- Corpo
- Pesquisas sobre a GINA
- VirtualBox
- Projeto-modelo
- Primeiros passos no VMware Workstation
- Segunda versão do Houaiss2Babylon
- O caso da função de Delay Load desaparecida
- O conhecido unresolved external
- Aprenda a usar sua API
- Entrevista com o Caloni no 'Do ZERO ao MESTRE'
- Antidebugging using exceptions (part one)
- Antidebugging using exceptions (part two)
# Corpo
Caloni, 2008-07-01 <quotes> <self> <now> [up] [copy]Onde quer que você esteja, esteja lá por inteiro.
Pense com todo o seu corpo.
Escute com todo o seu corpo.
A consciência do corpo nos mantém presentes.
Lutar contra o próprio corpo é lutar contra a sua própria realidade.
Em um organismo que funciona perfeitamente, uma emoção tem vida curta.
Quanto mais consciência tivermos do corpo, mais forte se torna o sistema imunológico.
Tolle, Eckhart (O Poder do Agora, 1997)
# Pesquisas sobre a GINA
Caloni, 2008-07-02 <computer> [up] [copy]Já sabemos o que é uma GINA. Afinal, todo mundo já viu uma antes. E sabemos que hoje em dia ela está morta.
No entanto, algumas pequenas mudanças foram feitas nela no Windows XP que ainda almaldiçoam o código de quem tenta reproduzir a famosa GINA da Microsoft. Nem todos chegam no final e morrem tentando.
Eu sou um deles.
Uma explicação sobre como funciona o processo de logon (local e remoto) e os componentes envolvidos está no artigo "How Interactive Logon Works" da Technet. Esse artigo irá abrir os olhos para mais detalhes que você gostaria de saber sobre nossa velha e querida amiga. Os desenhos explicativos estão ótimos!
Após essa leitura picante, podemos voltar ao feijão com arroz e começar de novo lendo a descrição de como funciona a GINA na Wikipedia, que nos remete a vários linques interessantes, entre os quais:
- A explicação documentada do MSDN de como funciona a interação entre Winlogon e GINA.
- Um ótimo artigo dividido em duas partes que explica como fazer sua própria customização de GINA. Foi nele que encontrei o retorno que precisava para emular a execução do Gerenciador de Tarefas baseado na digitação do Ctrl + Alt + Del. De brinde ainda vem uma GINA de exemplo para download.
A partir de mais algumas buscas e execuções do Process Monitor podemos encontrar os valores no registro que habilitam o Fast User Switching e a Tela de Boas Vindas do Windows XP. O valor da Tela de Boas Vindas é que habilita e desabilita a execução do Gerenciador de Tarefas baseado em Ctrl + Alt + Del. Esses itens são essenciais para os que quiserem criar uma réplica perfeita da GINA da Microsoft no Windows XP. Isso finaliza a minha busca.
Sempre tem mais. Se a máquina estiver no domínio essa opção não funciona. Porém, o WinLogon verifica se existe um valor chamado ForceFriendlyUi, que descobri graças ao Process Monitor. Aliado ao LogonType, sendo igual a 1, a Tela de Boas-Vindas é habilitada, mesmo em um ambiente com servidor de domínio.
Por último, claro, salvo se não existir o valor GinaDll dentro da chave do WinLogon. Se esse for o caso, o ForceFriendlyUi também não funciona. E é exatamente aí que uma GINA é instalada.
E eis que surge uma nova GINA.
# VirtualBox
Caloni, 2008-07-04 [up] [copy]O VirtualBox parece ser o concorrente mais próximo atualmente da VMWare. Descobrimos ele essa semana e resolvemos fazer alguns testes. O resultado foi bem animador.
Desenvolvido pela Sun Microsystems, as características do VirtualBox impressionam pelo cuidado que houve em torná-lo muito parecido com sua concorrente paga. Apenas para começar, ela suporta dispositivos USB, possui múltiplos snapshots e já suporta o modo do VMWare Fusion - chamado de "seamless mode" - que estará integrado na versão 7 da VMWare.
No entanto, entre as coisas que testamos (instalado em um Windows Vista SP1 como host), o que não funcionou já não agradou tanto. A lista de prós e contras ainda confirma a liderança da VMWare, pelo menos em qualidade:
Funcionalidade VMWare VirtualBox Snapshots Sim Sim. Mesma velocidade. USB Sim Sim. Não funcionou. Seamless Mode Não Sim. Clipboard Sim Sim. Não funcionou. Shared Folders Sim Sim. Erros de acesso. Ferramentas Guest Sim Sim. Pause Momentâneo Não Sim.
Além da tabela de testes acima, é necessário notar que por mas três vezes a VM simplesmente parou de responder, sendo necessário reiniciar o programa Host.
Em suma, o VirtualBox tem tudo para arrasar em futuras versões. Se, é claro, conseguir competir em qualidade com a VMWare que, no momento, é a líder em soluções de virtualização. Talvez por isso sua solução não seja tão barata.
# Projeto-modelo
Caloni, 2008-07-08 [up] [copy]É muito difícil construir um modelo de pastas que sirva para a maioria dos projetos que tivermos que colocar na fôrma. Ainda mais se esses projetos tiverem que futuramente fazer parte da mesma ramificação. Foi pensando em várias coisas que chegamos a uma versão beta que pode ajudar aqueles que ficam pensando durantes dias antes mesmo de colocar as mãos no código.
Antes de começar a pensar em como as pastas estarão alinhadas, é importante saber como funcionará o controle de código do seu projeto. Como eu disse sobre o Bazaar, a estrutura inicial permitirá a junção de dois projetos distintos se estes compartilharem do mesmo commit no começo de suas vidas.
Portanto, trate de iniciar a estruturação em um projeto-modelo que já contenha pelo menos um commit: o das pastas vazias já estruturadas.
bzr init _Template cd _Template bzr mkdir Docs bzr mkdir Interface bzr ... bzr ci -m "Projeto-modelo. Herde desse projeto sua estrutura inicial"
Estruturação proposta:
- Build. Essa pasta contém tudo que é necessário para compilar e testar o projeto como um todo. Idealmente a execução da batch build.bat deve executar todo o processo. Após a compilação, é de competência dos componentes na subpasta Tests fazer os testes básicos do projeto para se certificar de que tudo está funcionando como deveria.
- Common. Aqui devem ser colocados aqueles includes que servem para vários pontos do projeto. Está exemplificado pelo arquivo de versão (Version.h), pois todos os arquivos devem referenciar uma única versão do produto. Podem existir Outras definições básicas, como nome do produto, dos arquivos, etc. É aqui que são gravadas as interfaces que permitem dependência circular entre os componentes (e.g. Interface de componentes COM).
- Docs. Aqui deve ser colocada toda a documentação que diz respeito ao projeto. A organização interna ainda não foi definida, pois imagina-se ser possível usar diversas fontes, como doxygen, casos de uso, bugs, arquivos de projeto e UML. Foi exemplificado com o arquivo todo.txt e changes.txt, que deve ter sempre a lista de coisas a fazer e a lista de coisas já feitas, respectivamente, tendo, portanto, que ser sempre atualizados.
- Drivers. Essa é a parte onde ficam todos os componentes que rodam em kernel mode. Por se tratar de um domínio específico e muitas vezes compartilhar código-fonte de maneira não-heterodoxa (e.g. sem uso de LIBs), faz sentido existir uma pasta que agrupe esses elementos. Dentro da pasta existem subpastas para cada driver, exemplificados em Driver1 e Driver2.
- Install. Todas as coisas relacionadas com instalação, desinstalação e atualização do software deve vir nessa pasta. Foi reservada uma subpasta para cada item, não sendo obrigatória sua divisão. Também existe uma pasta de DLLs, onde possivelmente existam telas personalizadas e biblioteca de uso comum pelos instaladores (o desinstalador conversa com o instalador e assim por diante).
- Interface. Todas as telas de um programa devem ser colocadas nessa pasta. Essa é uma divisão que deve ser seguida conceitualmente. Por exemplo, se existir um gerenciador de alguma coisa no produto, as telas do gerenciador e o comportamento da interface ficam nessa pasta, mas o comportamento intrínseco do sistema (regras de negócio) devem ficar em Libraries. Para exemplificar o uso, foram criadas as Interface1 e Interface2.
- Libraries. O ponto central do projeto, deve conter o código mais importante. Imagine a pasta Libraries como a inteligência de um projeto, de onde todos os outros componentes se utilizam para que a lógica do software seja sempre a mesma. As outras partes do projeto lidam com aspectos técnicos, enquanto o Libraries contém as regras abstratas de funcionamento. Opcionalmente ela pode ser estática ou dinâmica, caso onde foi criada a subpasta DLLs. Porém, elas devem ser divididas por função em bibliotecas estáticas, como foi exemplificado em Library1 e Library2.
- Resources. A origem de todas as imagens, sons, cursores, etc de um projeto devem residir primeiramente na pasta Resources. A divisão interna desse item fica a critério do designer responsável, pois ele pode dividir tanto por função (Install, Interface) quanto por elementos (Images, Sounds).
- Services. Além dos drivers e das interfaces alguns projetos necessitam de processos "invisíveis" que devem fazer algo no sistema. Isso inclui serviços do Windows, GINAs, componentes COM e coisas do gênero. Devem ser colocados nessa pasta e distribuídos como no exemplo, em Service1 e Service2.
- Tools. Além dos componentes essenciais para o funcionamento do software também existem aqueles componentes que fornecem mais poder ao usuário, ao pessoal do suporte ou ao próprio time de desenvolvimento. Essas são as ferramentas de suporte que permitem a fácil identificação de erros no programa ou a configuração mais avançada de um item que a Interface não cobre. Adicionalmente foi colocada a subpasta Develop, que deve conter ferramentas usadas estritamente durante a fase de desenvolvimento.
Todos os componentes que disponibilizarem unidades de testes devem conter uma pasta Tests dentro de si. Essa padronização permite facilmente a localização de testes internos aos componentes. Além disso, os arquivos executáveis de testes devem sempre terminar seu nome com Test, o que permite a automatização do processo de teste durante o build.
Acredito que este esboço esteja muito bom. É o modelo inicial que estou utilizando nos projetos da empresa e de casa.
# Primeiros passos no VMware Workstation
Caloni, 2008-07-10 <computer> [up] [copy]Como uma ferramenta essencial que uso todos os dias da minha vida de programador, sou obrigado a falar neste blogue sobre a VMware, ferramenta que tem me salvado algumas centenas de horas de depuração, testes e alguns cabelos brancos (a mais).
Para os que não sabem, o VMware é um software de virtualização que permite rodar diversos sistemas operacionais secundários (chamados de convidados, ou guests) em cima do sistema operacional primário (chamado de hospedeiro, ou host). Para isso ele utiliza uma técnica muito interessante conhecida como virtualização, onde o desempenho da máquina virtual chega bem próximo da máquina nativa em que estamos rodando, ainda mais se instalados os apetrechos de otimização (vide VMware Tools) dentro dos sistemas operacionais convidados.
O VMware, diferente de alguns outros programas de virtualização, não é gratuito. No entanto, o tempo despendido pela equipe da VMware em tornar esta a solução a de melhor qualidade (opinião pessoal de quem já mexeu com Virtual PC e pouco de VirtualBox) está bem cotado, sendo que seu preço é acessível pelo desenvolvedor médio. Pior que o preço da VMware com certeza será o dos sistemas operacionais convidados, se estes forem da Microsoft, que obriga cada instância do Windows, seja hospedeiro ou convidado, a possuir uma licença separada. Se rodar um Windows XP como hospedeiro e um Vista e 2000 como convidados vai desembolsar pelo menos o quíntuplo da licença da VMware.
No entanto, não entremos em mais detalhes financeiros. Os detalhes técnicos são mais interessantes.
A instalação é simples e indolor, sendo constituída de cinco ou seis botões de next. O resto, e mais importante, é a instalação de um sistema operacional dentro de sua primeira máquina virtual. Outro assistente existe nessa fase para guiá-lo através de suas escolhas que irão configurar sua futura máquina.
Vejamos um pouco sobre redes.
- Use bridged networking. É criada uma conexão real através de uma ponte feita em cima de uma placa de rede da máquina real. É usado um IP diferente da máquina real e se comporta como uma outra máquina qualquer na rede.
- Use NAT. As conexões são criadas usando o IP do sistema operacional hospedeiro. Para isto acontecer é usado o conhecido esquema de NAT, onde um único IP externo pode representar n IPs internos de uma rede (nesse caso, a rede virtual formada pelas máquinas virtuais de uma mesma máquina real).
- Use host-only networking. O IP usado nessa conexão é diferente da máquina real, mas só é enxergada por ela e por outras VMs localizadas na mesma máquina hospedeira. Muito útil para isolar um teste de vírus, quando se precisa de uma rede mas não podemos usar a rede da empresa inteira.
Imagine uma VM (Virtual Machine) como uma máquina de verdade, onde podemos dar boot, formatar HDs (virtuais ou reais), colocar e remover dispositivos. Tendo isso em mente, fica simples entender o que funciona por dentro de sua console, ou seja, a tela onde vemos a saída da virtualização.
Vejamos um pouco sobre discos virtuais.
Os HDs que criamos para nossas VMs são arquivos lógicos localizados em nosso HD real. A mágica em que o sistema operacional virtual acessa o disco virtual como se fosse de verdade é feita pela VMware, inclusive a doce ilusão que ele cotém 80 GB, enquanto seu arquivo-repositório ocupa meros 5 GB no disco. Nas edições novas do software, é possível mapear um HD virtual e exibi-lo na máquina real.
Se você dispõe do CD de instalação de um sistema operacional, por exemplo, Windows XP, basta inseri-lo no CD virtual de sua VM. Ela aceita também imagens ISO, se for o caso. Lembre-se apenas que ele terá que ser "bootável", do contrário é necessário um disquete de boot.
Vejamos um pouco sobre BIOS.
A sua VM emula todo o comportamento de uma máquina real. Ela, portanto, contém uma BIOS, feita pela VMware. Essa BIOS possui as mesmas opções interessantes de ordem de boot (primeiro o disquete, depois o HD, etc) e escolha de dispositivo de boot (tecla ESC).
A instalação do sistema operacional segue os mesmos passos que a instalação do sistema operacional de qualquer máquina de verdade.
Vejamos um pouco sobre as teclas mágicas.
- Entrar o foco na VM. Digite Ctrl + G. Todos seus movimentos de teclado e mouse só irão funcionar dentro da máquina virtual, exceto o Ctrl + Alt + Del, exclusividade do sistema de autenticação do Windows.
- Tirar o foco da VM. Digite Ctrl + Alt. Todos seus movimentos de teclado e mouse passam a ser do SO hospedeiro.
- Ctrl + Alt + Del dentro da VM. Use Ctrl + Alt + Insert. Ele terá o mesmo efeito que um CAD, independente em que tela estiver em sua VM.
Após feita a instalação, você terá um sistema operacional rodando dentro de um sistema operacional. Isso não é legal?
A primeira coisa a fazer em sua VM com SO recém-instalado é criar um snapshot, ou seja, salvar o estado atual de sua máquina virtual. Ao fazer isso, se fizer alguma coisa dentro da VM que possa se arrepender depois, basta voltar para o estado que salvou anteriormente. A VMware permite criar quantos snapshots precisar (basta ter espaço em disco). Ela permite que você crie novas máquinas virtuais a partir de um estado de uma VM já criada, o que pode economizar todo o tempo de montar do zero outra VM ou copiar o disco virtual.
- Abrir os seus e-mails suspeitos. Não tenha mais medo de sujar seu computador com e-mails de conteúdo duvidoso. Crie um estado seguro em sua VM através de um snapshot (fotografia de estado da máquina virtual) e execute os anexos mais absurdos. Depois basta voltar para o estado seguro.
- Testes que costumam alterar o estado da máquina. Driver, GINA ou serviço novo? Que tal usar uma VM para fazer os testes iniciais e parar de reformatar o Windows?
As VMs possibilitam um mundo de utilidades que o mundo ainda está descobrindo. Para nós, desenvolvedores, a maior vantagem de tudo isso é termos nossos ambientes de testes mais bizarros facilmente configurados no conforto de uma caixinha de areia.
# Segunda versão do Houaiss2Babylon
Caloni, 2008-07-14 <computer> <projects> [up] [copy]Depois de vários comentários de pessoas tendo problemas em converter seus dicionários Houaiss para o formato Babylon, resolvi criar vergonha na cara e dar uma pequena melhora na versão beta do conversor.
Agora a maioria dos erros que houver será descrita por uma mensagem no seguinte formato:
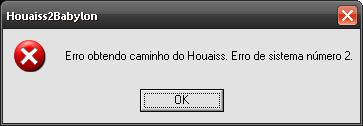
O primeiro erro acima ocorre principalmente se não houver algum Houaiss instalado que o programa possa detectar. Resolva este problema comprando um.
Abaixo segue a função criada para exibir essas mensagens:
void MessageError(DWORD err, PCSTR msg, ...)
{
CHAR errBuffer[100];
CHAR msgBuffer[ERR_STR_BUF_SIZE];
va_list vaList;
va_start(vaList, msg);
vsprintf(msgBuffer, msg, vaList);
va_end(vaList);
sprintf(errBuffer, " Erro de sistema número %d.", (int) err);
strcat(msgBuffer, errBuffer);
MessageBox(NULL, msgBuffer, STR_PROJECT_NAME, MB_OK | MB_ICONERROR);
}
Se você notou, a função acima pode receber um número de argumentos variáveis para formatar a string da mensagem principal do erro, além de exibir seu código. Essa mágica pode ser feita usando-se o cabeçalho padrão "stdarg.h". Através dele temos acesso ao tipo va_list, que representa uma lista de argumentos variáveis.
Pela convenção de chamada da linguagem C (e C++), quem desmonta a pilha é o chamador. Sendo assim, a função chamada não precisa conhecer o número de argumentos com que foi chamado.
A função de formatação de string é uma variante do conhecidíssimo printf, na versão que recebe um tipo va_list. Muito útil para formatação de logs.
A versão beta do Houaiss2Babylon está para sair. Não estarei mais atualizando o saite do projeto no LaunchPad. Aguardem por mais novidades no próprio blogue.
# O caso da função de Delay Load desaparecida
Caloni, 2008-07-16 <computer> [up] [copy]Todos os projetos do Visual Studio 6 estavam compilando normalmente com a nova modificação do código-fonte, uma singela chamada a uma função da DLL iphlpapi.dll. No entanto, ainda restava a compilação para Windows 95, um legado que não era permitido esquecer devido ao parque antigo de máquinas e sistemas operacionais de nossos clientes.
Ora, acontece que a função em questão não existe em Windows 95! O que fazer?
Essa é uma situação comum e controlada, que chega a ser quase um padrão de projeto: funções novas demais. A saída? Não chamar a função quando o sistema não for novo o suficiente. Isso pode ser resolvido facilmente com uma chamada a GetVersion.
Porém, um outro problema decorrente dessa situação é que a função chamada estaticamente cria um link de importação da DLL para o executável. Ou seja, uma dependência estática. Dependências estáticas necessitam ser resolvidas antes que o programa execute, e o carregador (loader) de programas do sistema é responsável por essa verificação.
Para verificar a existência de todas as DLLs e funções necessárias para nosso programa podemos utilizar o mundialmente conhecido Dependency Walker:
depends meu_executavel.exe
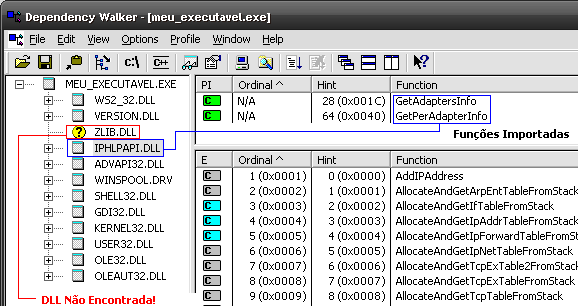
Se a função ou DLL não existe no sistema, o seguinte erro costuma ocorrer (isso depende da versão do Sistema Operacional):

Mas nem tudo está perdido!
Existe uma LIB no Visual Studio que serve para substituir a dependência estática de uma DLL pela verificação dinâmica da existência de suas funções quando, e se, for executada a função no programa.
Essa LIB contém algumas funções-chave que o Visual Studio utiliza ser for usado o seguinte parâmetro de compilação:
/delayload:iphlpapi.dll
A função principal se chama "__delayLoadHelper@8", ou seja, é uma função com convenção de chamada WINAPI (stdcall) que recebe dois parâmetros.
Isso costuma sempre funcionar, sendo que tive uma grande surpresa com os seguintes erros de compilação na versão do programa que deve ser executada em Windows 95:
--------------------Configuration: Project - Win32 Win95 Release-------------------- Linking... iphlpapi.lib(iphlpapi.dll) : error LNK2001: unresolved external symbol ___delayLoadHelper@8 release/meu_executavel.exe : fatal error LNK1120: 1 unresolved externals Error executing link.exe. meu_executavel.exe - 3 error(s), 0 warning(s)
Isso, é claro, depois de ter checado e rechecado a existência da LIB de Delay Load na lista de LIBs a serem lincadas:
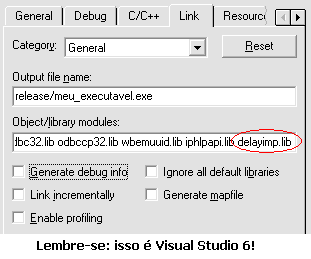
Acontece que eu conheço algumas ferramentas que podem sempre me ajudar em situações de compilação e linque: Process Monitor e dumpbin. O Process Monitor pode ser usado para obter exatamente a localização da LIB que estamos tentando verificar:
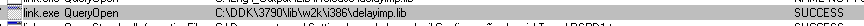
Após localizar o local, podemos listar seus símbolos, mais precisamente a função "delayLoadHelper":
C:\DDK\3790\lib\w2k\i386>dumpbin /symbols delayimp.lib | grep delayLoadHelper 108 00000000 SECT3C notype () External | ___delayLoadHelper2@8
A análise mostra que a função possui um "2" no final de seu nome, causando o erro de linque.
Essa função, pelo visto, tem mudado de nome desde o Visual C++ 6, o que fez com que LIBs mais novas não funcionassem com essa versão do Visual Studio.
Para sanar o problema, existem duas coisas que podem ser feitas:
1. Usar a delayimp.lib antiga. Isso não exige nenhuma mudança no código.
2. Criar uma função delayLoadHelper como wrapper. Isso exige a escrita de código. O código-fonte dessa função está disponível no diretório Include do Visual Studio, e pode ser adaptada para versões antigas.
Nessa sessão de depuração você aprendeu como usar o Process Monitor para rastrear arquivos usados na compilação e como listar símbolos de LIBs que são usadas para lincar o programa.
# O conhecido unresolved external
Caloni, 2008-07-18 <computer> [up] [copy]O artigo anterior mostrou que nem sempre as coisas são simples de resolver, mas que sempre existe um caminho a seguir e que, eventualmente, todos os problemas se solucionarão.
Porém, resolver um problema por si só não basta: é preciso rapidez. E como conseguimos rapidez para resolver problemas? Um jeito que eu, meu cérebro e o Dmitry Vostokov conhecem é montando padrões.
Um padrão nos ajuda a não pensar novamente em coisas que sabemos a resposta, de tantas vezes que já fizemos. Só precisamos saber o caminho para resolver determinado problema.
Mesmo assim, existem diversos caminhos a percorrer. Até mesmo para um singelo e batidíssimo "unresolved external".
Primeiro passo: você está usando a LIB correta?
O erro mais comum é usar uma LIB onde não está a função que estamos usando, ou usar uma versão diferente da mesma LIB que não contém a função, ou contém, mas com assinatura (parâmetros da função) diferentes. Isso pode ser verificado no código-fonte da LIB, se disponível, ou então pelo uso do dumpbin, como já vimos anteriormente.
Dica extra: às vezes você pensa que está usando uma LIB em um determinado caminho, mas o linker achou a LIB primeiro em outro lugar. Para se certificar que está verificando a mesma LIB que o linker achou, use o Process Monitor.
Às vezes, porém, não estamos usando a função diretamente e não conhecemos quem a usaria. Para isso que hoje em dia os compiladores mais espertos nos dizem em que parte do código foi referenciado a tal função:
test.obj : error LNK2019: unresolved external symbol func referenced in function main
É sábio primeiro inspecionar a função que referencia, para depois entender porque ela não foi encontrada. Mesmo parecendo diferente, essa operação faz parte do primeiro passo, que é identificar a origem.
Segundo passo: você digitou direito?
Parece estúpido, mas às vezes é esse o caso. Essa é a segunda coisa a fazer porque não é tão comum quanto a primeira, visto que hoje em dia é rotina colocarmos as funções em um header e incluirmos esse cabeçalho em nosso código-fonte (em C++, praticamente obrigatório). Se houvesse discrepância entre o nome da função chamada e o nome da função existente, provavelmente teríamos um erro de compilação ("função não encontrada") antes do erro de linking.
Terceiro passo: tente incluir a função diretamente no seu código
Se a LIB não está cooperando, e der pouco trabalho, experimente incluir a função inteira (ou o cpp) dentro do seu projeto, para linkar diretamente. Se funcionar, então existe alguma diferença de compilação entre os dois projetos (o seu e o da LIB) para que haja uma divergência no nome procurado. Procure nas opções de projeto.
Quarto passo: comece de novo!
Sempre que nos deparamos com um problema que aos poucos vai consumindo o nosso tempo, tendemos a gastar mais tempo fazendo coisas inúteis que sabemos que não irá adiantar de nada. Às vezes fazer brute force pode dar certo. Outras vezes, seria melhor recomeçar a pesquisa e tentar entender de fato o que está acontecendo na compilação. Em outras palavras: gastar o seu tempo pensando pode ser mais produtivo do que agir instintivamente.
# Aprenda a usar sua API
Caloni, 2008-07-22 [up] [copy]É conhecido que uma das desvantagens de se programar diretamente em Win32 API é a dificuldade de se entender os parâmetros e o retorno das funções. Concordo em parte. Constituída de boa documentação, parte da culpa dos programas mal-feitos reside na preguiça do programador em olhar a documentação por completo. A Win32 API está longe de ser perfeita, mas pelo menos está razoavelmente documentada, e é na leitura atenta da documentação que iremos encontrar as respostas que precisamos para que o programa funcione.
Vejamos alguns exemplos. O código abaixo parece bem razoável:
#include <windows.h>
int main()
{
HANDLE hFile = CreateFile("c:\\tests\\myfile.txt", GENERIC_READ,
FILE_SHARE_READ, NULL, OPEN_EXISTING, 0, NULL);
if( hFile )
{
DWORD read = 0;
CHAR buffer[100];
if( ReadFile(hFile, buffer, sizeof(buffer), &read, NULL) )
{
WriteBuffer(buffer);
}
CloseHandle(hFile);
}
}
No entanto, está errado.
É fato que a maioria das funções que retornam handles retornam NULL para indicar o erro na tentativa de obter o recurso. Ao comparar o retorno com NULL, o programador geralmente faz uma chamada a GetLastError para saber o que aconteceu. No entanto, uma das funções mais usadas, a CreateFile, não retorna NULL, mas INVALID_HANDLE_VALUE.
Sendo assim, o código acima deveria ser:
if( hFile != INVALID_HANDLE_VALUE )
GetVersion também é uma função que muitos erraram. Erraram tanto que eles fizeram uma nova versão menos complicada. Como está escrito no MSDN: "The GetVersionEx function was developed because many existing applications err when examining the packed DWORD value returned by GetVersion, transposing the major and minor version numbers."
O motivo de tantos erro pode ter sido o fato que o valor retornado é uma estrutura de bits dentro de um DWORD, coisa que nem todos programadores C sabem lidar muito bem, e o fato de ser uma função muito utilizada por todos (pegar a versão do sistema operacional).
Eis a tabela de campos do retorno de GetVersion:
Platform High-order bit Next 7 bits Low-order byte ------------------------------------- -------------- ------------ -------------- Windows NT 3.51 0 Build number 3 Windows NT 4.0 0 Build number 4 Windows 2000 or Windows XP 0 Build number 5 Windows 95, Windows 98, or Windows Me 1 Reserved 4 Win32s with Windows 3.1 1 Build number 3
Mesmo que não seja tão difícil, pode ser ambíguo. Por exemplo, como saber se o Windows é 95, 98 ou ME?
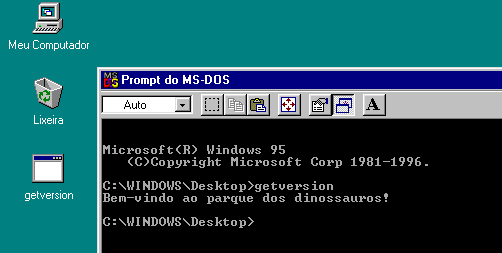
O código abaixo, muito usado por todos que suportam ainda o Windows mais velhinhos, verifica se estamos rodando em plataforma NT ou 9x.
#include <windows.h>
#include <stdio.h>
int main()
{
DWORD winVer = GetVersion();
BOOL isPlatformNT = winVer >= 0x80000000 ? FALSE : TRUE;
if( isPlatformNT )
printf("Plataforma NT\n");
else
printf("Bem-vindo ao parque dos dinossauros!\n");
return isPlatformNT ? 1 : 0;
}
Nem sempre o handle que obtemos é fechado com CloseHandle. As funções abaixo retornam handles que devem ser desalocados com as funções à direita:
Função que obtém recurso Função que libera recurso ------------------------ ------------------------- LoadLibrary FreeLibrary RegOpenKey RegCloseKey GetDC ReleaseDC BeginPaint EndPaint
Sempre tem mais exemplos. Algumas dicas úteis para o dia-a-dia de um programador Win32 API são:
- Leia a documentação
- Se atente aos valores de retorno em caso de sucesso e erro
- Leia sempre a seção remarks pelo menos uma vez; ela explica como desalocar recursos
- Releia a documentação
Às vezes uma singela chamada de uma função de autenticação pode nos fazer preencher uma estrutura de 20 membros, sendo que seis deles são obtidos com mais sete chamadas de funções, todas com direito a desalocar recursos no final. O importante é sempre manter a calma, o espírito de aprendizado e aventura. Afinal, quem mandou não fazer software de telinha?
# Entrevista com o Caloni no 'Do ZERO ao MESTRE'
Caloni, 2008-07-24 [up] [copy]Há muito pouco tempo atrás surgiu um blogue de um programador com o desejo de aprender C++ em seis meses. Ele entrou em contato comigo para divulgar seu trabalho, e lhe disse que na internet seu trabalho se divulga por si só. E é verdade. No entanto, não contente, ele me pediu para responder um questionário no estilo entrevista. Não sei se o resultado foi satisfatório, mas pelo menos foi curioso. Foram perguntas simples e respostas mais simples ainda.
Para os que quiserem ler a entrevista e/ou acompanhar as desventuras de um programador com pressa, dê uma olhada no artigo em "Do ZERO ao MESTRE em 6 meses", um blogue recém-nascido.
Update de 2020-03-14: estava corrigindo posts antigos e ao chegar neste fui verificar o blog do Rafael Becker. Ele havia parado por uns anos e voltou a postar em 2014. Fico feliz em saber que ele seguiu carreira e hoje trabalha com o que gosta. =)
# Antidebugging using exceptions (part one)
Caloni, 2008-07-28 <computer> <projects> <english> <antidebug> [up] [copy]A debugger puts breakpoints to stop for a moment the debuggee execution. In order to do this it makes use of a well known instruction: int 3. This instruction throws an exception - the breakpoint exception - that is caught by the operating system and bypassed to the handling code for this exception. For debuggee processes this code is inside the debugger. For free processes this code normally doesn't exist and the application simply crashs.
The main idea in this protection is to take care these exceptions during the application execution. Doing this, we can make use of this fact and, in the handling code, run the protected code. The solution here looks like a script interpreter. It consists basically of two threads: The first one read an instructions sequence and tells the second thread to run it step to step. In order to do this the second thread uses a small functions set with well defined code blocks. Here's the example in pseudocode:
// the well-defined functions are functional blocks of code and have
// the same signature, allowing the creation of a pointer array to them
void WellDefinedFunction1( args );
void WellDefinedFunction2( args );
void WellDefinedFunction3( args );
//...
void WellDefinedFunctionN( args );
// this thread stays forever waiting execution commands from some
// well-defined function. the parameter that it receives is the function number
void ExecutionThread()
{
// 2. ad aeternum
while( true )
{
// 5. it runs some well-defined function by number
ExecuteWellDefinedFunction( functionNumber );
}
}
// the well-defined functions script is an integer array indicating
// the number for the next function that is going to be called
int FunctionsToBeCalled[] = { 3, 4, 1, 2, 34, 66, 982, n };
int Start()
{
// 1. we create the thread that is going to run commands
CreateThread( ExecutionThread );
// 3. for each script item (each function number)
for( int i = 0; i < sizeof(FunctionsToBeCalled); ++i )
{
// 4. tells the thread to run the function number N
TellExecutionThreadToExecuteWellDefinedFunction( FunctionToBeCalled[i] );
}
// 6. end of execution.
return 0;
}
The protection isn't there yet. But it will as intrinsic part of the execution thread. All we need to do is to add a exception handling and to throw lots of int 3. The thrown exceptions are caught by a second function that runs the instruction before to returning:
// filter exceptions that were thrown by the thread below
DWORD ExceptionFilterButExecuteWellDefinedFunction()
{
// 5. run some well-defined function by number
ExecuteWellDefinedFunction( number );
return EXCEPTION_EXECUTE_HANDLER; // goes to except code
}
// this thread stays forever waiting execution commands from a
// well-defined function. its "parameter" is the function number
void ExecutionThread()
{
// 2. ad aeternum
while( true )
{
__try
{
__asm int 3 // breakpoint exception
// it stops the debugger if we have an attached debugger in
// the process, or throws an exception if there is no one
}
__except( ExceptionFilterButExecuteWellDefinedFunction() )
{
// it does nothing. here is NOT where is the code (obvious, huh?)
}
Sleep( someTime ); // give some time
}
}
The execution thread algorithm is the same. Just the point where each instruction is executed depends to the exception throw system. Note that this exception has to be thrown in order to the next instruction run. This is fundamental, since this way nobody can just rip of the int 3 code to avoid the exception. If one does that, so no instruction will be executed at all.
In practice, if one tries to debug such a program one will have to deal with tons of exceptions until find out what's happening. Of course, as in every software protection, is's not definitive; it has as a purpose to make hard the reverse engineering understanding. That's not going to stop those who are really good doing that stuff.
Nothing is for free
The price paid for this protection stays on the source code visibility and understanding, compromised by the use of this technique. The programming is state machine based, and the functions are limited to some kind of behavior standard. So much smaller the code blocks inside the minifunctions, so much hard the code understanding will be.
The example bellow receives input through a command prompt and maps the first word typed to the function that must be called. The rest of the typed line is passed as arguments to the functions. The interpreter thread reads the user input and writes into a global string variable, at the same time the executor thread waits the string to be completed to starts the action. It was used the variable pool to let the code simpler, but the ideal would be some kind of synchronise, just like events, by example.
/** @brief Sample demonstrating how to implemente antidebug in a code exception based.
@date jul-2007
@author Wanderley Caloni
*/
#include <windows.h>
#include <iostream>
#include <map>
#include <sstream>
#include <string>
#include <stdlib.h>
using namespace std;
// show available commands
bool Help(const string&)
{
cout << "AntiDebug Test Program\n"
<< " Echo string to be printed\n"
<< " System command [params]\n"
<< " Quit\n\n";
return true;
}
// run system/shell command
bool System(const string& cmd)
{
system(cmd.c_str());
return true;
}
// print string to output
bool Echo(const string& str)
{
cout << str << endl;
return true;
}
// quit program
bool Quit(const string&)
{
exit(0);
return false;
}
// minifunctions array
bool (* (g_miniFuncs[]) )(const string&) = { Help, System, Echo, Quit };
// "minifunction -> index" mapping
map<string, int> g_miniFuncIdx;
// start minifunctions mapping
void InitializeMiniFuncIdx()
{
g_miniFuncIdx["Help"] = 0;
g_miniFuncIdx["System"] = 1;
g_miniFuncIdx["Echo"] = 2;
g_miniFuncIdx["Quit"] = 3;
}
// last line read from input
string g_currentLine;
// how much time are we going to wait for the next line?
const DWORD g_waitTime = 1000;
// run minifunctions
DWORD FilterException()
{
DWORD ret = EXCEPTION_CONTINUE_EXECUTION;
if( ! g_currentLine.empty() )
{
istringstream line(g_currentLine);
g_currentLine.clear();
string function;
string params;
line >> function;
getline(line, params);
// 5. run some well-defined function by number
if( ! g_miniFuncs[g_miniFuncIdx[function] ](params) )
ret = EXCEPTION_CONTINUE_SEARCH;
}
return ret;
}
DWORD WINAPI AntiDebugThread(PVOID)
{
InitializeMiniFuncIdx(); // start minifunction mapping
// 2. ad aeternum (or almost)
while( true )
{
//FilterException();
__try // the extern try waits for an exit command
{
__try // the intern try stays generating exceptions continuously
{
__asm int 3
}
// FilterException is the function who runs minifunctions
__except( FilterException() )
{
// we can put some fake code here
}
}
__except( EXCEPTION_EXECUTE_HANDLER )
{
break; // get out from ad aeternum (to the limbo?)
}
Sleep(g_waitTime);
}
return ERROR_SUCCESS;
}
/** and God said: 'int main!'
*/
int main()
{
DWORD ret = ERROR_SUCCESS;
DWORD tid = 0;
HANDLE antiDebugThr;
// 1. we create the thread that is going to run the commands
antiDebugThr = CreateThread(NULL, 0, AntiDebugThread, NULL, 0, &tid);;
if( antiDebugThr )
{
// 3. for each item in the script (function numbers)
while( cin )
{
cout << "Type something\n";
// 4. tells the thread to run the function number N
getline(cin, g_currentLine);
if( WaitForSingleObject(antiDebugThr, g_waitTime * 2) != WAIT_TIMEOUT )
break;
}
GetExitCodeThread(antiDebugThr, &ret);
CloseHandle(antiDebugThr), antiDebugThr = NULL;
}
// 6. end of execution.
return (int) ret;
}
The strength in this protection is to confound the attacker easily in the first steps (days, months...). Its weakness is the simplicity for the solution, since the attacker eventually realize what is going on. It is so easy that I will let it as an exercise for my readers.
In the next part we will se an alternative to make the code clearer and easy to use in the every day by a security software developer.
# Antidebugging using exceptions (part two)
Caloni, 2008-07-30 <computer> <projects> <english> <antidebug> [up] [copy]In the first article we saw how it's possible to spoof the debugger through exceptions and let the attacker lose some considerable time trying to unbind the program from the fake breakpoints. However, we saw also that this is a difficult solution to keep in the source code, besides its main weakness to be easily bypassed if discovered. Now it's time to put things easier to support and at the same time to guarantee tough times even if the attacker discover what is going on.
The upgrade showed here still uses the exception throwing intrinsically, but now it doesn't depends on the code division in minifunctions and minicalls. Instead, we just need to get code traces and put them inside a miraculous macro that will do everything we want. This, of course, after some "hammer work" that will be explained here.
// Go back to place pre-defined by the restoration point.
void LongJmp(restorePoint)
{
// Here we will generate an exception to make things difficult.
// @todo Make a breakpoint exception and catch it.
// 3. We return to the if without using the stack, but from the restoration point.
GoBackToTheStartFunction(restorePoint);
}
// Here everything begins.
int Start()
{
// Obs.: follow the agreement flow according to the numbers.
// 1. First pass: we define a restoration point to the return of LongJmp.
// 4. Second pass: we go back from the LongJmp function, but this time we get into the else.
if( RestorePointDefined() == Defined )
{
// 2. We call the function that will return to the if.
LongJmp( if );
}
else
{
// 5. Call the real function, our true target.
CallTheUsefulFunction();
}
// 6. End of execution.
return 0;
}
The solution above is explained in pseudocode to make things clearer. Notice that exist some kind of invisible return, not stack based. To handle it, however, we can use the good for all C ANSI standard, using the setjmp (step one) and longjmp (step 3). To understand the implementation for theses functions running on the 8086 platform we need to get the basic vision of the function calls in a stack based environment (the C and Pascal way).
Registers, stack frame and call/ret
Registers are reserved variables in the processor that can be used by the assembly code. Stack frame is the function calling hierarchy, the "who called who" in a given execution state. Call and ret are assembly instructions to call and return from a function, respectively. Both change the stack frame.
Imagine you have a function, CallFunc, and another function, Func, and one calls the other. In order to analyse just the function call, and just that, let's consider Func doesn't receive any argument and doesn't return any value. The C code, would be like bellow:
void Func()
{
return;
}
void CallFunc()
{
Func();
}
Simple, huh? Being simple, the generated assembly will be simple as well. In CallFunc it should have the function call, and inside Func the return from the call. The rest of the code is related with Debug version stuff.
Func: 00411F73 prev_instruction ; ESP = 0012FD38 (four bytes stacked up) 00411F74 ret ; *ESP = 00411FA3 (return address) CallFunc: 00411F9C prev_instruction 00411F9E call Func (411424h) ; ESP = 0012FD3C 00411FA3 next_instruction
From the assembly above we can conclude two things: 1. The stack grows down, since its value decremented four bytes (0012FD3C minus 0012FD38 equal four) and 2. The return value from the calling is the address of the very next instruction after the call instruction, in the case 00411FA3.
Well, in the same way we can follow this simple execution, the attacker will do as well. That's why in the middle of this call we will throw an exception and, in the return, we will not do the return in the conventional way, but using another technique that, instead using the ret instruction, sets manually the esp value (stack state) and jumps to the next instruction in CallFunc.
Func: 00411F60 throw_exception 00411F61 ... 00411F73 catch_exception 00411F74 mov ESP, 0012FD3C ; ESP = 0012FD3C, just like CallFunc 00411F75 jmp 00411FA3 ; jumps to CallFunc::next_instruction
Back to the Middle Earth
All this assembly stuff doesn't need to be written in assembly level. It was just a way I found to illustrate the differences between the stack return and the jump return. As it was said, to the luck and well being for all, this same technique can be implemented using ANSI C functions:
jmp_buf env; // Contains the next instruction (stack state).
void Func()
{
// 3. Return using the "nonconventional" way
longjmp(env, 1);
}
void CallFunc()
{
// 1. If we're setting, returns 0.
// 2. If we're returning, returns a value different from 0.
if( setjmp(env) == 0 )
Func();
int x = 10; // 4. Next instruction.
}
That was the new trick for the trowing of exceptions. The final code is clearer, now:
/** The only purpose of this function is to generate an exception.
*/
DWORD LongJmp(jmp_buf* env)
{
__try
{
__asm int 3
}
__except( EXCEPTION_EXECUTE_HANDLER )
{
longjmp(*env, 1);
}
return ERROR_SUCCESS;
}
/** And God said: 'int main!'
*/
int main()
{
DWORD ret = ERROR_SUCCESS;
while( cin )
{
string line;
cout << "Type something\n";
getline(cin, line);
jmp_buf env;
if( setjmp(env) == 0 )
{
LongJmp(&env);
}
else
{
cout << line << endl;
}
}
return (int) ret;
}
At first sight, it seems a waste the if being directly in the code (remember we gonna use the same conditional structure in several parts in the code). To turn things clearer, resume the protected call and allows the protection to be disabled in debug version code, let's create a macro:
/** Use this macro instead LongJmp
*/
#define ANTIDEBUG(code)
{
jmp_buf env;
if( setjmp(env) == 0 )
{
LongJmp(&env);
}
else
{
code;
}
}
/** And God said: 'int main!'
*/
int main()
{
DWORD ret = ERROR_SUCCESS;
while( cin )
{
string line;
cout << "Type something\n";
getline(cin, line);
ANTIDEBUG(( cout << line << endl ));
}
return (int) ret;
}
Now we allow the antidebugging selection by call, what turns things much easier than to choose the protected points inside the code.
[2008-06] [2008-08]