
3 if (n < 0)
(gdb)
5 else if (n == 0)
(gdb)
7 else if (n == 1)
(gdb)
10 return factorial(n - 1, n * a);
(gdb)
11 }
(gdb)
factorial (n=1, a=6695656) at recursive-factorial2.c:10
10 return factorial(n - 1, n * a);
(gdb) backtrace
#0 factorial (n=1, a=6695656) at recursive-factorial2.c:10
#1 0x61006198 in dll_crt0_1 () from /usr/bin/cygwin1.dll
#2 0x61004416 in _cygtls::call2 () from /usr/bin/cygwin1.dll
#3 0x00000000 in ?? ()
(gdb)
Voilà!
PS: De brinde uma versão que permite passar o número via linha de comando para facilitar os testes (e você vai reparar que há um problema em calcular o fatorial de 1000: ele é estupidamente grande! Resolver isso fica como exercício =).
#include <stdio.h>
int factorial(int n, int a)
{
if (n < 0)
return 0;
else if (n == 0)
return 1;
else if (n == 1)
return a;
else
return factorial(n - 1, n * a);
}
int main(int argc, char* argv[])
{
if( argc == 2 )
{
int num = atoi(argv[1]);
int ret = factorial(num, 1);
printf("factorial %d = %d\n", num, ret);
return ret;
}
else
{
printf("how to use: %s <number>\n", argv[0]);
return 1;
}
}
# Terceiro encontro C++
Caloni, 2008-01-22 <ccppbr> [up] [copy]Nesse último sábado aconteceu, como previsto, o terceiro encontro de usuários/programadores C++. Foi um sucesso bem maior que o esperado, pelo menos por mim e pelas pessoas com quem conversei. A organização foi fantástica, e o patrocínio muito importante, o que deu abertura para pensamentos mais ousados sobre o futuro de C++ no Brasil. Foi gerada uma lista de resoluções para o futuro (que começa hoje), onde pretendemos, inclusive, fazer reuniões no mesmo estilo trimestralmente.
Aqui segue um breve relato sobre as palestras que ocorreram no evento.
C++ com wxWidgets, de Ivo Nascimento. Inicialmente o palestrante focou o ponto muito pertinente da visão comercial do uso de um framework multiplataforma que possa rodar nos três sistemas operacionais mais usados no Brasil: Windows, Linux e MacOS. É um fato que programadores precisam se alimentar e alimentar seus filhos, então essa questão pode ser interessante para aqueles que precisam expandir seus mercados.
Como sempre deve rolar, houve demonstração por código de como um programa wxWidgets é estruturado. Basicamente temos inúmeras macros e um ambiente controlado por eventos, da mesma maneira que MFC e outros frameworks famosos.
Para mim foi uma imensa vantagem e economia de tempo ter assistido à palestra, já que faz um tempo que eu tento dar uma olhada nessa biblioteca. Para quem também gostou da idéia, dê uma olhada nos tutoriais disponíveis no sítio do projeto.
C++0x - novas características, de Pedro Lamarão. Para quem achava que as palestras iriam ser superficiais no quesito linguagem deve ter ficado espantado com o nível de abstração, formalidade e profundidade com que foi tratado o assunto das novas características da linguagem C++ que serão aprovadas pelo novo padrão e que irão tornar a programação genérica muito mais produtiva e eficiente.
O foco do palestrante foi no mais importante: quais os problemas que as novas mudanças irão resolver, e de que modo a linguagem irá se tornar mais poderosa para suportar programação genérica, paradigma que, de acordo com o debate que houve após a apresentação, ainda é muito novo, mas que poderá se tornar futuramente uma base sólida de programas mais simples de serem mantidos e especializados.
Para quem se interessou pelo tema e pretende estudar um pouco mais sobre as novidades na linguagem, aqui vão algumas expressões-chave para pesquisa:
- Proposed Wording for Variadic Templates
- Proposed Wording for RValue Reference
- Specifying C++ Concepts
Threads em C++, por Wanderley Caloni. O foco principal desse tema foi dividido entre a interface, óbvia, para suportar programas multithreading em C++, incluindo abstrações de sincronismo e variáveis de condição, e a mudança significativa no padrão para definir um modelo de memória consistente com programas multithreading, a grande vantagem dessa biblioteca ter sido votada, pois tendo as bases para o que eles estão chamando de "execução consistente", a interface é mera conseqüência.
Durante a apresentação foi mostrado um exemplo de uso das classes thread e mutex. O código foi melhorado (mas não completado). Ao final da palestra, fiquei devendo os links. Bem, aqui estão algumas expressões-chave também:
- ISO C++ Strategic Plan for Multithreading
- Thoughts on a Thread Library for C++
- A Memory Model for C++: Strawman Proposal
- Multi-threading Library for Standard C++
Para finalizar, segue o álbum de fotos (não tenho mais Facebook) disponibilizado pelo Alberto Fabiano, organizador-mor do evento.
# Keychanger de criança
Caloni, 2008-01-24 <computer> [up] [copy]Às vezes na vida a vontade de fazer alguma coisa besta acaba sendo mais forte do que o senso de ridículo. Então, resolvi ressuscitar o quase apodrecido RusKey, um programa que fiz para trocar letras digitadas no teclado. A idéia é muito simples: o sujeito digita 'i' e sai um 'c', digita um 'f' e sai um 'u', e assim por diante. Se estiver programando e for criar um if, por exemplo, no lugar da palavra if vai aparecer... bom, não é exatamente um if que vai aparecer na tela =).
Mas se analisarmos dessa maneira pode parecer até coisa de "ráquer", o que certamente não é. Na verdade, se trata de um programa didático que visa ensinar a digitação em leiautes de teclados diferentes do normal em idiomas latinos. Pelo menos essa foi a intenção original.
Na época eu estava às voltas com o leiaute do famoso teclado russo (percebeu a origem do nome do programa?). Eu havia estudado cirílico e estava na hora de pôr em prática no computador. Mas, como quase nunca treinava, quando tentava procurar uma palavra no Babylon ou arriscar uma expressão nas conversas com minha amiga de Moscou me perdia completamente para encontrar as letras. A necessidade é a mãe da invenção e foi aí que começou o desenvolvimento.
Um alfabeto é uma das muitas maneiras de representar as palavras de uma língua por escrito. Uma palavra escrita é um conjunto de letras que representa os sons que usamos para falar essa palavra. Cada som usado é chamado de fonema.
Assim sendo, embora o alfabeto russo seja diferente do alfabeto latino muitos fonemas são compartilhados. Isso quer dizer que podemos pegar algumas letras do cirílico e traduzir diretamente para algumas letras do nosso alfabeto, e outras letras não. Exemplos de letras que podemos fazer isso:
Б == B В == V Г == G Д == D ...
Porém, após a tradução de uma letra no teclado, a posição dela geralmente não é a mesma posição do nosso teclado. Daí temos uma letra de nosso alfabeto em outro lugar. Se for feita uma tradução aproximada entre os dois alfabetos, nossas letras em um teclado russo ficariam dispostas assim:

Bem diferente do QWERT ASDFG que estamos acostumados, não?
Ao digitar usando esse pseudo-leiaute o treino do leiaute do teclado russo estaria sendo feito mesmo escrevendo com o alfabeto latino. Legal, não? Poderia programar com as letras todas trocadas, porque a saída final é a mesma. Basta treinar os dedos para acertarem as mesmas letras nos novos lugares. Assim, quando precisasse escrever no alfabeto cirílico saberia melhor onde cada letra fica.
A idéia é simples, e o código também não é nada complexo. Só preciso de um EXE e uma DLL. No EXE chamo uma função exportada pela DLL que por sua vez instala um hook de mensagens:
g_hHook = SetWindowsHookEx(WH_GETMESSAGE, HookProc, GetModuleHandle(MODULE_NAME), 0);
Nas chamadas da função de callback da DLL, manipulo a mensagem WM_CHAR, que corresponde à digitação de caracteres, para trocar os caracteres originais do teclado pelos caracteres que deveriam existir no recém-inventado formato latino-russo, totalmente fora dos padrões e normas de segurança existentes:
switch( pMsg->message )
{
case WM_CHAR:
{
LPTSTR ptzChar =
_tcschr(g_tzRussAlphabet, (TCHAR) pMsg->wParam);
if( ptzChar )
{
size_t offset = ptzChar - g_tzRussAlphabet;
pMsg->wParam = (WPARAM) g_tzPortAlphabet[offset];
}
}
}
Simples assim. E temos um keylogger que troca caracteres! É impressionante como as coisas mais simples podem se transformar nos momentos mais divertidos de um programador em um feriado.
# RmThread: rode código em processo vizinho
Caloni, 2008-01-28 <computer> [up] [copy]Aproveitando que utilizei a mesma técnica semana passada para desenvolver um vírus para Ethical Hacking, republico aqui este artigo que já está mofando no Code Projet, mas que espero que sirva de ajuda pra muita gente que gosta de fuçar nos internals do sistema. Boa leitura!
RmThread é um projeto que fiz baseado em uma das três idéias do artigo de Robert Kuster em "Three Ways to Inject Your Code into Another Process". No entanto, não utilizei código algum. Queria aprender sobre isso, pesquisei pela internet, e me influenciei pela técnica CreateRemoteThread com LoadLibrary. O resto foi uma mistura de "chamada de funções certas" e MSDN.
O projeto que fiz é útil para quem precisa rodar algum código em um processo vizinho, mas não quer se preocupar em desenvolver a técnica para fazer isso. Quer apenas escrever o código que vai ser executado remotamente. O projeto de demonstração, RmThread.exe, funciona exatamente como a técnica citada anteriormente. Você diz qual o processo a ser executado e a DLL a ser carregada, e ele inicia o processo e carrega a DLL em seu contexto. O resto fica por conta do código que está na DLL.
Para fazer a DLL, existe um projeto de demonstração que se utiliza de uma técnica que descobri para fazer rodar algum código a partir da execução de DllMain sem ficar escravo de suas limitações (você só pode chamar com segurança funções localizadas na kernel32.dll).
Existem três funções que poderão ser utilizadas pelo seu programa:
/** Run process and get rights for running remote threads. */ HANDLE CreateAndGetProcessGodHandle(LPCTSTR lpApplicationName, LPTSTR lpCommandLine); /** Load DLL in another process. */ HMODULE RemoteLoadLibrary(HANDLE hProcess, LPCTSTR lpFileName); /** Free DLL in another process. */ BOOL RemoteFreeLibrary(HANDLE hProcess, HMODULE hModule);
Eis a rotina principal simplificada demonstrando como é simples a utilização das funções:
//...
// Start process and get handle with powers.
hProc = CreateAndGetProcessGodHandle(tzProgPath, tzProgArgs);
if( hProc != NULL )
{
// Load DLL in the create process context.
HMODULE hDll = RemoteLoadLibrary(hProc, tzDllPath);
if( hDll != NULL )
RemoteFreeLibrary(hProc, hDll);
CloseHandle(hProc);
}
//...
A parte mais complicada talvez seja o que fazer quando a sua DLL é carregada. Considerando que ao ser chamada em seu ponto de entrada, o código da DLL possui algumas limitações (uma já citada; para mais, vide a ajuda de DllMain no MSDN), fiz uma "execução alternativa", criando uma thread na função DllMain:
BOOL APIENTRY DllMain(HANDLE hModule, DWORD ul_reason_for_call, LPVOID lpReserved)
{
switch( ul_reason_for_call )
{
case DLL_PROCESS_ATTACH:
{
DWORD dwThrId;
// Fill global variable with handle copy of this thread.
BOOL bRes =
DuplicateHandle(GetCurrentProcess(),
GetCurrentThread(),
GetCurrentProcess(),
g_hThrDllMain,
0,
FALSE,
0);
if( bRes == FALSE )
break;
// Call function that do the useful stuff with its DLL handle.
CloseHandle(CreateThread(NULL,
0,
RmThread,
(LPVOID) LoadLibrary(g_tzModuleName),
0,
dwThrId));
}
break;
//...
A função da thread, por sua vez, é esperar pela finalização da thread DllMain (temos o handle dessa thread armazenado em g_hThrDllMain), fazer o que tem que fazer, e retornar, liberando ao mesmo tempo o handle da DLL criado para si:
/**
* Sample function, called remotely for RmThread.exe.
*/
DWORD WINAPI RmThread(LPVOID lpParameter)
{
HMODULE hDll = (HMODULE) lpParameter;
LPCTSTR ptzMsg = _T("Congratulations! You called RmThread.dll successfully!");
// Wait DllMain termination.
WaitForSingleObject(g_hThrDllMain, INFINITE);
//TODO: Put your remote code here.
MessageBox(NULL,
ptzMsg,
g_tzModuleName,
MB_OK : MB_ICONINFORMATION);
// Do what the function name says.
FreeLibraryAndExitThread(hDll, 0);
}
A marca TODO é aonde seu código deve ser colocado (você pode tirar o MessageBox, se quiser). Como DllMain já foi previamente executada, essa parte do código está livre para fazer o que quiser no contexto do processo vizinho.
Um detalhe interessante é que é necessária a chamada de FreeLibraryAndExitThread. Do contrário, após chamar FreeLibrary, o código a ser executado depois (um simples return) estaria em um endereço de memória inválido, já que a DLL não está mais carregada. O resultado não seria muito agradável.
Um problema chato (que você poderá encontrar) é que, se a DLL não for carregada com sucesso, não há uma maneira trivial de obter o código de erro da chamada de LoadLibrary. Uma vez que a thread inicia e termina nessa função API, o LastError se perde. Alguma idéia?
# Compartilhando variáveis com o mundo
Caloni, 2008-01-30 <computer> [up] [copy]Desde que comecei a programar, para compartilhar variáveis entre processo é meio que consenso usar-se a milenar técnica do crie uma seção compartilhada no seu executável/DLL. Isso funciona desde a época em que o Windows era em preto e branco. Mas, como tudo em programação, existem mil maneiras de assar o pato. Esse artigo explica uma delas, a não-tão-milenar técnica do use memória mapeada nomeada misturada com templates.
Era comum (talvez ainda seja) fazer um código assim:
// aqui definimos uma nova seção (note o 'shared' usado como atributo)
#pragma section("shared", read, write, shared)
// um conjunto de variáveis agrupadas para facilitar o compartilhamento
struct EstruturaDoCoracao
{
int meuIntPreferido;
char meuCharAmigo;
double meuNumeroDePontoFlutuanteCamarada;
};
// uma instância da struct acima para podermos usar nos processo amigos
__declspec(allocate("shared")) EstruturaDoCoracao g_coracao;
int main()
{
g_coracao.meuCharAmigo = 'C';
g_coracao.meuIntPreferido = 42;
g_coracao.meuNumeroDePontoFlutuanteCamarada = 3.14159265358979323846264338;
}
Aquele pragma do começo garante que qualquer instância do mesmo executável, mas processos distintos, irão compartilhar qualquer variável definida dentro da seção "shared". O nome na verdade não importa muito - é apenas usado para clareza - , mas o atributo do final, sim.
Algumas desvantagens dessa técnica são:
- Não permite compartilhamento entre executáveis diferentes, salvo se tratar-se de uma DLL carregada por ambos.
- É um compartilhamento estático, que permanece do início do primeiro processo ao fim do último.
- Não possui proteção, ou seja, se for uma DLL, qualquer executável que a carregar tem acesso à área de memória.
Muitas vezes essa abordagem é suficiente, como em hooks globais, que precisam apenas de uma ou duas variáveis compartilhadas. Também pode ser útil como contador de instâncias, do mesmo jeito que usamos as variáveis estáticas de uma classe em C++ (vide shared_ptr do boost, ou a CString do ATL, que usa o mesmo princípio).
Houve uma vez em que tive que fazer hooks direcionados a threads específicas no sistema, onde eu não sabia nem qual o processo host nem quantos hooks seriam feitos. Essa é uma situação onde fica muito difícil usar a técnica milenar.
Foi daí que eu fiz um conjunto de funções alfa-beta de compartilhamento de variáveis baseado em template e memória mapeada:
#pragma once
#include <windows.h>
#include <tchar.h>
/** Aloca uma variável em memória mapeada, permitindo a qualquer processo
com direitos enxergá-la e alterá-la.
*/
template<typename T>
HANDLE AllocSharedVariable(T** pVar, PCTSTR varName)
{
DWORD varSize = sizeof(T);
HANDLE ret = CreateFileMapping(INVALID_HANDLE_VALUE, NULL, PAGE_READWRITE,
0, varSize, varName);
if( ret )
{
*pVar = (T*) MapViewOfFile(ret, FILE_MAP_ALL_ACCESS, 0, 0, 0);
if( ! *pVar )
{
DWORD err = GetLastError();
CloseHandle(ret);
SetLastError(err);
}
}
else
*pVar = NULL;
return ret;
}
/** Abre uma variável que foi criada em memória mapeada, permitindo ao
processo atual enxergar e alterar uma variável criada por outro processo.
*/
template<typename T>
HANDLE OpenSharedVariable(T** pVar, PCTSTR varName)
{
DWORD varSize = sizeof(T);
HANDLE ret = OpenFileMapping(FILE_MAP_ALL_ACCESS, FALSE, varName);
if( ret )
{
*pVar = (T*) MapViewOfFile(ret, FILE_MAP_READ | FILE_MAP_WRITE, 0, 0, varSize);
if( ! *pVar )
{
DWORD err = GetLastError();
CloseHandle(ret);
ret = NULL;
SetLastError(err);
}
}
else
*pVar = NULL;
return ret;
}
/** Libera visualização de uma variável em memória mapeada. Quando o último processo
liberar a última visualização, a variável é eliminada da memória.
*/
template<typename T>
VOID FreeSharedVariable(HANDLE varH, T* pVar)
{
if( pVar )
UnmapViewOfFile(pVar);
if( varH )
CloseHandle(varH);
}
Como pode-se ver, o seu funcionamento é muito simples: uma função-template que recebe uma referência para um ponteiro de ponteiro do tipo da variável desejada, o seu nome global e retorna uma variável alocada na memória de cachê do sistema. Como contraparte existe uma função que abre essa memória baseada em seu nome e faz o cast (coversão de tipo) necessário. Ambas as chamadas devem chamar uma terceira função para liberar o recurso.
O segredo para entender mais detalhes dessa técnica é pesquisar as funções envolvidas: CreateFileMapping, OpenFileMapping, MapViewOfFile e UnmapViewOfFile. Bem, o CloseHandle também ;)
Ah, é mesmo! Fiz especialmente para o artigo:
#define _CRT_SECURE_NO_DEPRECATE
#include "ShareVar.h"
#include <windows.h>
#include <tchar.h>
#include <stdio.h>
#define SHARED_VAR "FraseSecreta"
/** Exemplo de como usar as funções de alocação de memória compartilhada
AllocSharedVariable, OpenSharedVariable e FreeSharedVariable.
*/
int _tmain(int argc, PTSTR argv[])
{
// passou algum parâmetro: lê a variável compartilhada e exibe
if( argc > 1 )
{
system("pause");
TCHAR (*sharedVar)[100] = 0; // ponteiro para array de 100 TCHARs
HANDLE varH = AllocSharedVariable(&sharedVar, _T(SHARED_VAR));
if( varH && sharedVar )
{
_tprintf(_T("Frase secreta: '%s'n"), *sharedVar);
_tprintf(_T("Pressione <enter> para retornar..."));
getchar();
}
}
else // não passou parâmetro: escreve na variável
// compartilhada e chama nova instância
{
TCHAR (*sharedVar)[100] = 0; // ponteiro para array de 100 TCHARs
HANDLE varH = AllocSharedVariable(&sharedVar, _T(SHARED_VAR));
if( varH && sharedVar )
{
PTSTR cmd = new TCHAR[ _tcslen(argv[0]) + 10 ];
_tcscpy(cmd, _T("\""));
_tcscat(cmd, argv[0]);
_tcscat(cmd, _T("\" 2"));
_tcscpy(*sharedVar, _T("Tuintuintuclaim"));
_tsystem(cmd);
delete [] cmd;
}
}
return 0;
}
Preciso lembrar que essa é uma versão inicial ainda, mas que pode muito bem ser melhorada. Duas idéias interessantes são: parametrizar a proteção da variável (através do SECURITY_ATTRIBUTES) e transformá-la em classe. Uma classe parece ser uma idéia bem popular. Afinal, tem tanta gente que só se consegue programar se o código estiver dentro de uma.
[2007-12] [2008-02]