- Acessando memória física no WinDbg
- Sofrimento
- Read The Functional Manual
- Como tratar um merge no Bazaar
- Kernel Mode >> User Mode, ou Como Fazer Debug de User Mode pelo Kernel Mode
- Aquele do-while engraçado
- Busca do Google com atalhos
- MouseTool: clique automático do seu rato
- Aprendendo rapidamente conceitos essenciais do WinDbg
- How to run anything as a service
- Como criar uma LIB no Visual Studio
# Acessando memória física no WinDbg
Caloni, 2008-05-01 <computer> [up] [copy]Como muitos devem saber, acessar memória virtual no WinDbg é coisa de criança, assim como em todo depurador decente. Se estamos falando de kernel mode então, nem se fala! A memória virtual é parte integrante do sistema operacional. Podemos saber mais sobre isso na apresentação do Strauss sobre gerenciamento de memória no Windows.
Porém, existem situações, como a que passei essa semana, onde é preciso saber e alterar o conteúdo da memória de verdade, mesmo. Quando eu falo "de verdade mesmo" estou falando em acessar a memória através do seu endereçamento real, que conta do zero até o final da sua memória RAM, sem divisão de processos e sem proteções de acesso.
Para isso é que serve um depurador de verdade, mesmo.
No modo real, onde vivem sistemas como o MS-DOS e programas como o Turbo C, a memória é acessada através do par de coordenadas conhecido como segmento e offset. Entre outros motivos, isso acontece porque em um determinado momento da história o 8086 possuía 16 bits em seus registradores, mas conseguia endereçar até 640 quilobytes, o que resulta em 640 vezes 1024, ou seja, 655366 bytes, um número dez vezes maior do que 65536 mil, ou 2 elevado a 16, o maior número representado por 16 bits.
Dessa forma, foi necessário o uso de mais 4 bits para fazer a coisa funcionar, pois como podemos notar logo abaixo, a representação do último byte de 640 KB exige isso:
10 16 16 16 16 dec A 0 0 0 0 hex 1010 0000 0000 0000 0000 bin
Para conseguir esses 4 bits adicionais foram usados dois registradores em conjunto, o segmento e o offset. Funciona assim: o segmento é multiplicado por 16 (ou deslocado 4 bits à esquerda) e logo depois é somado com o offset, resultando no endereçamento desejado:
segment: 0x 9022
offset: 0x 1514
0x 9022
0x 1514 (+)
real addr: 0x 91734
Ou seja, para acessar o byte de número 595764, ou 0x91734 podemos usar o segmento 0x9022 com o offset 0x1514. A soma desses dois com o segmento deslocado irá resultado no endereço flag, ou seja, aquele que obtemos se contarmos a memória do zero até o final da RAM. Importante lembrar que na época a RAM não costumava ser de valores como 2GB ou até 4GB, mas em KB mesmo. Isso explica a limitação do 8086 em endereçar até 640 KB.
Se nós repararmos bem, veremos que esse método implica em conseguirmos acessar o mesmo byte com um conjunto de segmentos e offsets diferentes, já que a soma pode ser resultado de operandos diversos. Esse é o chamado efeito de overlapping da memória segmentada, onde os programadores em assembly daquela época tinham que tomar alguns cuidados básicos para não atravessar a memória dos outros. No nosso exemplo acima, por exemplo, seria bem mais fácil chamar nosso bytezinho de segmento 0x9000, offset 0x1734.
0x 9000 0x 1734 (+) 0x 91734
É verdade! Então, o WinDbg possui alguns comandos extendidos e formas de representar essa memória real, atualmente limitada não mais em 640 KB, mas até onde seus pentes de RAM agüentarem. Os mais comuns são os que imitam os nossos conhecidos dumps de memória: db, dc, dd... Temos daí as extensões !db, !dc, !dd... (note a exclamação do início).
windbg -kl lkd> !db 91734 # 91734 00 (...) ..... # 91744 00 (...) ..... # 91754 00 (...) ..... # 91764 00 (...) ..... # 91774 00 (...) ..... # 91784 00 (...) ..... # 91794 00 (...) .....
Simples, assim. O sinal de # no início do dump de memória denota memória real.
Infelizmente, o WinDbg não nos permite ler certas regiões da memória por conta do cacheamento feito pelo processador. Para permitir a leitura em todas as condições, existem três flags que podem ser utilizados:
- c lê da memória cacheada
- uc lê da memória não-cacheada
- wc lê da memória de escrita combinada
Nesse caso é possível, embora fique por sua conta e risco, ler qualquer memória não-cacheada usando-se a flag uc.
É possível fazer mais brincadeiras usando os comandos comuns do WinDbg e uma notação diferente da memória. No entanto, é preciso tomar alguns cuidados quando mexer com isso. É recomendado o uso de uma máquina-vítima para esses testes, e não depuração local como estou fazendo.
descrição example
------------ ----------
% 32, 64 bits %6400000
& real 8086 &9000:1734
# real 8086 #4C
É isso aí. Não espero que você use muitas vezes essa forma de acessar memória. Só que eu usei e... nunca se sabe =)
# Sofrimento
Caloni, 2008-05-01 <quotes> <self> <now> [up] [copy]Quanto mais a mente tenta se livrar do sofrimento, mais ele aumenta.
A Consciência transforma o sofrimento nele mesmo.
Tolle, Eckhart (O Poder do Agora, 1997)
# Read The Functional Manual
Caloni, 2008-05-07 [up] [copy]Percebi essa semana que talvez boa parte da população informática que não progride em suas habilidades, mas gostaria muito, pode ser impedida pela falta de hábito em ler a ajuda do programa | da linguagem | do sistema com calma para encontrar o que procura. Independente do que você é, e para onde quer chegar, saiba que nem tudo na vida pode ser perguntado ao seu colega de baia. Senão você não evolui!
Se você quer dominar um assunto, ou aprender sobre ele, saiba que existem estágio nesse processo. O primeiro estágio é formado principalmente por livros. Se você quer aprender algo, e tem livros sobre o assunto, você é um cara sortudo e feliz.
Eu concordo com o cara do 1bit quando ele diz que livros são MUITO importantes. Provavelmente eu não seria metade do programador que me considero hoje se só tivesse a experiência, mas não a base fundamental necessária para realmente progredir no que se gosta.
Para algumas coisas pode não existir um livro bem estruturado e organizado nos moldes de "pra iniciante". Nesse caso, na maioria das vezes existe pelo menos o chamado tutorial, ou guia do usuário, que dá o pontapé inicial na cabeça do cara que quer começar a mexer com algum negócio novo.
Outra coisa que acredito que seja fundamental, o segundo nível depois que você começou a ler um bom livro, é saber usar o que você precisa. E para saber usar nada melhor do que ler o manual. Óbvio, não? Pois é, eu também achava... até quando vi um amigo meu tentando descobrir por que as coisas não estavam funcionando, baseado na boa e velha tentativa e erro. É um outro caminho válido, concordo. Mas, se você ainda não deu uma olhada na parte da documentação que fala sobre o problema que você está tendo, então está andando em círculos. E vai aprender bem menos do que poderia.
Outra coisa que ouço com bastante freqüência é a pessoa desanimar por ter muita coisa pra estudar. Bem, se não houvesse tanta coisa assim para estudar não valeria a pena. E nem existiria documentação a respeito. Pra quê, se dá pra decorar tudo de uma vez?
O fato é que os sistemas tendem a ficar cada vez mais complexos e volumosos. Quem duvida, veja o monstro que essas linguagens de alto nível estão se tornando, com mil e uma possibilidades de fazer a mesma coisa.
E como sobreviveríamos nós, meros programadores de fundo de quintal, se não fosse a bênção de uma documentação completa e bem estruturada? Difícil dizer... eu praticamente não vivo sem ler a ajuda de qualquer coisa que eu precise fazer funcionar. Mesmo sendo um programa qualquer que abre um arquivo, coisa que já fiz três milhões de vezes e meia, continuo olhando na ajuda do CreateFile.aspx). E não sou um chimpanzé autista. Eu simplesmente prefiro guardar coisas mais importantes na cabeça do que quantos parâmetros eu preciso passar em uma determinada função. (no caso do CreateFile, são sete!)
Porém, existem aqueles problemas que realmente desafiam o bom senso, a ponto de nem livros, nem tutoriais e muito menos a documentação ter alguma coisa a respeito. O que fazer numa hora dessas? Se você já é um programador tarimbado já sabe do que eu vou falar antes de terminar a primeira linha desse parágrafo: google!
Atualmente existem diversas formas do google te ajudar a encontrar o que você precisa: blogues que falam a respeito (pessoas ajudando pessoas indiretamente), fóruns de discussão sobre o assunto (mais uma vez), páginas do "fabricante" que explicam em melhores detalhes algum problema que está se tornando comum, etc.
É assim que você irá começar a pedir ajuda das pessoas: indiretamente. Não se pergunta nada que já tenha sido respondido. Porque é uma perda de tempo dos dois lados. Do lado que pergunta porque sua resposta já pode estar prontinha em algum canto da web. Do lado que responde porque a pessoa terá que achar o lugar onde respondeu a mesma pergunta, copiar e colar (ou simplesmente ignorar, o que te fará perder mais tempo).
Você já devia saber disso. Faz parte da netiqueta, o guia mundial de bom uso da internet. O quê? Você nunca leu a netiqueta? Se nunca, então comece por lá. Depois venha fazer perguntas interessantes.
Tudo bem, você não conseguiu achar nenhum livro a respeito, não existe tutorial no mundo que resolva o seu problema, e todas as pessoas que possuem a resposta falam e escrevem em mandarim, ou algum outro idioma baseado em pegadas de passarinhos (o google ainda não traduz isso ainda muito bem). Nesse último caso, você ainda tem duas escolhas, sendo a mais fácil delas perguntar para quem entende.
Eu já fiz isso muitas vezes, antes de aprender a me virar (quase) sozinho. Todas que fiz foi por um de dois motivos: intercomunicação ou desespero.
Intercomunicação é quando você fica empolgado com o assunto, conversa com todo mundo que usa o treco que você está aprendendo e anseia por aprender cada vez mais todo dia. Nesse caso a conversa pode ser muito frutífera e animar mais ainda o aprendizado. Porém, é necessário tomar algumas precauções para se certificar que você não está afogando as pessoas de perguntas.
Desespero é quando tudo que você tentou não funciona e você sabe que para adquirir o conhecimento que precisa irá levar muito mais tempo do que fazer a pergunta certa para a pessoa certa. Nesse caso, estou falando realmente de MUITO tempo, coisa de meses a anos.
Também existe um outro caso de desespero, que é quando você sabe que vai perder o emprego se não resolver o problema.
Eu disse que existem duas escolhas nesse estágio. A primeira é perguntar para quem entende do assunto. Porém, o que acontece se você é uma das pessoas que mais entende do assunto que você conhece?
Aí o jeito é resolver sozinho. E, se possível, publicar em algum lugar a solução. A rede agradece.
# Como tratar um merge no Bazaar
Caloni, 2008-05-09 <computer> [up] [copy]Hoje fizemos um merge de duas versões que entraram em conflito em nosso projeto-piloto usando bzr. Isso geralmente ocorre quando alguma coisa mudou no mesmo arquivo em lugares muito próximos um do outro. Veremos um exemplo de código para ter uma idéia de quão fácil é o processo:
#include <stdio.h>
void InitFunction()
{
printf("InitFunction");
}
void DoAnotherJob()
{
char buf[100] = "";
fgets(buf, sizeof(buf), stdin);
printf("New line: %s", buf);
}
void TerminateFunction()
{
printf("TerminateFunction");
}
int main()
{
InitFunction();
while( ! feof(stdin) )
{
DoAnotherJob();
}
TerminateFunction();
}
A execução do programa contém uma saída parecida com as linhas abaixo:
C:\Tests\bzrpilot>bzppilot.exe InitFunctionuma linha New line: uma linha duas linhas New line: duas linhas tres linhas New line: tres linhas ^Z New line: TerminateFunction C:\Tests\bzrpilot>
Parece que está faltando algumas quebras de linha. Além de que sabemos que nossos arquivos de entrada poderão conter até 200 caracteres por linha, o que pode gerar um desastre em nosso buffer de 100 bytes. Buffer overflow!
Para corrigir ambos os problemas foram criados dois branches, seguindo as melhores práticas de uso de um controle de fonte distribuído:
C:\Tests>bzr branch bzrpilot bzrpilot-linebreak Branched 1 revision(s). C:\Tests>bzr branch bzrpilot bzrpilot-bufferoverflow Branched 1 revision(s).
Feitas as correções devidas, o branch linebreak fica com a seguinte cara:
void InitFunction()
{
printf("InitFunction\n");
}
void DoAnotherJob()
{
char buf[100] = "";
fgets(buf, sizeof(buf), stdin);
printf("New line: %s\n", buf);
}
void TerminateFunction()
{
printf("TerminateFunction\n");
}
Em vermelho podemos notar as linhas alteradas. Uma mudança diferente foi feita para o bug do buffer overflow, em seu branch correspondente:
void DoAnotherJob()
{
char buf[200] = "";
fgets(buf, sizeof(buf), stdin);
printf("New line: %s", buf);
}
Agora só temos que juntar ambas as mudanças no branch principal.
"Mas espere aí! Não é uma boa termos números mágicos no código!"
Com toda razão, pensa o programador que está corrigindo o bug da quebra de linha, olhando sorrateiramente a função do meio, intocada, DoAnotherJob.
Então ele resolve fazer um pequeno fix "de brinde", desconhecendo que mais alguém andou alterando essas linhas:
#define ENOUGH_BYTES 100
void InitFunction()
{
printf("InitFunction\n");
}
void DoAnotherJob()
{
char buf[ENOUGH_BYTES] = "";
fgets(buf, sizeof(buf), stdin);
printf("New line: %s\n", buf);
}
Pronto. Um fonte politicamente correto! E que vai causar um conflito ao juntar essa galera. Vamos ver na seqüência:
C:\Tests>bzr log bzrpilot-linebreak --short
3 Wanderley Caloni 2008-05-08
A little fix
2 Wanderley Caloni 2008-05-08
Corrected line breaks
1 Wanderley Caloni 2008-05-08
Our first version
C:\Tests>bzr log bzrpilot-bufferoverflow --short
2 Wanderley Caloni 2008-05-08
Corrigido buffer overflow
1 Wanderley Caloni 2008-05-08
Our first version
C:\Tests>bzr log bzrpilot --short
1 Wanderley Caloni 2008-05-08
Our first version
C:\Tests>cd bzrpilot
C:\Tests\bzrpilot>bzr pull ..\bzrpilot-linebreak
M bzppilot.cpp
All changes applied successfully.
Now on revision 3.
C:\Tests\bzrpilot>bzr pull ..\bzrpilot-bufferoverflow
bzr: ERROR: These branches have diverged. Use the merge command to reconcile them.
Ops. Algo deu errado no segundo pull. O Bazaar nos diz que os ranches estão diferentes, e que termos que usar o comando merge no lugar.
C:\Tests\bzrpilot>bzr merge ..\bzrpilot-bufferoverflow
M bzppilot.cpp
Text conflict in bzppilot.cpp
1 conflicts encountered.
Usamos merge no lugar do pull e ganhamos agora um conflito no arquivo bzppilot.cpp, nosso único arquivo. Vamos ver a bagunça que fizemos?
A última coisa que um controle de fonte quer fazer é confundir ou chatear o usuário. Por isso mesmo, a maioria dos conflitos que o Bazaar encontrar nos fontes serão resolvidos usando o algoritmo "se só um mexeu, então coloca a mudança". A tabela do guia do usuário ilustra esse algoritmo em possibilidades:
| ancestor | first_branch | second_branch | result | comment | | -------- | ------------ | ------------- | ------- | ---------------- | | x | x | x | x | não muda | | x | x | y | y | usuário 2 ganhou | | x | y | x | y | usuário 1 ganhou | | x | y | z | ? | conflito!!! |
O ancestral é a última modificação em comum dos dois branches que estamos fazendo merge. Do ancestral pra frente cada um seguiu seu caminho, podendo existir quantas modificações quisermos.
Como podemos ver, o conflito só ocorre se ambos os usuário mexerem na mesma parte do código ao mesmo tempo. Eu disse na mesma parte do código, e não apenas no mesmo arquivo. Isso porque se a mudança for feita no mesmo arquivo, porém em locais diferentes, o conflito é resolvido automaticamente.
Em todos os conflitos de texto desse tipo, o Bazaar cria três arquivos de suporte e modifica o arquivo em conflito. Isso para cada conflito.
- arquivo.cpp - Resultado de até onde o Bazaar conseguiu o merge
- arquivo.cpp.BASE - Versão ancestral do arquivo
- arquivo.cpp.THIS - Nosso arquivo original antes de tentar fazer merge
- arquivo.cpp.OTHER - A versão que entrou em conflito com a nossa
Podemos fazer o merge da maneira que quisermos. Se vamos usar nossa versão de qualquer jeito é só sobrescrever o arquivo.cpp pelo arquivo.cpp.THIS. Se vamos fazer troca-troca de alterações, abrimos os arquivos .THIS e .OTHER e igualamos suas diferenças, copiando-as para arquivo.cpp.
Recomendo primeiramente olhar o que o Bazaar já fez. Se houver dúvidas sobre a integridade das mudanças, comparar diretamente os arquivos THIS e OTHER.
Vamos dar uma olhada na versão criada pelo Bazaar:
#include <stdio.h>
#define ENOUGH_BYTES 100
void InitFunction()
{
printf("InitFunction\n");
}
void DoAnotherJob()
{
<<<<<<< TREE
char buf[ENOUGH_BYTES] = "";
=======
char buf[200] = "";
>>>>>>> MERGE-SOURCE
fgets(buf, sizeof(buf), stdin);
printf("New line: %s\n", buf);
}
void TerminateFunction()
{
printf("TerminateFunction\n");
}
int main()
{
InitFunction();
while( ! feof(stdin) )
{
DoAnotherJob();
}
TerminateFunction();
}
Ora, vemos que ele já fez boa parte do trabalho para nós: as quebras de linha já foram colocadas e o novo define já está lá. Tudo que temos que fazer é trocar o define por 200 e tirar os marcadores, que é a junção das duas mudanças feitas no mesmo local, e que só um ser humano (AFAIK) consegue juntar:
#define ENOUGH_BYTES 200
void InitFunction()
{
printf("InitFunction\n");
}
void DoAnotherJob()
{
char buf[ENOUGH_BYTES] = "";
fgets(buf, sizeof(buf), stdin);
printf("New line: %s\n", buf);
}
Resolvido o problema, simplesmente esquecemos das versões .BASE, .THIS e .OTHER e falamos pro Bazaar que está tudo certo.
C:\Tests\bzrpilot>bzr resolve bzppilot.cpp
O controle de fonte apaga automaticamente os arquivos THIS, BASE e OTHER, mantendo o original como a mudança aceita.
Após as correções dos conflitos, temos que fazer um commit que irá ser o filho dos dois branches que estamos juntando.
C:\Tests\bzrpilot>bzr commit -m "Tudo certo"
Committing to: C:/Tests/bzrpilot/
modified bzppilot.cpp
Committed revision 4.
C:\Tests\bzrpilot>bzr log
------------------------------------------------------------
revno: 4
committer: Wanderley Caloni <wanderley@caloni.com.br>
branch nick: bzrpilot
timestamp: Thu 2008-05-08 22:09:35 -0300
message:
Tudo certo
------------------------------------------------------------
revno: 1.1.1
committer: Wanderley Caloni <wanderley@caloni.com.br>
branch nick: bzrpilot-bufferoverflow
timestamp: Thu 2008-05-08 21:47:33 -0300
message:
Corrigido buffer overflow
------------------------------------------------------------
revno: 3
committer: Wanderley Caloni <wanderley@caloni.com.br>
branch nick: bzrpilot-linebreak
timestamp: Thu 2008-05-08 21:49:30 -0300
message:
A little fix
------------------------------------------------------------
revno: 2
committer: Wanderley Caloni <wanderley@caloni.com.br>
branch nick: bzrpilot-linebreak
timestamp: Thu 2008-05-08 21:44:23 -0300
message:
Corrected line breaks
------------------------------------------------------------
revno: 1
committer: Wanderley Caloni <wanderley@caloni.com.br>
branch nick: bzrpilot
timestamp: Thu 2008-05-08 21:33:53 -0300
message:
Our first version
A versão do branch alternativo é 1.1.1, indicando que ele saiu da revisão número 1, é o primeiro alternativo e foi o único commit. Se houvessem mais modificações neste branch, elas seriam 1.1.2, 1.1.3 e assim por diante. Se mais alguém quisesse juntar alguma modificação da revisão 1 ela seria 1.2.1, 1.3.1, 1.4.1 e assim por diante.
Um erro comum que pode acontecer é supor que o arquivo original está do jeito que deixamos e já usar o comando resolve diretamente. É preciso tomar cuidado, pois se algum conflito é detectado quer dizer que o Bazaar deixou para você alguns marcadores no fonte original, o que quer dizer que ele simplesmente não vai compilar enquanto você não resolver seus problemas.
Enfim, tudo que temos que lembrar durante um merge do Bazaar é ver os conflitos ainda não resolvidos direto no fonte e alterá-los de acordo com o problema. O resto é codificar.
# Kernel Mode >> User Mode, ou Como Fazer Debug de User Mode pelo Kernel Mode
Caloni, 2008-05-13 <computer> <windbg> [up] [copy]Existem algumas situações onde um depurador WYSIWYG é artigo de luxo.
Imagine o seguinte: temos um serviço que inicia automagicamente antes do login do Windows, e possivelmente antes mesmo do ambiente gráfico. Esse serviço tem algum problema que impede que ele funcione sob as circunstâncias de inicialização do sistema. O que fazer? Atachar o WinDbg no processo?
Mas que mané WinDbg? Que mané atachar? Nessa hora nós temos bem menos do que nossos sentidos são capazes de enxergar.
Nessas horas o único que pode nos ajudar é o kernel debugger.
<https://youtu.be/j1f7DQkFI5A>
Os depuradores do pacote Debugging Tools (especialmente o ntsd e o cdb) suportam o funcionamento em modo proxy, ou seja, eles apenas redirecionam a saída e os comandos entre as duas pontas da depuração (o depurador e o depurado). Isso é comumente usado em depuração remota e depuração de kernel, quando o sistema inteiro está congelado. O objetivo aqui é conseguir os dois: depurar remotamente um processo em um sistema que está travado.
Para isso podemos nos utilizar do parâmetro -d, que manda o depurador redirecionar toda saída e controle para o depurador de kernel. Para que isso funcione o depurador já deve estar atachado no sistema-alvo. A coisa funciona mais ou menos assim:
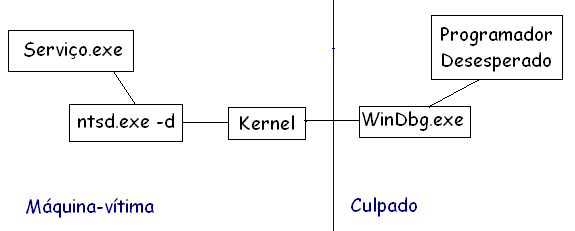
Com essa configuração temos a vantagem de ter o sistema congelado só pra nós, ao mesmo tempo que conseguimos depurar nosso processo fujão, passo-a-passo.
A única desvantagem é não ter uma GUI tão poderosa quando o "WinDbg fonte colorido, tooltips, etc". Pra quem não liga pra essas frescuras, é possível depurar processos de maneira produtiva utilizando esse cenário.
Para ativar qualquer programa que irá rodar nesse modo, basta usar o aplicativo gflags:
gflags /p /enable servico.exe /debug "c:\path\ntsd.exe -d"
Para entender o fluxo de navegação pelo mundo kernel-user misturados é preciso dar uma lida bem profunda na ajuda do Debugging Tools para entender como as coisas estão funcionando nessa configuração milagrosa que estamos usando. Procure por "Controlling the User-Mode Debugger from the Kernel Debugger". Também é possível ouvir falar parcamente sobre isso no livro Advanced Windows Debugging na parte "Redirecting a User Mode Debugger Through a Kernel". A vantagem é que vem de brinde uma bela figura para pendurar em um quadro no escritório (embora eu possa jurar que já vi essa figura na ajuda do WinDbg):
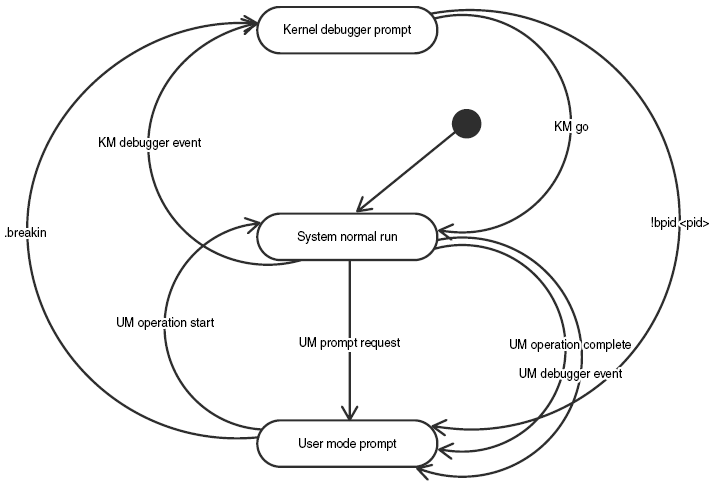
Como podemos notar, o controlador de tudo é o kernel debugger. Assim que o depurador de processo entra em ação, ele se comunica com o depurador de kernel que entra no modo user mode prompt, pedindo entrada para ser redirecionada ao depurador de processo. Existem alguns caminhos para sair de um estado e entrar em outro, como o comando .breakin e o .sleep.
É necessário recomentar: estamos nos comunicando com um depurador e o seu processo depurado em um sistema totalmente travado. Isso quer dizer que o acesso a coisas como código-fonte e símbolos é extremamente limitado, porém não impossível. Apenas mantenha-os localmente na máquina-vítima, pois uma comunicação pela rede não irá funcionar.
A depuração com a linha atual no código-fonte demarcando onde estamos também não é possível, uma vez que o WinDbg da ponta de cá apenas faz o papel de garoto de recados para o "depurador de verdade" do outro lado (no nosso exemplo, o ntsd). Isso quer dizer que a forma mais "fácil" de ir passo-a-passo é usar o comando p (step) ou t (trace), além de habilitar o uso de fonte em 100%.
input> .srcpath c:\maquina-vitima\src
input> l+* $$ habilita uso de código-fonte no ntsd
...
0:000> p
> 15: int main() $$ número da linha seguido do fonte
> 16: {
0:000> bp myFunction
0:000> g
0:000>
Um tipo de problema que só pode ser depurado dessa maneira enfatiza a importância do uso de unit tests, além de um controle de qualidade mais aguçado antes de liberar uma versão para o cliente.
# Aquele do-while engraçado
Caloni, 2008-05-15 <computer> <ccpp> [up] [copy]Nesses últimos dias andei conversando com um amigo que está estudando sistemas operacionais na faculdade. Melhor ainda, vendo o código real de um sistema operacional em funcionamento. A conseqüência é que, além de aprender um bocado de como as coisas funcionam de verdade debaixo dos panos, acaba-se aprendendo alguns truquezinhos básicos e tradicionais da linguagem C.
Por exemplo, é um hábito conhecido o uso de construções do-while quando existe a necessidade de definir uma macro que possui mais de um comando em vez de usar a igualmente conhecida { construção de múltiplos comandos entre chaves }.
O que talvez não seja tão conhecido é o porquê das coisas serem assim.
Vamos imaginar uma macro de logue que é habilitada em compilações debug, mas é mantida em silêncio em compilações release:
#ifdef NDEBUG
#define MYTRACE(message) /*nada*/
#else
#define MYTRACE(message) \
{ \
char buffer[500]; \
sprintf(buffer, \
"DBG: %s(%d) %s\n", \
__FILE__, \
__LINE__, \
message); \
output(buffer); \
}
#endif /* NDEBUG */
Nada de mais, e parece até funcionar. Porém, como veremos nas próximas linhas, esse é realmente um exemplo de código "buguento", já que uma chamada dentro de uma construção if-else simplesmente não funciona.
if( exploded() )
MYTRACE("Oh, my God");
else
MYTRACE("That's right");
error C2181: illegal else without matching if
Por que isso? Para responder a essa questão nós precisamos olhar um pouco mais de perto no resultado do preprocessador da linguagem, que apenas troca nossa macro pelo pedaço de código que ela representa:
if( exploded() )
{
char buffer[500];
sprintf(buffer,
"DBG: %s(%d) %s\n",
__FILE__,
__LINE__,
"Oh, my God");
output(buffer);
};
else
{
char buffer[500];
sprintf(buffer,
"DBG: %s(%d) %s\n",
__FILE__,
__LINE__,
"That's right");
output(buffer);
};
Dessa forma, podemos ver o porquê. Quando chamamos a macro, geralmente usamos a sintaxe de chamada de função, colocando um sinal de ponto-e-vírgula logo após a chamada. Essa é a maneira correta de se chamar uma função, mas no caso de uma macro, dessa macro, é um desastre, porque ela cria dois comandos em vez de um só (um ponto-e-vírgula vazio, apesar de não fazer nada, é um comando válido). Então, isso é o que o compilador faz:
if( instruction )
{
/* um monte de comandos */
} /* aqui eu esperaria um else ou uma instrução nova */
; /* uma instrução nova! ok, sem else desa vez */
else /* espere ae! o que esse else está fazendo aqui sem um if?!?! */
{
/* mais comandos */
}
Pense sobre o comando vazio como se ele fosse um comando real, o que é a maneira mais fácil de entender o erro de compilação que recebemos ao compilar o código abaixo:
if( error() )
{
printf("error");
}
printf("here we go");
else /* llegal else without matching if! */
{
printf("okay");
}
Por essa razão, a maneira tradicional de escapar desse erro comum é usar uma construção válida que peça de fato um ponto-e-vírgula no final. Felizmente nós, programadores C/C++, temos essa construção, e ela é... muito bem, o do-while!
do
{
/* múltiplos comandos aqui */
}
while( expression )
; /* eu espero um ponto-e-vírgula aqui,
para finalizar minha
instrução do-while */
Assim nós podemos reescrever nossa macro de logue da maneira certa (e todas as 549.797 macros já escritas em nossa vida de programador). E, apesar de ser uma construção um tanto bizarra, ela funciona melhor do que nossa tentativa inicial:
#ifdef NDEBUG
#define MYTRACE(message) /*nada*/
#else
#define MYTRACE(message) \
do \
{ \
char buffer[500]; \
sprintf(buffer, \
"DBG: %s(%d) %s\n", \
__FILE__, \
__LINE__, \
message); \
output(buffer); \
} \
while( 0 )
#endif /* NDEBUG */
Ao usar um do-while (com uma expressão que retorna falso dentro do teste, de maneira que o código seja executado apenas uma vez) a construção if-else consegue funcionar perfeitamente:
if( exploded() )
do
{
char buffer[500];
sprintf(buffer,
"MYTRACE: %s(%d) %s\n",
__FILE__,
__LINE__,
"Oh, my God");
OutputDebugString(buffer);
}
while( 0 );
else
do
{
char buffer[500];
sprintf(buffer,
"MYTRACE: %s(%d) %s\n",
__FILE__,
__LINE__,
"That's right");
OutputDebugString(buffer);
}
while( 0 );
# Busca do Google com atalhos
Caloni, 2008-05-19 [up] [copy]Eu adoro atalhos de teclado. Desde meus primeiros anos usando computadores, atalhos têm se tornado minha obsessão. Sempre faço minha pesquisa pessoal de tempos em tempos, colecionando e usando novos atalhos descobertos. Por um bom tempo eu evitei ter que usar o mouse, treinando-me para lembrar de todas as seqüências de teclas que conhecia.
Eu não tenho nada contra o uso do mouse nem as pessoas que o usam. Eu apenas não sou tão entusiástico em usar o mouse. Por algum tempo, eu até acreditei que o ponteiro do cursor estava me atrapalhando, então eu desenvolvi um programa para tirá-lo da tela (usando um atalho de teclado, claro). Porém, mais uma vez, não sou contra seu uso. Eu mesmo uso-o de vez em quando (quando eu preciso).
Até algum tempo atrás a web não era muito convidativa para usuários de atalhos. Então surgiu o Google e as suas aplicações que suportavam essa característica, o que me deu uma razão a mais para passar a usar seu cliente de e-mail e leitor de notícias sem pressionar constantemente a tecla Tab. No entanto, ainda faltava a mesma funcionalidade para seu buscador. Felizmente, isso não é mais verdade.
Ainda em teste, eu comecei a usar os novos atalhos de teclado na busca do Google disponíveis no saite Google Experimental Search. Até agora existem atalhos para próximo resultado (J), resultado anterior (K), abertura da busca (O ou Enter) e colocação do cursor na caixa de busca (/). Eles funcionam exatamente como o Gmail e o Google Reader. Eu fiquei tão empolgado com a idéia que mudei o complemento de busca do Google de dentro do meu Firefox. E agora vou contar como isso pode ser feito facilmente (nota: minhas dicas servem para usuário de Windows apenas).
Provavelmente seu complemento de busca estará em uma das duas pastas abaixo:
%programfiles%\Mozilla Firefox\searchplugins %appdata%\Mozilla\Firefox\Profiles\*.default\searchplugins
O arquivo do complemento tem o nome google.xml e você pode editá-lo usando o Bloco de Notas ou qualquer outro editor de texto simples (sem formatação). Abaixo está o ponto onde você deve inserir a nova linha que irá ativar os atalhos dentro da página de buscas do Google.
<Url type="text/html" method="GET" template="http://www.google.com/search">
<Param name="q" value="{searchTerms}"/>
<...>
<Param name="esrch" value="BetaShortcuts"/> <!-- Google Shortcuts Here -->
<!-- Dynamic parameters -->
<...>
</Url>
É isso aí. Agora você pode ter o melhor dos dois mundos: o melhor buscador da internete com atalhos. Existirá maneira de se tornar ainda mais produtivo?
# MouseTool: clique automático do seu rato
Caloni, 2008-05-21 <computer> <projects> [up] [copy]Bem, como a maioria de vocês já sabe, eu realmente não gosto de mouses. Apesar disso, respeito os usuário que usam-no e até gostam dele. Essa é a razão por que estou escrevendo mais uma vez sobre isso. Dessa vez, irei mostrar um programa que eu uso todos os dias: MouseTool, para os usuários que não usam o mouse, mas gostam dele.
O principal objetivo do programa é evitar de clicar no mouse, simulando um clique toda vez que o usuário pára de mover o ponteiro. E é só isso: simples, eficiente e mouseless =).
Existem algumas outras opções como arrastar-e-soltar e clique-duplo, ambas disponíveis pelo próprio programa através de atalhos do teclado ou mudança de estado, situação onde o usuário antes pousa o ponteiro sobre a ação desejada e depois pousa o ponteiro sobre o alvo, dessa forma alternando entre os três modos.
O MouseTool originalmente foi uma ferramente de fonte aberto. Isso significa que a última versão do código-fonte está disponível, certo? Errado. Na verdade, eu não consegui, por mais que tentasse achar, a versão para baixar do código.
Felizmente meu amigo Marcio Andrey já havia baixado o fonte algum tempo atrás e, assim como eu, ele gostaria de torná-lo disponível para todos que gostassem de usá-lo e alterá-lo. Por isso que estou publicando-o aqui. Ele é gratuito e aberto. Façam o que quiserem com ele =).
Vamos aproveitar o código-fonte e mostrar como explorar um código não escrito por nós. Normalmente as primeiras coisas a fazer são: baixar o arquivo compactado e descompactá-lo dentro de uma nova pasta. Dessa forma encontramos o arquivo de projeto (nesse caso, MouseTool.dsw) e tentamos abri-lo. Falhando de início miseravelmente porque acredito que ninguém mais utilize a versão do Visual Studio que abre isso.
Normalmente programadores de projetos de fonte aberto estão acostumados a obter os arquivos-fonte, modificá-los, publicá-los e assim por diante. Porém isso não é quase nunca verdade para programadores Windows de aplicativos estritamente comerciais. É necessário se reajustar à nova cultura para aproveitar os benefícios da política de fonte aberto.
Por exemplo, dados os arquivos-fonte, nós podemos explorar algumas partes interessantes de coisas que gostaríamos de fazer em nossos próprios programas. São trechos pequenos de código que fazem coisas úteis que gastaríamos algumas horas/dias para pesquisar na internet e achar a resposta procurada. Através de um projeto de fonte aberto, conseguimos usar um programa e ao mesmo tempo aprender seu funcionamento. E a principal parte é: nós temos o fonte, mas não os direitos autorais.
PS: MouseTool agora tem uma versão Linux em um projeto no Source Forge! Seu nome é GMouseTool, projeto criado por Márcio de Oliveira.
# Aprendendo rapidamente conceitos essenciais do WinDbg
Caloni, 2008-05-23 <computer> <windbg> [up] [copy]Todo o poder e flexibilidade do pacote Debugging Tools da Microsoft pode ser ofuscado pela sua complexidade e curva de aprendizagem. Afinal de contas, usar o depurador do Visual Studio é muito fácil, quando se começa a usar, mas mesmo assim conheço muitos programadores que relutam em depurar passo-a-passo, preferindo a depuração por meio de "MessageBoxes" ou saídas na tela. Imagine, então, a dificuldade que não é para quem conseguiu às duras penas aprender a tornar um hábito a primeira passada do código novo em folha através do F10 começar a fazer coisas como configurar símbolos e digitar comandos esdrúxulos em uma tela em modo texto. Para piorar a questão, existem aqueles que defendem o uso unificado de uma ferramenta que faça tudo, como um telefone celular. Eu discordo. Quando a vantagem competitiva de uma ferramenta sobre outra é notável, nada pior que ficar preso em um ambiente legalzinho que faz o mínimo para você, mas não resolve o seu problema de deadlock.
Foi pensando nessa dificuldade que foi escrita uma apresentação nota dez por Robert Kuster que explica todas as minúcias importantes para todo programador iniciante e experiente na arte de "WinDbgear". "WinDbg. From A to Z!" é uma ferramenta tão útil quanto o próprio WinDbg, pois explica desde coisas simples que deve-se saber desde o início, como configurar símbolos, quanto assuntos mais avançados, como depuração remota. Até para quem já está no nível avançado vale a pena recapitular algumas coisas que já foram ditas no AWD.
Mesmo tentando ser sucinto, o assunto ocupou um conjunto de 111 transparências que demoram de uma a duas horas de leitura cuidadosa, se você não fizer testes durante o trajeto. Entre as coisas que eu li e reli, segue uma lista importante para nunca ser esquecida (entre parênteses o número das transparências que considero mais importantes):
- O que é são as bibliotecas de depuração do Windows e como elas podem te ajudar (6 e 9)
- O que são símbolos de depuração (11, 12, 14)
- Como funciona a manipulação de exceções e como depurar (18, 19, 85)
- Como configurar seu depurador para funcionar globalmente (20)
- Tipos de comandos no WinDbg (22)
- Configurando símbolos e fontes no WinDbg (24, 25)
- Interagindo com as janelas do WinDbg (33)
- Informações sobre processos, pilhas e memória (29, 41, 43, 45, 66)
- Informações sobre threads e locks (31, 55)
- Comandos úteis com strings e memórias (66)
- Avaliando expressões no WinDb: MASM e C++ (70, 71)
- Usando breakpoints no WinDbg (básico) (81)
- Usando breakpoints no WinDbg (complicado) (83, 84)
- Depuração remota (muito útil!) (87)
- Escolhendo a melhor ferramenta para o problema (fantástico!) (108)
Além da enchurrada de informações, o autor ainda explica a teoria com comandos digitados no próprio WinDbg, dando um senso bem mais prático à ferramenta. Ou seja, é útil tanto para os que aprendem por definições abstratas e lista de comandos quanto os que preferem já colocar a mão na massa e massacrar o bom e velho notepad.exe.
No final, duas dicas importantíssimas do autor para quem deseja se aventurar nesse mundo: leia a documentação do WinDbg (que também é ótima, apesar de bem mais extensa) e aprenda assembly (simplesmente essencial para resolver muitos problemas).
Se você ainda não teve tempo de se dedicar à depuração avançada em Windows e pensa que nunca terá, dedique duas horinhas divididas em períodos de 15 minutos por dia para explorar esse fantástico tutorial, que com certeza, se bem aplicado, reduzirá exponencialmente seu tempo de resolução de problemas.
Existe uma tradução para inglês desse texto no saite do próprio Robert Kuster, que usou-o como uma espécie de introdução.
# How to run anything as a service
Caloni, 2008-05-27 <computer> <english> [up] [copy]The biggest advantage running an application as a service, interactive or not, is to allow its start before a logon be performed. An example that happens to me is the need of debugging a GINA. In order to do this, I need the Visual Studio remote debugger be started before logon. The easiest and fastest solution is to run Msvcmon, the server part of debugging, as a service.
Today I've figured out a pretty interesting shortcut to achieve it.
An Alex Ionescu article talks about this command line application used to create, initiate and remove services. Even not being the article focus, I found the information pretty useful, since I didn't know such app. Soon some ideas starting to born in my mind:
"What if I used this guy to run notepad?"
Well, the Notepad is the default test victim. Soon, the following line would prove possible to run it in the system account:
sc create Notepad binpath= "%systemroot%\NOTEPAD.EXE" type= interact type= own
However, as every service, it is supposed to communicate with the Windows Service Manager. Since Notepad even "knows" it is now a superpowerful service, the service initialization time is expired and SCM kills the process.
>net start notepad The service is not responding to the control function. More help is available by typing NET HELPMSG 2186.
As would say my friend Thiago, "not good".
"Yet however", SCM doesn't kill the child processes from the service-process. Bug? Feature? Workaround? Whatever it is, it can be used to initiate our beloved msvcmon:
set binpath=%systemroot%\system32\cmd.exe /c c:\Tools\msvcmon.exe -tcpip -anyuser -timeout -1 sc create Msvcmon binpath= "%binpath%" type= interact type= own
Now, when we start Msvcmon service, the process cmd.exe will be create, that on the other hand will run the msvcmon.exe target process. Cmd in this case will only wait for its imminent death.
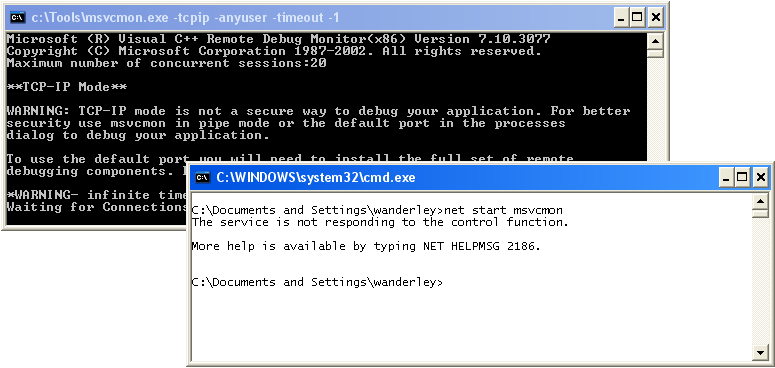
# Como criar uma LIB no Visual Studio
Caloni, 2008-05-29 <computer> [up] [copy]Quando se está começando no ramo, alguns detalhes nunca vêm à tona para o programador novato. Ele simplesmente vai codando até se sentir satisfeito com o prazer que é proporcionado pela prática da arte dos deuses de silício.
Isso, em termos práticos, quer dizer que todo o fonte vai ser escrito no mesmo ".c", que aliás talvez nem se dê ao luxo de possuir seu próprio ".h": pra quê, se as funções são todas amigas de infância e todas se conhecem?
No começo não existe nenhum problema, mesmo. O fonte vai ser pequeno. A coisa só complica quando não dá mais pra se achar no meio de tantos gotos e ifs aninhados. Talvez nessa hora o programador já-não-tão-novato até tenha descoberto que é possível criar vários arquivos-fonte e reuni-los em um negócio chamado projeto, e que existem IDEs, como o Visual Studio, que organizam esses tais projetos.
A partir daí, para chegar em uma LIB, já é meio caminho andado.
"Mas, afinal de contas, pra que eu preciso de uma LIB, mesmo?"
Boa pergunta. Uma LIB, ou biblioteca, nada mais é do que um punhado de ".obj" colocados todos no mesmo arquivo, geralmente um ".lib". Esses ".obj" são o resultado da compilação de seus respectivos ".c" de origem.
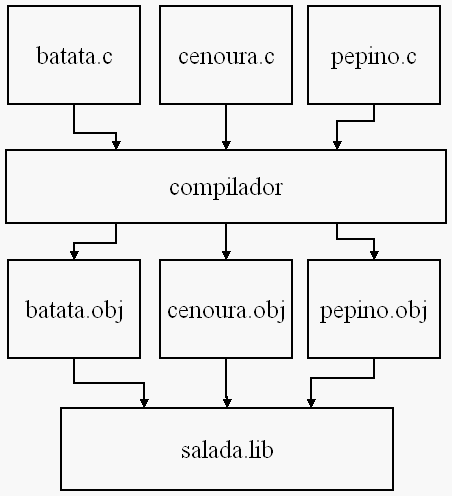
Alguns acreditam ser esse negócio de LIB uma pura perda de tempo, pois existem trocentas configurações diferentes (e incompatíveis) e trocentas compilações diferentes para gerenciar. Outros acham que o problema está no tempo de compilação, enquanto outros defendem o uso dos ".obj" de maneira separada. Esse artigo não presume que nem um nem outro seja melhor. Apenas ensina o que você precisa saber para criar sua primeira LIB usando o Visual Studio Express.
Vamos lá?
Após abrir o VS, tudo que precisamos fazer é ir em New, Project, e escolher a configuração de "Win32 Project":
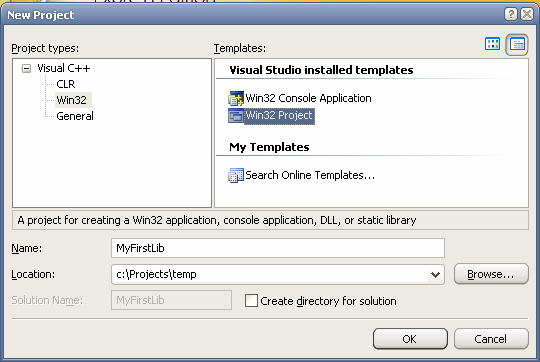
A seguir, escolhemos nas opções do assistente criar uma "Static library", e desmarcamos a opção de "Precompiled header" para evitar má sorte logo no primeiro projeto de LIB (má sorte significa horas procurando erros incríveis que você só irá fazer desaparecer se recompilar tudo com o uso do famigerado "Rebuild All"; espero que isso dê certo para você, para mim não tem funcionado).
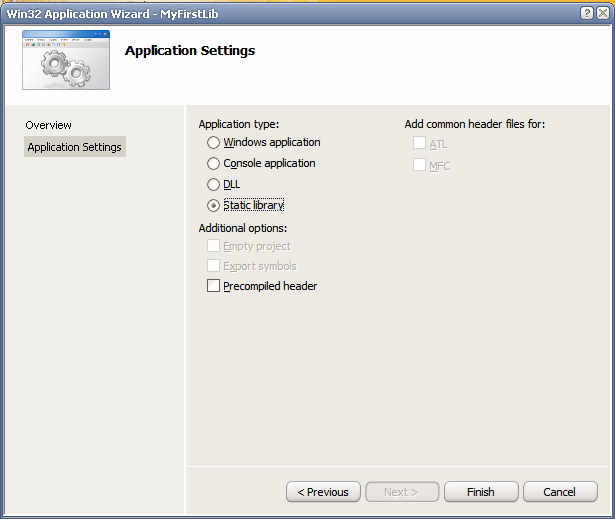
E pronto! Temos um projeto de LIB completo, funcional e... um tanto inútil. Mas, calma lá. Ainda não terminamos.
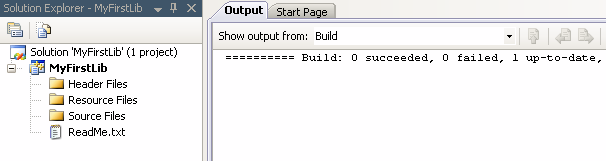
Conforme o programador consegue se livrar das maldições das mil dependências, aos poucos ele vai conseguindo novas funções genéricas e encaixáveis para colocar em sua coleção de objs. Essa com certeza não é uma tarefa fácil, mas ei, quem disse que esse trampo de programador seria fácil?
Vamos imaginar que você é muito do sem imaginação (típico de pessoas que mantêm blogues) e criou duas funções lindíssimas que somam e multiplicam dois números:
int sum(int a, int b)
{
return a + b;
}
int mult(int a, int b)
{
return a * b;
}
Não são aquelas coisas, mas são genéricas e, até certo ponto, "úteis" para o nosso exemplo.
Agora, tudo que temos que fazer é criar dois arquivos: mymath.c e mymath.h. No mymath.c, colocamos as funções acima exatamente como estão. No mymath.h, colocamos apenas as declarações dessas duas funções, apenas para avisar outros ".c" que existem duas funções que fazem coisas incríveis nessa nossa LIB.
/* soma dois números */ int sum(int a, int b); /* multiplica dois números */ int mult(int a, int b);
Adicionamos esses dois arquivos ao projeto (se já não estão), e voilà!
------ Build started: Project: MyFirstLib, Configuration: Debug Win32 ------ Compiling... mymath.c Creating library... Build log was saved at "file://c:\Projects\temp\MyFirstLib\Debug\BuildLog.htm" MyFirstLib - 0 error(s), 0 warning(s) ========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========
Para usar uma LIB temos inúmeras maneiras de fazê-lo. A mais simples que eu conheço é criar um novo projeto no mesmo Solution de sua LIB. Um console, por exemplo:
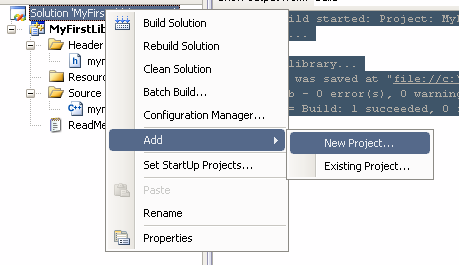
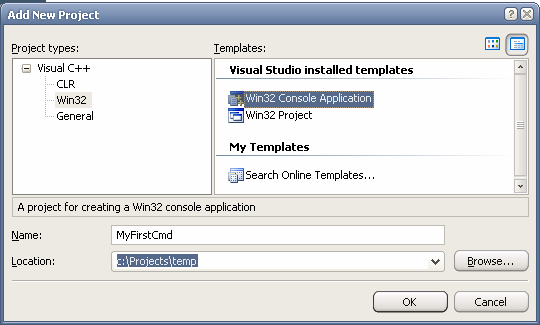
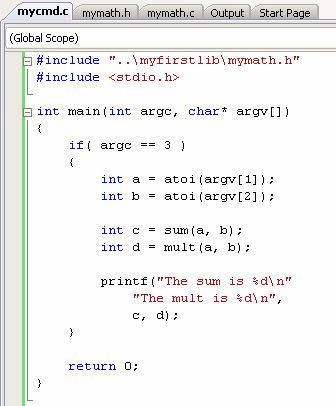
Se você seguiu todos os passos direitinho, e eu estou assumindo que você já sabia como criar um projeto console, sua saída da compilação talvez seja mais ou menos essa:
------ Build started: Project: MyFirstCmd, Configuration: Debug Win32 ------ Compiling... mycmd.c Linking... mycmd.obj : error LNK2019: unresolved external symbol mult referenced in function main mycmd.obj : error LNK2019: unresolved external symbol sum referenced in function main c:\Projects\temp\MyFirstLib\Debug\MyFirstCmd.exe : fatal error LNK1120: 2 unresolved externals Build log was saved at "file://c:\Projects\temp\MyFirstCmd\Debug\BuildLog.htm" MyFirstCmd - 3 error(s), 0 warning(s) ========== Build: 0 succeeded, 1 failed, 1 up-to-date, 0 skipped ==========
Dois erros! Ele não achou os símbolos mult e sum. Mas eles estão logo ali! E agora?
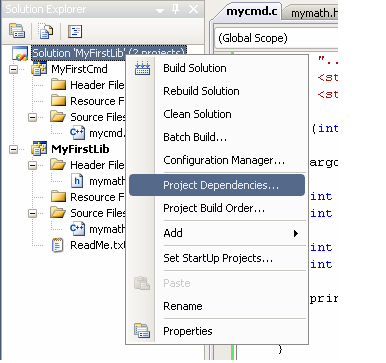
Nada a temer: tudo que temos que fazer é falar para o Solution que o projeto myfirstcmd depende do projeto myfirstlib:
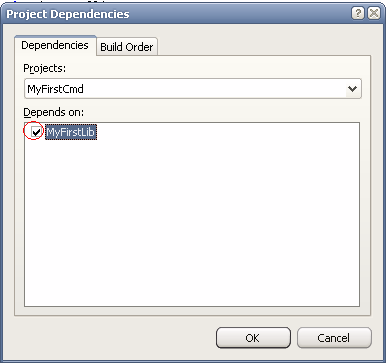
------ Build started: Project: MyFirstCmd, Configuration: Debug Win32 ------ Linking... Embedding manifest... Microsoft (R) Windows (R) Resource Compiler Version 6.0.5724.0 Copyright (C) Microsoft Corporation. All rights reserved. Build log was saved at "file://c:\Projects\temp\MyFirstCmd\Debug\BuildLog.htm" MyFirstCmd - 0 error(s), 0 warning(s) ========== Build: 1 succeeded, 0 failed, 1 up-to-date, 0 skipped ==========
Isso resolve o problema de organização e compilação quando temos dezenas de ".c" espalhados pelo projeto. Existem melhores alternativas, mais bem organizadas e estruturadas, inclusive lingüisticamente falando. No entanto, tudo tem sua hora, e só se deve preocupar-se com isso quando sua solução tiver algumas dezenas de ".lib". Até lá!
[2008-04] [2008-06]