- Conhecer a mente
- Iteradores não são constantes
- Estranho
- Sed, Grep e afins
- O mistério das pilhas diferentes
- Influence Board
- Como rodar qualquer coisa como serviço
- Depuração da MBR
- WinDbg a distância
- Backup de pobre
- EPA-CCPP 4: nossa comunidade ganhando forma
- Quarto encontro C++
# Conhecer a mente
Caloni, 2008-03-01 <quotes> <self> <now> [up] [copy]Se quisermos conhecer mesmo a nossa mente, o corpo sempre nos dará um reflexo confiável.
Quando estamos presentes, podemos permitir que a mente seja como é, sem nos deixar enredar por ela.
Tolle, Eckhart (O Poder do Agora, 1997)
# Iteradores não são constantes
Caloni, 2008-03-04 <computer> [up] [copy]Um bug que já encontrei uma dúzia de vezes entre os novatos da STL é a utilização de iteradores como se eles não fossem mudar nunca. Porém, a verdade é bem diferente: iteradores se tornam inválidos sim, e com muito mais freqüência do que normalmente se imagina. Entre as situações em que iteradores podem mudar estão as seguintes:
- Inserção de novo elemento no contêiner
- Remoção de novo elemento no contêiner
- Redimensionamento no tamanho do contêiner
Por exemplo, o tradicional código do exemplo abaixo contém o tradicional erro de iterador inválido:
for( container::iterator it = obj.begin(); it != obj.end(); ++it )
{
if( it->member == 0 ) // condição para apagar elemento
{
obj.erase(it); // a partir daqui it é inválido,
// e não adianta incrementá-lo
}
}
Para operações como essa, o retorno geralmente nos dá uma dica de para onde vamos na varredura do contêiner. No caso do método erase, o retorno é o próximo iterador válido, ou o final (retornado pelo método end). Um código mais esperto gera um erro mais sutil:
for( container::iterator it = obj.begin(); it != obj.end(); ++it )
{
if( it->member == 0 ) // condição para apagar elemento
{
it = obj.erase(it); // ótimo, atualizou it. só
// que se ele for o final,
// será incrementado
}
}
Algo de errado irá acontecer apenas se o elemento removido for o último localizado no contêiner.
Esse é um erro comum para os acostumados com outros tipos de iteração (ex: ponteiros) e que não estudaram os princípios básicos da STL, entre eles o da reutilização de algoritmos. Se fosse usado este princípio, nada disso teria acontecido:
struct remove_if_zero
{
bool operator() (ObjElement& element)
{
return element->member == 0;
}
};
obj.remove_if( remove_if_zero() ); // pronto!
Quando precisamos fazer algo nos elementos de um contêiner STL, é quase certo que existirá um algoritmo genérico para essa tarefa, seja no próprio contêiner ou na forma de função (`<algorithm>`). Nunca se esqueça disso na hora de desenvolver seus próprios algoritmos e não precisará reinventar a roda todos os dias.
# Estranho
Caloni, 2008-03-06 [up] [copy]Bom, é hora de dizer tchau. Essa é minha última semana escovando bits na empresa onde estava por três anos. É estranho e esquisito dizer isso, mas me sinto um tanto aliviado. Nessa empreitada, porém, aprendi algumas coisas que valem a pena colocar na bagagem. Sempre é melhor entender do que criticar.
Por exemplo, vejamos a palavra estranho: quantas vezes você já pronunciou essa palavra quando estava diante de um problema daqueles esotéricos? Muitas vezes, não foi? E os problemas não-esotéricos?
Quando nos acostumamos a usar uma palavra para aliviar a dor de não entendermos o que está acontecendo diante de nós, visto pelos nossos próprios olhos, estamos nos condicionando a parar de cutucar nosso cérebro para encontrar uma resposta rápida e racional para o que está acontecendo. Em suma: nos fechamos ao mundo falando "estranho".
Não por esse motivo, mas por estarmos cansados de tanto ouvir falar essa palavra, eu e meu amigo Thiago começamos a instituir uma "taxa simbólica" de 1 (um) real para os que proferirem a dita cuja, e passamos a usar o dinheiro arrecadado para o bem da comunidade, comprando o que nós, programadores, mais veneramos nos momentos de debugging: bolachas!
Essa "medida provisória" aos poucos foi se alastrando pelas mesas do departamento, ao ponto máximo de todos da área técnica, além do diretor comercial, colaborar para a nossa "caixinha de um real".
Criamos um ambiente livre de estranhos. E criamos um trauma em nossas cabeças. A partir das primeiras semanas, toda vez que estávamos em algum lugar em que uma pessoa desconhecida (um estranho) dizia a palavra, soava um sino em nossas cabeças, quase fazendo com que nossa mão acusadoramente se erguesse e fizesse o gesto com o dedo indicando que a pessoa, a partir daquele momento, estava devendo um real para nossa caixinha comunitária.
E assim fomos indo, meses a fio, sem falar essa palavra na presença dos fiscais do um real, que éramos todos nós. A proibição foi linear e englobou todas as situações de vida social em que poderíamos nos expressar: no trabalho, no almoço, por mensagem instantânea, por e-mail, pelo celular, fora do trabalho, nos artigos do blogue...
Pois é, caro leitor, nos artigos do blogue. Se você procurar nestes últimos três anos qualquer menção à palavra "estranho" por aqui com certeza não irá encontrar.
Até agora, quando finalmente foi quebrado o encanto. Quer dizer, oficialmente a cobrança está extinta, mas nossas mentes sempre irão conter esse sino acusador tocando no ônibus, nas ruas, no cinema, no shopping, em casa. Enfim, nos códigos estranhos de nossa vida.
# Sed, Grep e afins
Caloni, 2008-03-10 <computer> [up] [copy]Esse artigo é resultado de eu ter me matado para conseguir encontrar a forma correta de usar o aplicativo sed para fazer uma filtragem simples nos resultados de uma listagem de arquivos.
Primeiramente, eu gostaria de expressar minha total surpresa ao não conseguir encontrar um guia simples e confiável de uso dessas ferramentas na web. Existem três teorias: ou eu não sei usar as palavras mágicas certas no Google, ou a indexação das páginas realmente importantes sobre o assunto não funcionam com o Google, ou de fato não existe documentação fácil sobre o tema.
Como esta é uma exceção em anos de "googadas", eu fico com a terceira opção.
Existem algumas ferramentas que já salvaram minha vida uma dúzia de vezes e devo admitir que são tão poderosas e flexíveis quanto difíceis de usar:
- Grep. Use esta se quiser fazer uma busca, qualquer busca, em um arquivo, um conjunto de arquivos ou uma enxurrada de caracteres do prompt de comando.
- Sed. Use esta se quiser processar a entrada de um arquivo, um conjunto de arquivos ou uma enxurrada de caracteres do prompt de comando.
- Sort. Use esta se quiser ordenar qualquer coisa da entrada padrão (inclusive arquivos, conjunto de arquivos...).
Essas ferramentas são nativas do ambiente Linux, mas podem ser instaladas no Windows através do Cygwin, do Mingw ou nativamente através das ferramentas GnuWin32.
O que eu queria era processar a saída de um programa de forma que eu tivesse a lista de todas as extensões dos arquivos. Por exemplo, para a seguinte entrada:
c:\path\arquivo1.cpp c:\path\arquivo2.h c:\arquivo3.hpp c:\path\path2\arquivo4.cpp
Eu gostaria de uma saída no seguinte formato:
.cpp .h .hpp
Basicamente é isso.
Para filtrar o path do arquivo, e ao mesmo tempo retirar seu nome, podemos usar o seguinte comando (fora outras trilhões de variantes):
programa | sed -e "s/^.*\\//" -e "s/.*\.\(.*\)/\1/"
Após esse processamento, a saída é um monte de extensões vindas de um monte de arquivos:
cpp h cpp h c h cpp h mak vcproj h cpp h cpp h cpp h cpp h c h txt c cpp h mak vcproj cpp h ...
Como podemos ver e é óbvio de imaginar, muitas extensões irão se repetir. Para eliminar as repetições e ordenar a saída da saída corretamente, usamos o comando sort:
programa | sed -e "s/^.*\\//" -e "s/.*\.\(.*\)/\1/" | sort -u
Os caracteres .*[]^$\ dão problemas se usados sem escape no sed, pois fazem parte dos comandos para procurar expressões regulares. Use-os com o caractere de escape `\`.
Para concatenar comandos no sed, use sempre -e "comando". A ordem de execução dos comandos é a ordem em que eles são inseridos na linha de comando, ou seja, podemos confiar que no segundo comando o primeiro já terá sido executado e assim por diante.
Para fazer o escape das barras do caminho de um arquivo temos que usar o conjunto `\/` (obs.: caminhos em formato Unix). Para evitar esse uso enfadonho podemos substituir o caractere de divisão do comando s colocando-o na frente:
s/path\/muito\/muito\/muito\/longo.cpp/outropath\/muito\/muito\/longo.cpp/s#/path/muito/muito/muito/longo.cpp#/outropath/muito/muito/longo.cpp#
Para agrupar expressõe, use sempre `\(` e `\)`. É o contrário do uso dos caracteres especiais. Coisas de Unix.
# O mistério das pilhas diferentes
Caloni, 2008-03-12 <computer> [up] [copy]Mal comecei a leitura do meu mais novo "mother-fucker" livro e já encontrei a solução para nunca mais viver o terror que vivi quando tive que testar minha engenharia reversa do artigo sobre o Houaiss. Se trata de uma simples questão que não sei por que não sigo todas as vezes religiosamente: configure seus símbolos corretamente.
Esse é o primeiro ponto abordado pelo autor, por se tratar de algo que, caso não seja bem feito, pode dar dores de cabeça piores do que o próprio problema que originou a sessão de debugging. Por isso eu repito:
Configure Seus Símbolos Corretamente
Vamos acompanhar alguns momentos de tortura alheia?
Tudo aconteceu quando inesperadamente perdi metade do artigo que estava escrevendo para explicar o processo de engenharia reversa no dicionário Houaiss. Tive que refazer todos os meus testes que havia feito no laptop. Como a preguiça é a mãe de todas as descobertas, não estava com ele ligado no momento do "reteste" e por isso acabei usando a máquina desktop, mesmo.
A análise inicial consistia simplesmente em verificar as entradas e saídas da função ReadFile, na esperança de entender a formatação interna do dicionário. Repetindo a seqüência:
windbg -pn houaiss2.exe
0:001> bp kernel32!ReadFile "dd @$csp L6" $$ Dando uma olhada nos parâmetros
g
0012fa70 0040a7a9 00000200 08bbf1d0 00000200
0012fa80 0012fa88 00000000
eax=0012fa88 ebx=00000200 ecx=00000200 edx=08bbf1d0 esi=08bbf1d0 edi=00000200
eip=7c80180e esp=0012fa70 ebp=0012facc iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
kernel32!ReadFile:
7c80180e 6a20 push 20h
$$ O buffer de saída é 08bbf1d0
$$ O número de bytes lidos é 200
0:000> db 08bbf1d0 L80
08bbf1d0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf1e0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf1f0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf200 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf210 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf220 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf230 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
08bbf240 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
0:000> bp /1 @$ra "db 08bbf1d0 L80"
0:000> g
08bbf1d0 2a 70 72 6f 67 72 61 6d-61 2d 66 6f 6e 74 65 0d *programa-fonte.
08bbf1e0 0a 43 73 2e 6d 2e 0d 0a-64 7b 5c 69 20 73 58 58 .Cs.m...d{\i sXX
08bbf1f0 7d 0d 0a 54 69 6e 66 0d-0a 3a 70 72 6f 67 72 61 }..Tinf..:progra
08bbf200 6d 61 20 64 65 20 63 6f-6d 70 75 74 61 64 6f 72 ma de computador
08bbf210 20 65 6d 20 73 75 61 20-66 6f 72 6d 61 20 6f 72 em sua forma or
08bbf220 69 67 69 6e 61 6c 2c 20-61 6e 6f 74 61 64 6f 20 iginal, anotado
08bbf230 70 65 6c 6f 20 70 72 6f-67 72 61 6d 61 64 6f 72 pelo programador
08bbf240 20 65 6d 20 75 6d 61 20-6c 69 6e 67 75 61 67 65 em uma linguage
0:000> $$
0:000> $$ Tudo legível? Mas já? Ai, meu Deus, alguém chama uma benzedeira!
0:000> $$
Se notarmos no artigo anterior, veremos que o conteúdo do arquivo lido não é em texto claro, sendo necessário passar por mais algumas instruções assembly para descobrir a função responsável por embaralhar o conteúdo na memória. Contudo, ao rodar esses comandos novamente, eis que a saída do ReadFile já vem toda legível, como se o dicionário não estivesse mais encriptado.
A leitura foi feita e o texto direto do arquivo veio em claro? O que está acontecendo? Quando abro pelo comando type ele aparece todo obscuro...
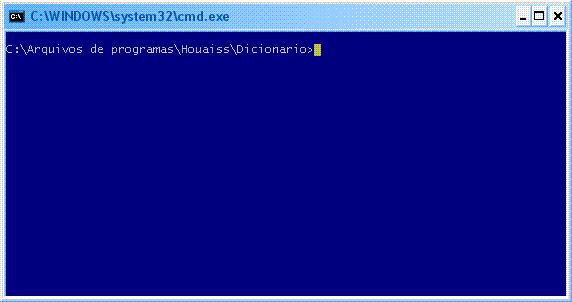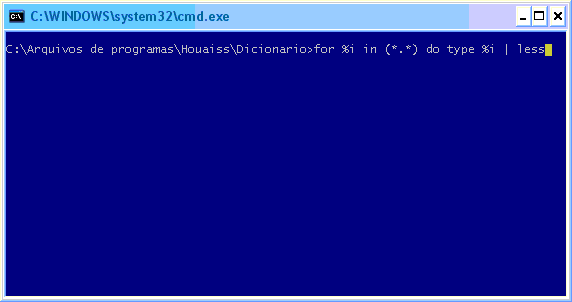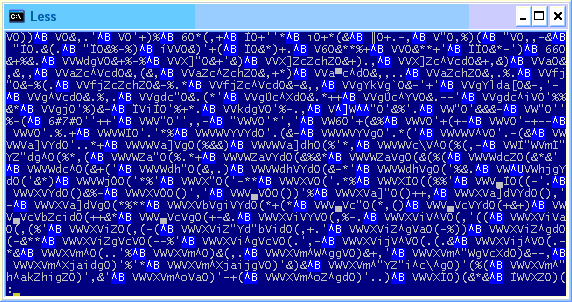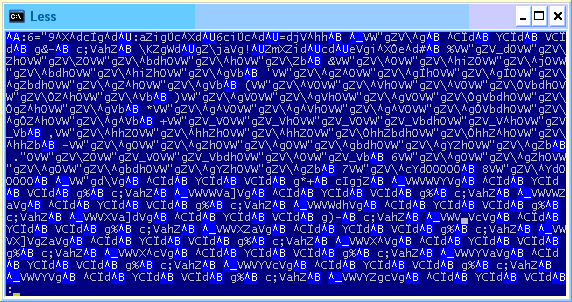
Sim, alguma coisa não-trivial acaba de acontecer. Testei esse procedimento no laptop e no desktop, sendo que esse problema aconteceu apenas no desktop. Dessa vez a curiosidade falou mais alto que a preguiça, e tive que abrir as duas máquinas e comparar os resultados.
Depois de um pouco de cabeçadas rastreando o assembly executado, descobri que o ponto onde o breakpoint havia parado não era o retorno da chamada a ReadFile. Isso eu não vou demonstrar aqui pois se trata de raciocínio de passo-a-passo no assembly até descobrir a diferença. É enfadonho e sujeito a erros. Sugiro que tente um dia desses. Para mim, o resultado lógico de tudo isso é a saída que segue:
0012fa70 0040a7a9 00000200 08bbf1d0 00000200 0012fa80 0012fa88 00000000 eax=0012fa88 ebx=00000200 ecx=00000200 edx=08bbf1d0 esi=08bbf1d0 edi=00000200 eip=7c80180e esp=0012fa70 ebp=0012facc iopl=0 nv up ei pl zr na pe nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 kernel32!ReadFile: 7c80180e 6a20 push 20h 0:000> ? poi(esp) Evaluate expression: 4237225 = 0040a7a9 0:000> ? @$ra Evaluate expression: 4959640 = 004bad98 0:000> ? poi(@$csp) Evaluate expression: 4237225 = 0040a7a9
Como podemos ver pelos comandos acima, o pseudo-registrador $ra não está mostrando o valor corretamente!
A primeira coisa que se faz numa hora dessas é comparar as versões dos componentes do depurador de ambos os ambientes. Para isso usamos o comando version.
0:000> version $$ desktop
Windows XP Version 2600 (Service Pack 2) UP Free x86 compatible
Product: WinNt, suite: SingleUserTS
kernel32.dll version:
Debug session time: Tue Feb 26 19:51:58.295 2008 (GMT-3)
System Uptime: 0 days 1:14:07.857
Process Uptime: 0 days 0:31:52.840
Kernel time: 0 days 0:00:01.482
User time: 0 days 0:00:02.723
Live user mode: <Local>
command line: '"C:\Tools\DbgTools\windbg.exe" -pn houaiss2.exe' Debugger Process 0xEC4
dbgeng: image 6.6.0007.5, built Sat Jul 08 17:12:40 2006
[path: C:\Tools\DbgTools\dbgeng.dll]
dbghelp: image 6.6.0007.5, built Sat Jul 08 17:11:32 2006
[path: C:\Tools\DbgTools\dbghelp.dll]
DIA version: 60516
Extension DLL search Path:
C:\Tools\DbgTools\winext;C:\Tools\DbgTools\winext\arcade;(...)
Extension DLL chain:
dbghelp: image 6.6.0007.5, API 6.0.6, built Sat Jul 08 17:11:32 2006
[path: C:\Tools\DbgTools\dbghelp.dll]
ext: image 6.6.0007.5, API 1.0.0, built Sat Jul 08 17:10:52 2006
[path: C:\Tools\DbgTools\winext\ext.dll]
exts: image 6.6.0007.5, API 1.0.0, built Sat Jul 08 17:10:48 2006
[path: C:\Tools\DbgTools\WINXP\exts.dll]
uext: image 6.6.0007.5, API 1.0.0, built Sat Jul 08 17:11:02 2006
[path: C:\Tools\DbgTools\winext\uext.dll]
ntsdexts: image 6.0.5457.0, API 1.0.0, built Sat Jul 08 17:29:38 2006
[path: C:\Tools\DbgTools\WINXP\ntsdexts.dll]
0:000> version $$ laptop
Windows XP Version 2600 (Service Pack 2) UP Free x86 compatible
Product: WinNt, suite: SingleUserTS Personal
kernel32.dll version:
Debug session time: Tue Feb 26 20:54:39.718 2008 (GMT-3)
System Uptime: 9 days 10:26:39.289
Process Uptime: 0 days 0:00:56.359
Kernel time: 0 days 0:00:00.406
User time: 0 days 0:00:01.078
Live user mode: <Local>
command line: '"C:\Tools\DbgTools\windbg.exe" -pn houaiss2.exe' Debugger Process 0x864
dbgeng: image 6.8.0004.0, built Thu Sep 27 18:28:09 2007
[path: C:\Tools\DbgTools\dbgeng.dll]
dbghelp: image 6.8.0004.0, built Thu Sep 27 18:27:05 2007
[path: C:\Tools\DbgTools\dbghelp.dll]
DIA version: 20119
Extension DLL search Path:
C:\Tools\DbgTools\WINXP;C:\Tools\DbgTools\winext;C:\(...)
Extension DLL chain:
dbghelp: image 6.8.0004.0, API 7.0.6, built Thu Sep 27 18:27:05 2007
[path: C:\Tools\DbgTools\dbghelp.dll]
ext: image 6.8.0004.0, API 1.0.0, built Thu Sep 27 18:26:59 2007
[path: C:\Tools\DbgTools\winext\ext.dll]
exts: image 6.8.0004.0, API 1.0.0, built Thu Sep 27 18:26:28 2007
[path: C:\Tools\DbgTools\WINXP\exts.dll]
uext: image 6.8.0004.0, API 1.0.0, built Thu Sep 27 18:26:45 2007
[path: C:\Tools\DbgTools\winext\uext.dll]
ntsdexts: image 7.0.6440.1, API 1.0.0, built Thu Sep 27 18:45:23 2007
[path: C:\Tools\DbgTools\WINXP\ntsdexts.dll]
OK. A versão instalada no desktop é bem antiga. Pode ser um indício. Fiz então a atualização e comparei novamente a saída de version. Tudo igual. Decidi então usar aquela lógica cética que é desenvolvida por quem costuma depurar coisas sinistras e esotéricas por anos e anos e não duvida de mais nada, mas também acredita piamente que tudo tem um motivo. Se não está aparente, basta descobri-lo. E foi o que eu fiz. Gerei dois dumps distintos, um no laptop e outro no desktop. Ambos estavam com os ponteiros de instrução apontados exatamente para a entrada da função ReadFile, início de todo esse problema. Copiei o dump do desktop para o laptop e vice-versa.
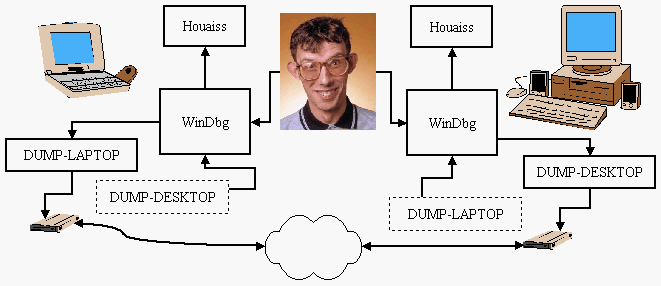
Abri o dump do desktop no laptop: tudo funcionando. Abri o dump do laptop no desktop: mesmo erro. Conclusão óbvia: é algo relacionado com o WinDbg no desktop, uma vez que o estado da pilha que era mostrado corretamente no laptop em ambos os dumps falhava duplamente na máquina desktop.
.sympath Symbol search path is: <empty>
Isso com certeza não cheira bem. Ainda mais porque do outro lado do hemisfério, meu laptop estava configurado com toda a rigidez que um laptop de WinDbgeiro deve ter:
0:000> .sympath Symbol search path is: SRV*C:\Symbols*http://msdl.microsoft.com/download/symbols
E aí estava uma diferença plausível. Consertados os diretórios de símbolos, tudo voltou ao normal.
Procure primeiro verificar as coisas mais simples. Depois você tenta consertar o universo. Mas, primeiro, antes de tudo, veja se o cabo de rede está conectado. Ou no nosso cado de debugueiro:
Configure Seus Símbolos Corretamente
# Influence Board
Caloni, 2008-03-14 <computer> <projects> [up] [copy]Há muito tempo sou enxadrista não-praticante. Acho que os anos de programação me deixaram mais viciado em codar do que pensar no xeque-mate. No entanto, sempre que posso, dou uma escapulida do Visual Studio e jogo uma partida ou duas na rede, quase sempre, é claro, tomando um piau psicológico.
A falta de prática e estudos pesa muito para um enxadrista amador, já que facilmente esquecemos das combinações mortíferas que podemos aplicar e levar. É muito difícil ter em mente aquelas três dúzias de aberturas que já são batidas (e suas variantes), ou então as regrinhas de praxe de como detonar nas finais com um cavalo e um bispo.
Por isso mesmo aprendi em um livro chamado Xadrez sem Mestre, de J. Carvalho, uma técnica universal e independente de decoreba que levei pra vida toda, e tem me trazido algumas partidas no mínimo interessantes. Se trata de analisar o esquema de influências em cima do tabuleiro. Influências, nesse caso, se refere ao poder de fogo das peças amigas e inimigas. O interessante é que deixa-se de lado a análise das próprias peças! Se estuda tão somente o tabuleiro, e apesar de parecer um método difícil, ele melhora sua percepção gradativamente, e é responsável por muitas das partidas simultâneas jogadas às cegas por alguns ilustres GMIs.

Atenção: esse artigo trata sobre xadrez admitindo que o leitor saiba as regras básicas do jogo, assim como um pouco de estratégia. Se você chegou até aqui e está viajando, sugiro que pare de ler e vá jogar uma partida.
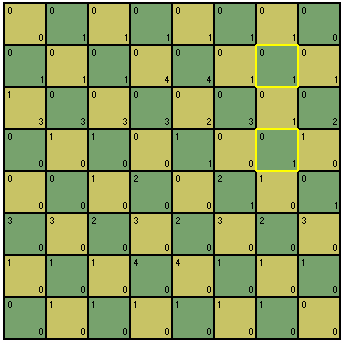
Vamos supor que a posição no tabuleiro em um dado momento seja a seguinte:
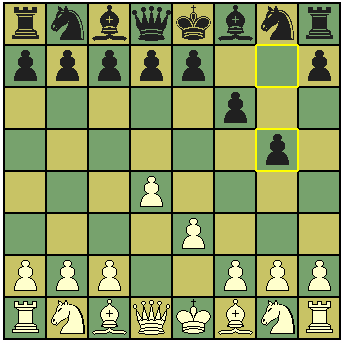
Ora, é um mate inevitável, não é? Agora imagine por um momento que você não tenha percebido isso, e precise de uma ajudinha para saber onde cada peça pode ir ou atacar no próximo lance.
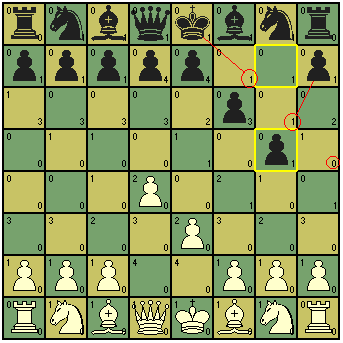
Agora ficou muito mais fácil de perceber que a única saída do rei não possui nenhuma proteção, já que tanto o peão quanto o próprio rei não podem fazer muita coisa se a dama atacar a diagonal vulnerável. E ela pode fazer isso.
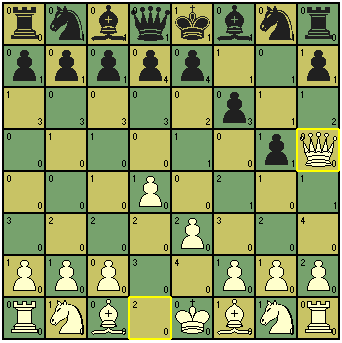
Essa maneira de mostrar as influências em um tabuleiro de xadrez eu apelidei de Influence Board, e criei um projeto em linha de comando para fazer as devidas considerações a respeito de uma posição determinada. Mas como ninguém hoje em dia gosta de usar o WinDbg pra jogar xadrez, transformei meu projeto em pseudo-plugin para o WinBoard, um famoso frontend de xadrez que costumo usar em minhas esporádicas partidas.
Basicamente a única coisa que o futuro usuário das influências deve fazer é baixar o projeto WinBoard; no caso a versão disponível meu repositório do GitHub (update: not anymore) e compilar (suporta cmake). Caso queira uma versão nova do programa terá que fazer o merge entre as duas versões (a versão base usada foi a 2.4.7).
mkdir build && cd build cmake -A Win32 .. cmake --build .
Após compilado, basta rodar o winboard.exe gerado; haverá uma nova opção "Show Influence" do menu General. Voilà! É possível até jogar às cegas com esse brinquedinho (opção Blindfold).
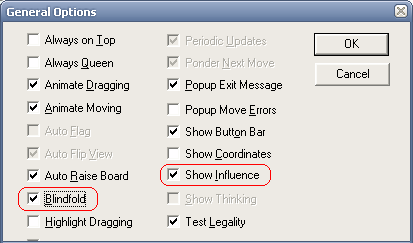
Bom divertimento!
# Como rodar qualquer coisa como serviço
Caloni, 2008-03-20 <computer> [up] [copy]A maior vantagem de se rodar um aplicativo como serviço, interativo ou não, é permitir que ele seja iniciado antes que seja feito um logon na máquina. Um exemplo que acontece comigo é a necessidade de depurar a GINA. Para isso, preciso que o depurador remoto do Visual Studio seja iniciado antes do logon. A solução mais fácil e rápida é rodar o Msvcmon, a parte servidora da depuração, como um serviço. Hoje eu descobri um atalho bem interessante para isso.
Um artigo do Alex Ionescu falava sobre esse aplicativo linha de comando usado para criar, iniciar e apagar serviços. Mesmo não sendo o foco do artigo, achei muito útil a informação, pois não conhecia esse utilitário. Logo começaram a borbulhar idéias na minha mente:
"E se eu usasse esse carinha para iniciar o notepad?"

Bem, o Bloco de Notas é a vítima padrão de testes. Logo, a linha a seguir provaria que é possível rodá-lo na conta de sistema:
sc create Notepad binpath= "%systemroot%\NOTEPAD.EXE" type= interact type= own
Porém, como todo serviço, é esperado que ele se comunique com o Gerenciador de Serviços do Windows. Como o Bloco de Notas mal imagina que agora ele é um motta-fucka service, expira o timeout de inicialização e o SCM (Service Control Manager) mata o processo.
>net start notepad The service is not responding to the control function. More help is available by typing NET HELPMSG 2186.
Como diria meu amigo Thiago, "não bom".
Porém porém, o SCM não mata os processos filhos do processo-serviço. Bug? Feature? Gambi? Seja o que for, pode ser usado para iniciar o nosso querido msvcmon:
set binpath=%systemroot%\system32\cmd.exe /c c:\Tools\msvcmon.exe -tcpip -anyuser -timeout -1 sc create Msvcmon binpath= "%binpath%" type= interact type= own
Agora, quando iniciarmos o serviço Msvcmon, o processo cmd.exe será criado, que por sua vez irá rodar o msvcmon.exe que queríamos, e ficará esperando inocentemente pela sua "funesta morte" pelo SCM.
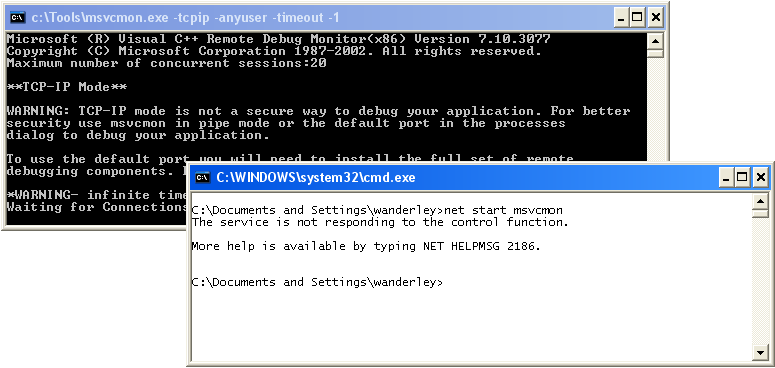
# Depuração da MBR
Caloni, 2008-03-24 <computer> [up] [copy]Dando continuidade a um artigo bem antigo sobre depuração da BIOS usando SoftIce, como já vimos, podemos igualmente depurar a MBR após a chamada da INT13. Porém, devo atentar para o fato que, em algumas VMs, e sob determinadas condições do tempo e quantidade de ectoplasma na atmosfera, é possível que a máquina trave após o hot boot iniciado pelo depurador. Isso provavelmente tem cura usando o espaço de endereçamento alto da memória com a ajuda de aplicativos como LH e UMB.
Porém, estou aqui para contar uma nova forma de depurar essa partezinha do código que pode se tornar um tormento se você só se basear em tracing na tela (ou na COM1): usando o aplicativo debug do DOS.
O debug é um programa extremamente antigo, criado antes mesmo do MS-DOS pertencer à Microsoft e do Windows Vista ter sido criado. Como todo sistema operacional, é essencial que exista um programa para verificar problemas em outros programas. Essa foi a "motivação" para a criação do Debug.
Com o passar do tempo e com a evolução dos depuradores modernos, o uso do debug foi diminuindo até a chegada dos 32 bits, quando daí ele parou de vez de ser usado. Com um conjunto limitado de instruções, a versão MS é incapaz de decodificar o assembly de 32 bits, mostrar os registradores estendidos e de depurar em modo protegido.
O FreeDOS é um projeto de fonte aberto que procura criar uma réplica do sistema MS-DOS, com todos seus aplicativos (e um pouco mais). Entre eles, podemos encontrar o debug refeito e melhorado. A versão com código-fonte possui suporte às instruções "novas" dos processadores 32 e suporta acesso à memória estendida, modo protegido e melhorias na "interface com o usuário" (como repetição de comandos automática, mudança no valor dos registradores em uma linha, etc). Enfim, nada mau. É por isso que comecei a utilizá-lo e é nele que me baseio o tutorial logo abaixo.
Para conseguirmos essa proeza é necessário reiniciarmos a máquina com algum sistema 16 bits, de preferência que caiba em um disquete. Junto com ele basta uma cópia do debug.com. Após reiniciarmos e aparecer o prompt de comando, podemos chamar o depurador e começar a diversão:
A MBR fica localizada no primeiro setor do HD ativo (master). A BIOS automaticamente procura esse HD e faz a leitura usando a INT13, função da própria BIOS para leitura de disquetes e derivados.
Lembre-se que nem sempre existirá um MS-DOS para usarmos a INT21, tradicionalmente reservada para este sistema operacional. Portanto, se acostume com as "limitações" das funções básicas da BIOS.
O debug.com inicialmente começa a execução em um espaço de memória baixa. Podemos escrever um assembly qualquer nessa memória e começar a executar. Isso é exatamente o que iremos fazer, e a instrução escolhida será a INT13, pois iremos ler o primeiro setor do HD para a memória e começar a executá-lo. Isso é a depuração da MBR.
Para fazer isso, algumas informações são necessárias, e tudo está disponível no sítio muito simpático e agradável de Ralf Brown, o cara que enumerou todas as interrupções conhecidas, além de diversas outras coisas.
Como queremos ler um setor do disco, a função da interrupção que devemos chamar é a AH=02:
DISK - READ SECTOR(S) INTO MEMORY AH = 02h AL = number of sectors to read (must be nonzero) CH = low eight bits of cylinder number CL = sector number 1-63 (bits 0-5) high two bits of cylinder (bits 6-7, hard disk only) DH = head number DL = drive number (bit 7 set for hard disk) ES:BX -> data buffer
Muito bem. Tudo que temos a fazer é preencher os registradores com os valores corretos:
rax 0201 ; função e número de setores (1) rcx 0001 ; número do cilindro e do setor (cilindro = 0, setor = 1) rdx 0080 ; número da cabeça (0) e do drive (HD = 0, o bit 7 deve estar levantado) res 0000 ; segmento em que é executada a MBR rbx 7e00 ; offset em que é executada a MBR
Essa é a maneira em que as coisas são. Você certamente poderia usar outro endereço, mas estamos tentando deixar a emulação de um boot o mais próximo possível de um boot de verdade. E, tradicionalmente, o endereço de execução da MBR é em 0000:7E00. Para recordar disso, basta lembrar que o tamanho de um setor é de 0x200 bytes, e que dessa forma a MBR vai parar bem no final do endereçamento baixo (apenas offset).
Essa organização é diferente do endereço inicial da BIOS, que é por padrão 0xFFFF0.
Após definir corretamente os registradores, tudo que temos que fazer é escrever uma chamada à INT13 no endereço atual e executar. O conteúdo inicial do disco será escrito no endereço de memória 0000:7E00. Após isso trocamos o IP atual para esse endereço e começamos a depurar a MBR, como se estivéssemos logo após o boot da máquina.
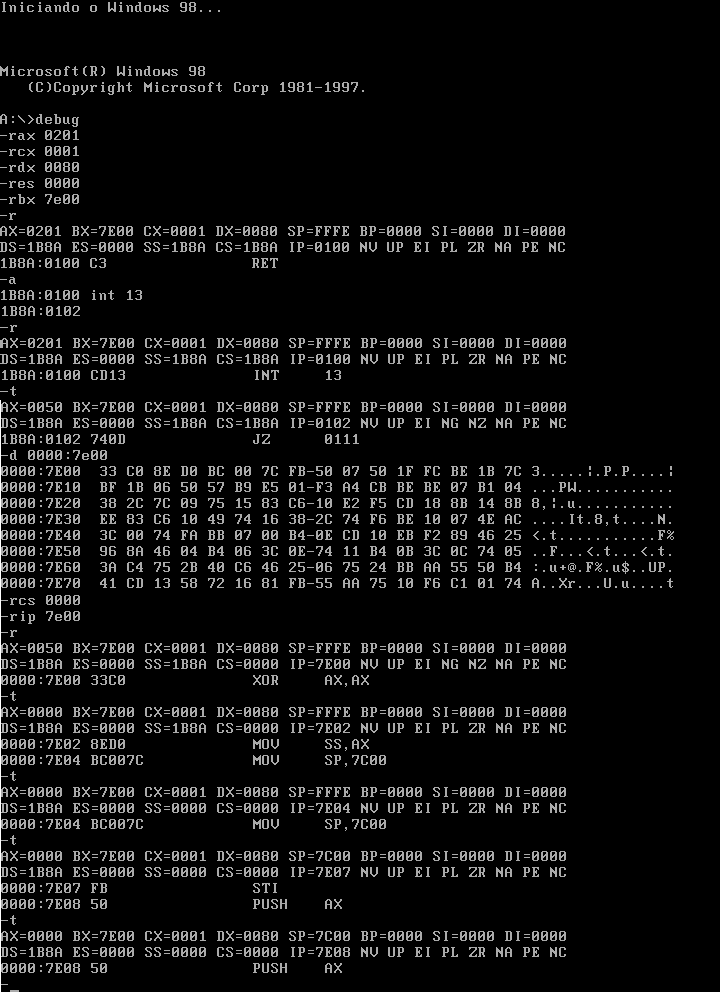
Além da MBR, muitas vezes é preciso depurar a própria BIOS para descobrir o que está acontecendo. Nesse caso, tudo que precisamos fazer é colocar o ponteiro de próxima instrução para a região de memória 0xFFFF0, que traduzido para segmento/offset fica f000:fff0 (mais explicações sobre isso talvez em um futuro artigo).
-rcs f000 -rip fff0 -t
# WinDbg a distância
Caloni, 2008-03-26 <computer> [up] [copy]Acho que o que mais me impressionou até hoje a respeito do WinDbg é a sua capacidade de depuração remota. Não há nada como depurar problemas sentado confortavelmente na sua cadeira de programador em frente à sua mesa de programador.
Já é fato consumado que os maiores problemas da humanidade ocorrem sempre no cliente, com uma relação de dificuldade diretamente proporcional ao cargo ocupado pelo usuário da máquina que está dando problemas. Se esse cliente por acaso mora em um lugar tão tão distante, nada mais justo do que conhecermos algumas técnicas de depuração remota para continuar a mantê-lo tão tão distante.
O ambiente de desenvolvimento (em teoria) não se deve confundir com o ambiente de testes, um lugar onde o desenvolvedor deveria colocar o pé somente quando fosse chamado e quando existisse um problema na versão Release. Por isso e portanto a única coisa permitida em um ambiente de testes é (deveria ser) um servidor de depuração.
O servidor de depuração nada mais é do que um processo que deixa alguma porta aberta na máquina de testes para que o desenvolvedor consiga facilmente depurar problemas que ocorreram durantes os testes de produção. Ele pode ser facilmente configurado através da instalação do pacote Debugging Tools for Windows.
Existem alguns cenários muito comuns de depuração remota que serão abordados aqui. O resto dos cenários se baseia nos exemplos abaixo, e pode ser montado com uma simples releitura dos tópicos de ajuda do WinDbg sobre o assunto (procure por dbgsrv.exe).
No caso de VM ou máquina de teste do lado do desenvolvedor podemos supor que a máquina tem total acesso e controle do desenvolvedor. Tudo o que temos que fazer é iniciar um WinDbg na máquina-vítima e outro WinDbg na máquina-programador. O WinDbg da máquina-vítima deve ser iniciado no modo-servidor, enquanto o da máquina-programador no modo-cliente.
windbg -server tcp:port=6666 windbg -remote tcp:server=maquina-vitima,port=6666
A vantagem dessa técnica é que tanto o WinDbg da máquina-vítima quanto o da máquina-programador podem emitir comandos, e todos vêem os resultados. Uma possível desvantagem é que os símbolos devem estar disponíveis a partir da máquina-vítima.
Se for necessário, é possível convidar mais gente pra festa, pois o WinDbg permite se transformar em uma instância servidora pelo comando .server, que possui a mesma sintaxe da linha de comando. Para a comunicação entre todos esses depuradores ambulantes um comando muito útil é o .echo.
windbg -server tcp:port=6667 -remote tcp:server=maquina-vitima,port=6666 windbg -remote tcp:server=maquina-vitima,port=6666 0:000>.server tcp:port=6667 MAQUINA-PROGRAMADOR66\caloni (tcp 222.234.235.236:1974) connected at Mon Mar 24 11:47:55 2008 0:000>.echo E ae, galera? Como que a gente vai consertar essa &%$*&? 0:000>.echo Putz, sei lá. Acho que vou tomar mais café...
No ambiente do cliente é muito mais hostil; é salutar e recomendável utilizar um servidor genérico que não imprima coisa alguma na tela "do outro lado". Após iniciar o depurador na máquina que está dando o problema, o programador tem virtualmente uma série de comandos úteis que podem ser executados remotamente, como iniciar novos processos, se anexar a processos já existentes, copiar novas versões de executáveis, etc.
O nome do processo do lado servidor para modo usuário é dbgsrv.exe. Para o modo kernel é kdsrv.exe. Os parâmetros de execução, felizmente, são os mesmos que os do WinDbg (e CDB, NTSD e KD), o que evita ter que decorar uma nova série de comandos.
Pode parecer besteira falar isso aqui, mas ao depurar um sistema em modo kernel é necessário, é claro, é óbvio, é lógico, ter uma segunda máquina do lado servidor conectada por cabo serial ou firewire ou USB-Debug na máquina-vítima. Ainda que o Debugging Tools permita uma série de flexibilidades, o depurador em modo kernel vai rodar direto do kernel (duh), ou seja, está limitado pela implementação do sistema operacional. Além de que, para travar o processo do kernel, você tem que parar todo o sistema, e nesse caso não existe pilha TCP/IP.
Para iniciar o servidor de depuração e deixar as portas abertas para o depurador temos apenas que iniciar o processo dbgsrv.exe:
dbgsrv -t tcp:port=6666
Para iniciar o processo depurador, a sintaxe é quase a mesma, só que no lugar de remote especificamos premote:
windbg -premote tcp:server=maquina-vitima,port=6666
Caso não se saiba a porta usada para iniciar o servidor, ou queira-se listar todos os servidores disponíveis em uma determinada máquina, usa-se o comando -QR.
cdb -QR \\maquina-vitima
O exemplo acima utilizou uma conexão TCP para montar o ambiente de depuração remota, o que possibilita inclusive correção de problemas via internet. No entanto, nem sempre podemos nos dar ao luxo de abrir portas não-autorizadas, requisito mínimo para estabelecer a conexão com o depurador. Nesse caso, podemos configurar conexões pela porta serial, por pipes nomeados, por SSL. Se for realmente necessário usar a pilha TCP, mas o lado servidor possui um firewall, ainda assim é possível configurar este tipo de conexão com a opção clicon. Dessa forma, quem estabelece a conexão é o servidor, evitando que o cliente fique bloqueado de acessar o ambiente de depuração.
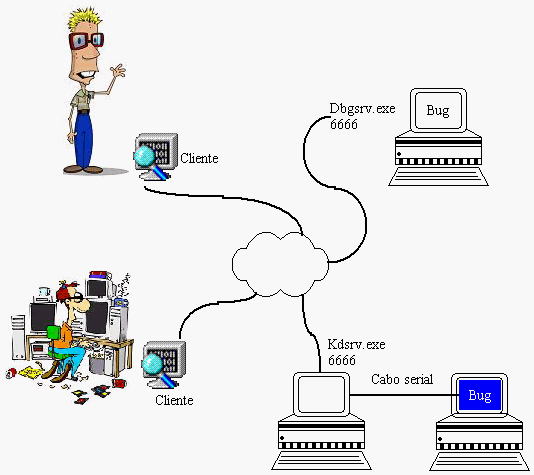
É importante notar que o dbgsrv.exe não é um depurador esperto, no sentido que ele não vai carregar os símbolos para você. Isso é importante na hora de definir qual estratégia utilizar, pois nem sempre os símbolos estarão disponíveis na máquina com problemas, e nem sempre estarão com o desenvolvedor.
Uma organização mais esperta dos ambientes de teste e desenvolvimento tomaria conta de outros problemas como símbolos e fontes com o uso de outras features poderosas do Debugging Tools como servidor de símbolos e servidor de fontes. Porém, a complicação envolvida na configuração desses dois me leva a crer que eles merecem um outro artigo. E é por isso que paramos por aqui.
# Backup de pobre
Caloni, 2008-03-28 <computer> [up] [copy]Como tudo na vida, o backup -- ato de fazer cópia(s) de segurança de dados considerados importantes -- para se tornar efetivo e transformador deve antes se tornar um hábito.
Hábitos, por definição, ao serem realizados repetidamente muitas vezes, podem se tornar poderosos catalisadores de tarefas, sejam elas cozinhar um bolo, compilar um programa ou fazer backups. Por isso é muito importante que o backup, antes de ser 100% seguro, seja 100% previsível e habitual.
Minhas restrições para que algo vire um hábito em minha vida, quando tarefas, são que a tarefa seja, antes de tudo:
- Simples de fazer. Quero conseguir efetuar a tafefa sem ter que toda vez preparar um ritual em noite de lua cheia, sacrificar uma virgem para os deuses pagãos e lembrar de todas as palavras proparoxítonas que terminam com x e rimam com fênix.
- Fácil de executar. É um complemento do primeiro item. Com isso eu quero dizer que, além de simples, eu não precise despender grande força e energia diariamente para efetuar a tarefa. Limpar uma pasta de arquivos temporários pode ser simples; mas é fácil?
- Fácil de lembrar. Se eu tenho que fazer um esforço mental diário tão grande para lembrar do que fazer então muito provavelmente será difícil transformá-lo em um hábito.
Passado por esse checklist, podemos montar um esquema tão simples que qualquer bobo que tem um blogue (por exemplo, eu) conseguirá executar diariamente, ou pelo menos quando tiver vontade. A freqüência dependerá se isso irá se transformar em um hábito ou não.
Ele pode não parecer, mas é beeem mais antigo do que parece. Nós, veteranos, que possuímos mais anos de vida em frente ao monitor que gostaríamos de admitir (copyright => DQ), usávamos o xcopy para copiar pastas e disquetes inteiros no MS-DOS, um sistema operacional predecessor do Windows Vista que vinha em preto e branco e sem User Account Control.
No entanto, esse pequeno grande aplicativo sobreviveu todos esses anos, atingiu a maioridade, e hoje permite a nós, programadores de mouse, fazer nossos backups com um simples arquivo de batch e um pouco de imaginação.
Aos mocinho e mocinhas presentes: os arquivos de batch, de extensão .bat ou .cmd, são, assim como o MS-DOS, coisas de veteranos do velho oeste. São arquivos de script que contém um conjunto de comandos que pode-se digitar manualmente na tela preta. Seu objetivo principal é otimizar e facilitar a digitação de tarefas complexas e torná-las mais simples, fáceis de executar e de lembrar.
O uso do programa pode ser aprendido dando-se uma olhada em sua ajuda (xcopy /?)
xcopy origem [destino] [opções]
Algumas opções bem úteis para efetuar cópias de segurança de arquivos modificados:
- /M copia somente arquivos com atributo de arquivamento; após a cópia, desmarca atributo. Ao escrever novamente em um arquivo copiado com esse método, o arquivo volta a ter o atributo de arquivamento, e irá ser copiado novamente se especificada essa opção. Se nunca mais for mexido, não será mais copiado.
- /D copia arquivos mais novos na origem. Não costumo usar pelos problemas que podem ocorrer em sistemas com horas diferentes, mas, dependendo da ocasião, pode ser útil. Também é possível especificar uma data de início da comparação.
- /EXCLUDE - permite excluir arquivo(s) de uma cópia coletiva. Isso pode ser muito útil se você não deseja gastar tempo copiando arquivo que são inúteis dentro de pastas que contém arquivos importantes. É possível especificar um arquivo que irá conter uma lista de nomes-curinga, um por linha, que irá servir como filtro da cópia. Teremos um exemplo logo abaixo.
- /E copia pastas e subpastas, mesmo que vazias. Essa opção é básica, e ao mesmo tempo essencial. Não se esqueça dela quando for criar seu script de backup!
- /C continua copiando, mesmo com erros. Se é mais importante copiar o máximo que puder do que parar no primeiro errinho de acesso negado, essa opção deve ser usada. É possível redirecionar a saída para um arquivo de log, que poderá ser usado para procurar por erros que ocorreram durante a operação.
- /Q não exibe nome de arquivos ao copiar. Às vezes imprimir o nome de cada arquivo na saída do prompt de comando acaba sendo mais custoso que copiar o próprio arquivo. Quando a cópia envolve muitos arquivos pequenos, é recomendável usar esta opção.
- /Y suprime perguntas para o usuário. Muito útil em arquivos batch, já que o usuário geralmente não estará lá para apertar enter quando o programa pedir.
- /Z copia arquivos da rede em modo reiniciável. Muito importante quando estiver fazendo backup pela rede. Às vezes ela pode falhar, e essa opção permite continuar após pequenas quedas de desempenho.
Para a cópia do patrimônio mais valioso de um programador, os fontes, podemos usar um conjunto bem bolado das 0pções acima, além de generalizar um script para ser usado em outras situações. Inicialmente vamos definir que queremos um backup que altere o atributo de arquivamento, sobrescreva cópias antigas e que possa ser copiado pela rede sem maiores problemas. Além disso, não iremos copiar as pastas Debug e Release existentes geradas pela saída de algum compilador (ex: saída do Visual Studio), nem arquivos temporários muito grandes (ex: arquivos de navegação de símbolos).
O resultado é o que vemos abaixo:
xcopy <pasta-origem> <pasta-destino> /M /E /C /Y /Z /EXCLUDE:sources.flt
O conteúdo de sources.flt (extensão escolhida arbitrariamente) pode ser o seguinte:
.obj .res .pch .pdb .tlb .idb .ilk .opt .ncb .sbr .sup .bsc \Debug\ \Release\
Só isso já basta para um backup simples, pequeno e fácil de executar. Só precisamos copiar a chamada ao xcopy em um arquivo de extensão .bat ou .cmd e executarmos sempre que acharmos interessante termos um backup quentinho em folha. Por exemplo, podemos manter os fontes do projeto atual em um pen drive e, ao acessarmos uma máquina confiável, rodar um backup que copia os arquvos-fonte para um ambiente mais seguro e estável.
Note que esse procedimento não anula a necessidade de termos um sistema de versionamento e controle de fontes. O backup é para aquelas projetos que demoram um tempinho para efetuar commit, projetos temporários ou então sistemas de controle de fonte distribuído, em que podemos ter inúmeras pastas com diversos branchs locais.
# EPA-CCPP 4: nossa comunidade ganhando forma
Caloni, 2008-03-29 <ccppbr> [up] [copy]Nesse último sábado ocorreu mais uma vez, como todos sabem, o Encontro de Programadores e Aficionados por C++, (in)formalmente apelidado de EPA-CCPP, de acordo com algumas conversas da nossa lista de discussão.
Mais uma vez, temos que dar uma salva de palmas e agradecer de coração a todos que colaboraram direta ou indiretamente para a realização do evento, que teve uma qualidade ainda maior que o último encontro.
E por falar em qualidade, as palestras dessa vez foram ricas em informação e diversidade, pois demonstraram diferentes visões que as pessoas possuem sobre a mesma coisa, que é o uso das linguagens C e C++ na vida real sobre alguma aplicação específica.
Infelizmente cheguei um pouco atrasado por problemas de localização (me perdi geral), mas consegui pegar a parte mais divertida da palestra do Strauss: o código.
TCP/IP via Boost.Asio (Rodrigo Strauss)
De uma maneira bem clara e direta, o palestrante nos mostrou como usar uma biblioteca de comunicação em redes feita de modo portável e extremamente antenada com o pensamento C++/STL de fazer as coisas. Partindo de um ponto de vista prático, deu dicas importantes para os iniciantes que desejarem começar a utilizá-la e passar mais facilmente pelo caminho das pedras que é aprender novas maneiras de fazer as mesmas coisas.
Na verdade, foi além, pois ao exemplificar seu uso no código do dia-a-dia chegou a usar um projeto próprio com dezenas de CPPs e centenas (milhares?) de linhas de código utilizando 100% boost para a comunicação em rede, sendo compilável e rodável nos ambientes Windows e Linux.
Programação em C para microcontroladores (Daniel Quadros)
Estava particularmente interessado nessa palestra para entender alguns truques e jogos-de-cintura necessários para utilizar a linguagem C em ambientes tradicionamente limitados em memória e poder de processamento. E, posso dizer, saí satisfeito.
O panorama traçado por DQ dos inúmeros tipos de microprocessadores, suas "linhagens" e diferentes arquiteturas nos permitiram entender as dificuldades em implementar e usar um compilador C para programar em sistemas embarcados. Mais ainda, fez ver a importância de, antes de programar, entender de fato como o hardware funciona para daí pensar em fazer algo útil com ele.
Ao final, um destaque especial para os conselhos finais sobre o desenvolvimento nessa área. Um conselho em específico ficou na minha mente, pois acredito que seja de extrema importância não só para sistemas embarcados, como para todo tipo de desenvolvimento: sempre pense em como será a depuração do sistema no projeto e em campo. Nunca se sabe onde e como o bug poderá ocorrer. Que ele existe, todos sabemos.
Desenvolvimento cross-platform em C++ com Qt (Basílio Miranda)
Algumas coisas que me impressionaram na palestra anterior sobre wxWidgets me impressionaram mais ainda pelas explicações do funcionamento do Qt em suas diversas plataformas suportadas. Aos poucos entendemos que desenvolver frameworks de ambiente gráfico multiplataforma nem sempre é aquela coisa bonita e abstrata que imaginamos possível de fazer com as maravilhas da linguagem C++. No fundo, muitas das coisas relacionadas com o funcionamento do núcleo desses sistemas é feito com alguns "remendos" sintáticos e semânticos que só os projetistas devem realmente saber explicar o porquê.
Por outro lado, o cuidado com a documentação e com os exemplos do ambiente Qt confortaram bastante o entusiasta que deseja explorar esse outro mundo de janelas além-Microsoft. Para os que reclamam do preço abusivo da licença da versão comercial, pode ser um alívio saber que projetos desenvolvidos com a licença GPL estão isentos de taxas, mesmo que comercializados. É uma questão de testar, medir e escolher alguma das alternativas.
Arquitetura e desenvolvimento de _drivers _com C para Windows (Fernando Silva)
Voltando para o mundo microsoftiano, o foco da palestra do Fernando foi explicar os princípios básicos por trás do funcionamento do sistema operacional Windows desde a época que ele era um prompt do DOS. Como pudemos ver, essa é uma condição sine qua non para o desenvolvimento de drivers para essa plataforma, visto que são componentes que interagem diretamente com o sistema operacional, de código fechado, e muitas vezes com o hardware, uma caixinha de surpresas.
Entre outras coisas, vimos como funciona a divisão entre os modos usuário e kernel, qual a organização da memória virtual, a importância dos níveis de prioridade de thread no desenvolvimento de drivers e, é claro, como podemos começar a desenvolver drivers desde já e gerar aquelas bonitas telas azuis.
Ao final pudemos ver que foi um tema que gerou interesse especial do grupo, pois houve várias perguntas, como por exemplo se existe uma maneira de proteger o sistema operacional dos drivers (isso poderia gerar um artigo). Imagino que a palestra foi direto ao encontro do espírito do evento, que falou principalmente sobre o que cada um de nós faz com C/C++. Muito provavelmente temos uma montanha de assuntos diferentes e complementares que poderão ser cobertos nos próximos encontros.
Sorteios, mais eventos e agradecimentos
No final, tivemos uma série de sorteios de livros-referência em C++, convites para o seminário C++ e algumas licenças de software. Por isso é importante lembrar aos que saíram antes que poderiam ter ganhado mais conhecimento, para que da próxima vez tentem apertar apenas mais um pouco seus compromissos.
Além das palestras, tivemos o relato de Fábio Galupo sobre o que foi o SD West 2008, o evento que reuniu alguns gurus do C++ para discutirem, entre outras coisas, o futuro da linguagem. Entre outras tantas coisas interessantes que ele nos trouxe, achei duas particularmente interessantes.
A primeira diz respeito à importância do bom uso de interfaces entre os programadores C++. Esse foi um tema levantado por Bjarne Stroustrup em uma de suas palestras, e é de fato algo preocupante em nossa linguagem, que não possui ainda uma organização tão produtiva quanto outros grupos de desenvolvedores.
A segunda diz respeito à necessidade de aprendermos outras linguagens. Na posição de desenvolvedores de sistemas que vão interagir com o mundo afora, é de suma importância que conheçamos nossos vizinhos mais próximos: desenvolvedores da camada acima que irão aproveitar o nosso código rápido e leve.
Após isso, ainda tive uma das mais felizes surpresas da minha vida: ganhei um exemplar do The C++ Programming Language, Special Edition, assinado por Bjarne Stroustrup!!! Foi um momento tão estupefato que nem sei direito o que eu fiz naquela hora, além de me levantar, agradecer mal e porcamente meus amigos da bancada (eu sei que para um presente desses não existe maneira de agradecer o suficiente), pegar meu livro e sentar novamente, ainda um pouco atordoado. Essas supresas podem matar!
Aproveito o final deste artigo para mais uma vez agradecer toda a organização do evento e, por que não, a todos da comunidade que puderam participar. Como alguém bem disse mais uma vez, a comunidade somos nós, e não um ou outro que costumam ser o porta-voz de nossos movimentos. Portanto, a todos que usam C e C++ de alguma maneira em algum momento de suas vidas, sintam-se honrados de participar do seleto grupo do EPA. Nós merecemos.
# Quarto encontro C++
Caloni, 2008-03-29 <ccppbr> [up] [copy]Para os desavisados de plantão, irá acontecer no dia 29 de março de 2008 o quarto encontro de programadores e aficionados C++. Mais detalhes no link anterior. Em suma, as palestras são estas:
Programação em C para microcontroladores (Daniel Quadros)
Você já pensou em programar componentes de hardware? Ou melhor: com uma linguagem de alto nível?? Sim, é possível, e de acordo com o Daniel, muito comum (ele usa mais que o próprio assembly). Nessa palestras teremos as dicas de como entrar nesse mundo não-tão-selvagem, e que merece toda a atenção dos que se importam com um dos trunfos da linguagem C: portabilidade.
Arquitetura e desenvolvimento de drivers com C para Windows (Fernando Silva)
Pode ser mais específico? Fernando mantém o maior e melhor blogue sobre drivers, aquelas coisinhas que fazem sua placa de vídeo 3D funcionar, para Windows no Brasil: o DriverEntry. Se você já acompanha seus artigos, essa é a chance de fazer aquelas perguntas que não saem da cabeça, mesmo que o assunto pareça fácil. Além, é claro, de poder entrar em outro mundo completamente fora da realidade da programação nacional.
TCP/IP via Boost.Asio (Rodrigo Strauss)
Voltemos ao C++ padrão ISO com ajuda da biblioteca mais poderosa de todos os tempos. Nessa conversa sobre C++, Strauss irá explicar as entranhas e o uso de uma biblioteca que, se não-padrão, pelo menos suportada em várias plataformas, o que por si só já é motivo para usá-la em seus projetos que usam rede (existe hoje em dia um projeto que não use?).
Desenvolvimento cross-platform em C++ com Qt (Basílio Miranda)
Mais um mundinho que, eu pelo menos, nunca me arrisquei a entrar. Dando continuidade ao tema "frameworks de interface com o usuário multiplataforma", Basílio Miranda agora explica como usar uma linguagem poderosa com um framework flexível, macetes e dicas.
Como assim "quanto custa"?
Sim, senhores, foi inevitável. Esse encontro será cobrado um pequeno valor, quase simbólico, mas que será usado para custear alguns gastos com a estrutura do evento que, pelo que promete, vai ser maior ainda que o anterior. Eu sei que encontros de entusiastas nunca deveriam ser cobrados. Porém, essa é uma experiência que temos que vivenciar com nosso grupinho C++ para termos argumentos contra e a favor dos dois moldes que serão escolhidos.
[2008-02] [2008-04]