- Reflexo
- Try-catch flutuante
- Conversor de Houaiss para Babylon - parte 2
- Linux e o DHCP
- Aprendendo assembly com o depurador
- Guia básico de controles de código distribuído
- Crash Dump Analysis: o livro
- Ode ao C++
- CSI: Crashed Server Investigation?
- Seminário CCPP Portabilidade e Performance
- A solução mais simples é usar a fonte, Luke!
# Reflexo
2008-04-01 quotes self now [up] [copy]O padrão do pensamento cria um reflexo amplificado de si mesmo. Tolle, Eckhart (O Poder do Agora, 1997).
# Try-catch flutuante
2008-04-03 computer ccpp blog [up] [copy]Esse detalhe da linguagem quem me fez descobrir foi o Yorick, que costuma comentar no blogue e tive o prazer de conhecer em EPA-CCPP 4: nossa comunidade ganhando forma.
É possível, apesar de bizarro, colocar um bloco try-catch em torno da lista de inicialização de variáveis de um construtor. Essa característica da linguagem permite que possamos capturar alguma exceção lançada por algum construtor de algum membro da classe. A construção em código ficaria no estilo abaixo:
Class::Class() try : initialization-list
{
// Class constructor body
}
catch(...) // note: this IS right!
{
// do something about
// just like "throw" over here
}
Apesar dessa capacidade, não conseguimos parar o lançamento da exceção. Após seu lançamento, caímos no bloco catch abaixo do corpo do construtor e a exceção é lançada novamente, como se houvesse uma intrução throw no final do catch.
O exemplo abaixo demonstra um código de uma classe que captura a exceção durante a inicialização dos membros. Na seguida o catch da função main é executada, provando que a exceção de fato não é "salva" no primeiro bloco.
#include <iostream>
/* This class explodes */
class Explode
{
public:
Explode(int x)
{
m_x = x;
throw x;
}
void print()
{
std::cout << "The number: " << m_x << std::endl;
}
private:
int m_x;
};
/* This class is going to be exploded */
class Victim
{
public:
Victim() try : m_explode(5)
{
std::cout << "You're supposed to NOT seeing this...\n";
}
catch(...)
{
std::cerr << "Something BAD hapenned\n";
std::cerr << "We're going to blow up\n";
// just like 'throw' over here
}
void print()
{
m_explode.print();
}
private:
Explode m_explode;
};
int main()
{
try
{
Victim vic;
}
catch(...)
{
std::cerr << "Something BAD BAD happenned...\n";
}
}
Testei esse código nos seguintes compiladores:
- Visual Studio 6. Falhou, demonstrando desconhecer a sintaxe.
- Borland C++ Builder 5. Falhou, demonstrando desconhecer a sintaxe.
- Borland Developer Studio 4. Falhou, com o mesmo erro.
- Visual Studio 2003. Comportamento esperado.
- Visual Studio 2005. Comportamento esperado.
- Visual Studio 2008. Comportamento esperado.
- G++ (no Cygwin). Comportamento esperado.
A saída esperada é a seguinte:
Something BAD hapenned We're going to blow up Something BAD BAD happenned...
// Comments
2008-04-10 Alberto Fabiano:
Meu caro,
Só por curiosidade, eu também fiz o teste nos seguintes compiladores:
- ICC, Intel C++ Compiler 10.1: Comportamento OK
- DMC, Digital Mars C++ Compiler 8.48: Comportamento OK
[]s
2008-04-11 Thiago Adams:
Também pode ser usado assim:
void f() try
{
throw 1;
//throw "";
}
catch (int) {
throw;
}
catch (...) {
std::terminate();
}
Que poderia simular algo assim:
void f() throw(int)
{
}
2008-04-13 Caloni:
Alberto: valeu pelos testes! É bom saber que existem outros compiladores tão bons quanto o GCC e o VC no mercado.
Thiago: isso sim é bem esquisito! Te confesso que nem entendi direito o uso desse exemplo.
2008-04-14 Thiago R Adams:
Quando uma função possui a especificação das exceções significa que ela só pode lançar aquelas exceções. Caso seja lançado outra, o std::unexpected(); é chamado. O compilador VC++ não obedece essa especificação do C++. Mas é possível gerar o código na mão, usando aquela sintaxe com o try.
Então por exemplo:
void f() throw(int); //num compilador que obedece o padrao
É equivalente a fazer "na mão":
void f() try
{
//algo...
}
catch (int) {
throw;
}
catch (...) {
std::unexpected()
}
Este é outro uso curioso do try que eu resolvi comentar aqui.
2008-04-16 PopolonY2k:
Grande blog...
... Caloni, não o conhecia anteriormente e vejo que darei vários "pitacos" por aqui sempre que puder.
Sobre o bloco try catch(...) em inicialização de variáveis e objetos em construtores, vale ressaltar o que o amigo Thiago Adams citou acima, que é o uso em qualquer tipo de função de C++, mas alguns cuidados devem ser tomados conforme reportado no padrão ANSI de C++ proposto em 1998.
Sobre não ter funcionado em alguns compiladores reportados por você, como o Visual Studio 6 - VC++ 6.0, Borland C++ Builder 5 e o Borland Studio Developer Studio 4, deve deixo registrado aqui que a proposta de try catch na inicialização de funções veio na versão final da proposta do padrão ANSI para C++ em 1998, portanto compiladores, como o Visual C++ 6.O (Visual Studio 6) e Borland C++ Builder 5 já estavam no mercado e portanto não existia maneira de que os mesmos respeitassem a nova sintaxe proposta pelo ANSI.
Segue um artigo de referência no Dr. Dobbs (2026-03-23 Dr. Dobbs no more).
Um abraço,
PopolonY2k
PlanetaMessenger.org
# Conversor de Houaiss para Babylon - parte 2
2008-04-08 computer projects blog [up] [copy]Após algumas semanas de suspense, chegamos finalmente à nossa segunda e última parte da saga do dicionário Houaiss.
Como devem estar lembrados, a primeira parte se dispôs a desmontar a ofuscação usada nos arquivos do dicionário para permitir nossa posterior análise, com o simples e justo objetivo de importá-lo para o Babylon, cujas funcionalidades de busca são bem superiores.
Feito isso, agora nos resta entender a estrutura interna do Houaiss para montar um conversor que irá ajudar o Babylon Builder a construir nosso Houaiss-Babylon. Simples, não?
A primeira parte de toda análise é a busca por padrões com um pouco de bom senso. O Houaiss armazena suas definições em um conjunto de arquivos de nome deahNNN.dhx (provavelmente deah de Dicionario Eletrônico Antônio Houaiss). Os NNN variam de 001 -- o maior arquivo -- até 065, com algumas poucas lacunas, em um total de 53 arquivos originais.
O nosso rústico importador fez o trabalho de desofuscar todos os 53 arquivos usando a mesma lógica encontrada pelo WinDbg: somar o valor 0x0B para cada byte do arquivo. Dessa forma foram gerados 53 arquivos novos no mesmo diretório, porém com a extensão TXT.
Partindo do bom senso, abriremos o arquivo maior, deah001.txt, e abriremos o próprio dicionário Houaiss, em busca de um padrão que faça sentido. Como poderemos ver na figura abaixo, o padrão inicial não é nem um pouco complicado.
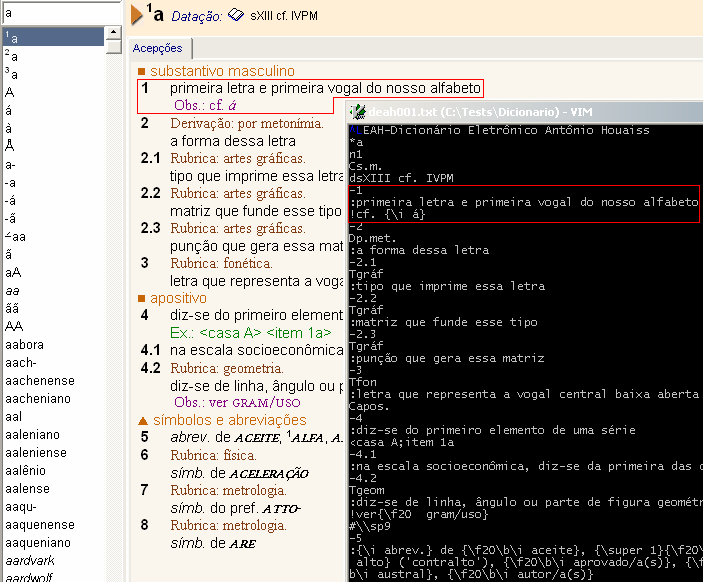
As duas primeiras observações do formato do arquivo nos dizem que (1) o primeiro caractere de cada linha indica o conteúdo dessa linha, e que (2) a formatação dos caracteres é feita dentro de um par de chaves {}.
Dessa forma, podemos começar a construir nosso interpretador de arquivos do Houaiss em seu formato básico.
#include <iostream>
#include <string>
int main()
{
char cmd; // comando da linha atualmente lida
string line; // linha atualmente lida
int count = 0; // contador de palavras
while( getline(cin, line) )
{
cmd = line[0]; // guardamos o comando
line.erase(0, 1); // tiramos o comando da linha
format(line); // formatação da linha (explicações adiante)
switch( cmd ) // que comando é esse?
{
case '*': // verbete
++count;
cout << '\n' << line << '\n';
break;
case ':': // definição
cout << line << "<br>\n";
break;
}
}
return 0;
}
Simples e funcional. Com esse código já é possível extrair o básico que precisamos de um dicionário: os vocábulos e suas definições.
Para conseguir mais, é necessário mais trabalho.
A formatação segue o estilo já identificado, de forma que podemos aos poucos montar um interpretador de formatação para HTML, que é o formato reconhecido pelo Babylon Builder. Podemos seguir o seguinte molde, chamado no exemplo de código anterior:
void format(string& str)
{
string::size_type pos1 = 0;
string::size_type pos2 = 0;
while( (pos1 = str.find('<')) != string::npos )
str.replace(pos1, 1, "<");
while( (pos1 = str.find('>')) != string::npos )
str.replace(pos1, 1, ">");
while( (pos1 = str.find('{')) != string::npos )
{
if( pos1 && str[pos1 - 1] == '\\' ) // caractere de escape
str.replace(pos1 - 1, 2, "{");
else
{
string subStr;
pos2 = str.find('}', pos1);
if( pos2 != string::npos )
subStr = str.substr(pos1 + 1, pos2 - pos1 - 1);
else
subStr = str.substr(pos1 + 1);
istringstream is(subStr);
string fmt;
string word;
is >> fmt;
getline(is, word);
if( word[0] == ' ' )
word.erase(0, 1);
if( fmt.find("\\i") != string::npos )
word = "<i>" + word + "</i>";
if( fmt.find("\\b") != string::npos )
word = "<b>" + word + "</b>";
if( fmt.find("\\f20") != string::npos )
word = "" + word + "";
if( fmt.find("\\super") != string::npos )
word = "" + word + "";
if( pos2 != string::npos )
str.replace(pos1, pos2 - pos1 + 1, word);
else
str.replace(pos1, pos2, word);
}
}
}
Algumas partes ainda estão feias, eu sei. Mas, ei, isso é um código de ráquer, não é mesmo? Além do mais, se isso não é desculpa suficiente, estamos trabalhando em uma versão beta.
A partir dessas duas funções é possível dissecar o primeiro arquivo do dicionário, e assim, construirmos a primeira versão interessante do Houaiss no Babylon.
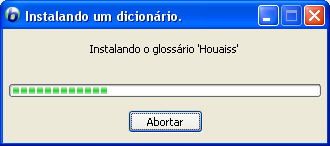
Como é normal a qualquer dicionário do Babylon, podemos instalá-lo simplesmente clicando duas vezes no arquivo (em uma máquina com Babylon previamente instalado).
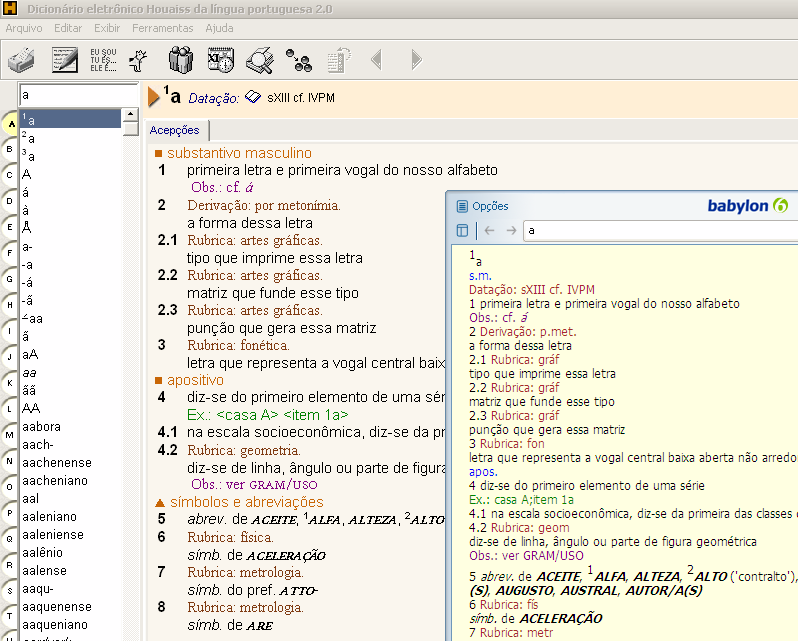
O projeto atual está um tanto capenga, mas já desencripta os arquivos do Houaiss e gera o projeto do Babylon Builder sozinho. Em anexo já está um projeto do Babylon Builder. Basta copiar o arquivo Houaiss.txt para a pasta do projeto e gerar o projeto do Babylon.
// Comments
2009-02-09 Renan de Araujo:
Olá! queria agradecer pelo esforço de criar o programa, mas tenho também uma pergunta:
Eu gostaria saber se é possível fazer esse programa gerar a tabela que vai para o babylon baseada em XML e não HTML. Por que eu gostaria de converter o arquivo final para o dicionário do mac, que tenho um conversor de babylon pro dict.app, mas o problema é o que o software não sabe interpretar HTML, então preciso de uma fonte baseada em XML
Grato pela atenção!
2008-04-21 Angélica:
Eu tenho um dicionário Houaiss 2.0 e o Babylon 7, mas não entendo nada de computação e portanto não entendi o que devo fazer para convertê-lo ao formato Babylon. Baixei a pasta acima [VERSÃO ATUAL] mas não tenho a mínima idéia de como usá-la.
1. Da onde extraio o arquivo Houaiss.txt?
2. Qual é a 'pasta do projeto'?
3. Uma vez localizado o arquivo Houaiss.txt, se eu copiá-lo para a referida pasta, o que devo fazer? Clicar aonde?
2008-04-22 Angélica:
MUITO OBRIGADO pelas dicas. Segui todas (menos a do Administrador, apesar de estar usando Windows Vista). Será que foi este o problema?
É que cheguei até o item 7, mas quando o Babylon builder entrou em ação recebi oma mensagem de erro.
Copiei a janela do erro com Snagit e se houver um modo posso enviá-la. Para tanto precisaria de um e-mail... O meu já está anotado acima.
Mesmo assim, mais uma vez obrigada. VALEU!!!
2008-04-22 Angélica:
Oi novamente,
Tentei mais vezes, agora como administradora mas mesmo assim não deu certo.A mensagem de erro é a seguinte:
Value of '-2' is not valid for 'Value'. 'Value'should be between 'minimum' and 'maximum'. Parameter name: Value
Mas não é só o '-2' que tem problema. Quase todos os valores entre 1 e 18 trazem a mesma mensagem. E não há como ignorá-las, pois a construção do glossário pára em 18%, volta para o começo e pára de novo.
Obrigada pela atenção,
Angélica
2008-04-22 Caloni:
Olá, Angélica.
Por essa eu não esperava. As respostas para suas perguntas são:
1. Não extrai. Ele deve ser gerado automaticamente no diretório de instalação do Houaiss, pasta Dicionario.
2. A "pasta do projeto" é o diretório que você extraiu do linque "versão atual". Isso é, depois de você ter compilado o projeto (que é a geração do executável que faz todo o trabalho).
3. Após gerado o arquivo Houaiss.txt, você deveria copiá-lo para a pasta do projeto.
Bem, aqui vão algumas dicas e passos para fazer a conversão, mesmo sem conhecimentos de programação e informática avançada. Disponibilizei aqui uma versão compilada do projeto. É esse executável que você irá usar para todo o trabalho.
1. Primeiro, certifique-se que instalou o Houaiss com a opção de copiar os arquivos para o disco rígido.
2. Copie o arquivo Houaiss2Babylon.exe para a pasta de instalação do Houaiss e execute. A conversão irá demorar alguns minutos, e durante esse tempo você deve ver uma tela preta sendo exibida. Se você usa Windows Vista, talvez seja necessário executar o programa com direitos de administrador.
3. Quando a tela preta sumir, o programa já deve ter desencriptado o Houaiss, e dentro da pasta Dicionario de instalação existirão alguns arquivos TXT que você pode apagar, e o Houaiss.txt, que você NÃO deve apagar ainda.
4. Para o resto da conversão, você precisa do Babylon Builder. Instale-o antes de continuar.
5. Copie o arquivo de projeto (Houaiss.grp) e o ícone (Houaiss.ico), que estão na pasta de projeto, para a pasta Dicionario onde está o arquvo Houaiss.txt.
6. Dê um duplo clique no arquivo Houaiss.grp. Para que tudo funciona é ESSENCIAL que na mesma pasta estejam os arquivos Houaiss.ico e Houaiss.txt, este gerado nos passos anteriores.
7. Quando a tela do Babylon Builder aparecer, escolha a opção Quick Build. Espere a conversão terminar.
8. Se você chegou até aqui, um arquivo de dicionário Babylon foi gerado. Se não, algum problema ocorreu. Nesse caso, descreva o que aconteceu, por favor.
[]s
2008-04-23 Angélica:
Oi Wanderley,
O Bloco de Notas abriu, mas disse que a operação é inválida:
Start building... Invalid project file name: Houaiss.gpr
Só não sei se abri o prompt da maneira correta. Fui para Iniciar > Procurar, escrevi 'cmd' e selecionei 'cmd.exe' e o prompt se abriu. Depois eu simplesmente colei o comando sugerido acima e dei um 'enter'.
Mais uma vêz, MUITO obrigada!
2008-04-23 Caloni:
Olá, Angélica.
Eu acho que você está com um problema parecido com o meu durante alguns testes iniciais. Tente fazer o seguinte: você já tem o Houaiss.txt e todos os arquivos estão na mesma pasta, certo? Tente abrir um prompt de comando dentro dessa pasta e digite os seguintes comandos:
set path=%path%;%programfiles%\Babylon\Babylon Glossary Builder BuilderWizard /Build Houaiss.gpr
Se dessa forma funcionar, no final da conversão deverá ser aberto um arquivo no Bloco de Notas indicando que está tudo OK.
Caso não dê certo, por favor, me avise, que irei tentar corrigir quando tiver um tempinho, ok?
[]s
2008-04-23 Angélica
DEU CERTO!!!
Agora eu consegui abrir o prompt DENTRO da pasta (usando a função 'Open Command Prompt here' do menu de contexto com a tecla SHIFT), e tudo correu às mil maravilhas.
O dicionário já esta instalado no Babylon e funcionando. Se você fizer novas modificaçôes avise-nos. Marcarei este site e voltarei sempre em busca de modificações.
MUITÍSSIMO OBRIGADA,
Angélica
2008-04-23 Caloni:
Olá, Angélica.
Puxa, fico muito feliz que você tenha conseguido. Sinceramente, não imaginei que alguém fosse realmente usar minha solução. Fico mesmo muito contente.
Quando tiver mais tempo pretendo fazer mais análises do que dá pra melhorar na conversão. Acredito que uma tela descrevendo os passos (que nem o Babylon Builder) deve ajudar bastante os usuários.
[]s
2008-05-18 Ricardo:
Olá, Caloni.
Esbarrei por aqui com seu projeto e achei interessante, compilei com o Visual C++ 2008 Express Edition. Foi criado o arquivo Houaiss2Babylon.exe mais ele não está convertendo os arquivos.
A mensagem do Debug é:
'Houaiss2Babylon.exe': Loaded 'C:\Tests\Houaiss2Babylon\Release\Houaiss2Babylon.exe', Symbols loaded. 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\ntdll.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\kernel32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\user32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\gdi32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\advapi32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\rpcrt4.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\WinSxS\ x86_Microsoft.VC90.CRT_1fc8b3b9a1e18e3b_9.0.21022.8_x-ww_d08d0375\ msvcr90.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\WinSxS\ x86_Microsoft.VC90.CRT_1fc8b3b9a1e18e3b_9.0.21022.8_x-ww_d08d0375\ msvcp90.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\shimeng.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\imm32.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\lpk.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\usp10.dll' 'Houaiss2Babylon.exe': Loaded 'C:\WINDOWS\system32\msvcrt.dll' 'Houaiss2Babylon.exe': Unloaded 'C:\WINDOWS\system32\shimeng.dll' The program '[1260] Houaiss2Babylon.exe: Native' has exited with code -1 (0xffffffff).
Minha experiência com C++ é quase zero, sem querer abusar (já abusando) tem alguma dica?
2008-05-19 Caloni:
Olá, Ricardo.
Uma dica rápida: use o linque (2026-03-21 link quebrado) que eu disponibilizei com o projeto compilado e siga as instruções nos comentários anteriores.
Uma dica mais demorada: depure passo-a-passo e me diga em que ponto que o programa está saindo. A partir daí teremos dados mais concretos para dizer o que está acontecendo.
[]s
2008-05-19 Ricardo:
Olá Caloni.
Eu bem que já havia tentado, mais o linque está quebrado.
Quanto à dica mais demorada, o Visual C++ 2008 Express importa o projeto (The solution or project you are openig was created in a previous version of Visual Studio.) e compila de forma aparentemente normal só que o executável quando colocado na pasta de instalação do Houaiss e devidamente acionado não gera arquivo nenhum.
Obrigado pela atenção.
2008-05-23 Major Quaresma:
Muito obrigado a todos,
Não sei NADA de programação. Pra ser mais preciso, comecei - e logo desisti - de um famoso curso da UFMG de programação em C. Meu programa mais complexo pedia que o usuario inserisse um numero e desse enter, ai o meu "programaço" pedia um seguindo numero e quando o usuario apertasse enter o meu "programaço" somava os dois numeros, dividia-os por 2 e mostrava o resultado!!! Uau!!! Que máximo!!! Mas foi útil pois pelo menos eu pude compilar o programinha para extrair os dados do Houaiss... Muita tentativa e erro ate eu entender o que estava fazendo, mas funcionou... Agora vou tentar passar a base de dados para SlovoEd (PalmOS).
2008-05-26 Caloni:
Olá novamente, Ricardo.
Disponibilizei novamente uma versão compilada no mesmo linque (2026-03-21 quebrado) dos comentários. Tente usar esta versão.
[]s
2008-05-26 Caloni:
Olá, Major.
Fico feliz que tenha conseguido compilar e usar meu pequeno e singelo programinha. Você é uma inspiração para que outros tentem mais um pouco.
[]s
2008-07-09 Roberto Bechtlufft:
Estou interessadíssimo nisso, mas tive algum problema. Quando executo o Houaiss2Babylon nada acontece. A tela do cmd só pipoca rapidamente na tela. Quando tento executar pelo cmd, entro o comando e nada. Minha pasta Dicionário tem vários arquivos dhx.
2008-07-10 Caloni:
Olá, Roberto.
Lembre-se que para aplicar a conversão é necessário que você tenha o Houaiss, o Babylon e o Babylon Builder instalados em seus lugares padrões. Caso você tenha, poderia me informar o sistema operacional utilizado e o idioma?
[]s
2008-07-11 Fabricio Morrone:
Caloni,
Tive o mesmo problema do Roberto. Tenho o Houaiss instalado assim como o Babylon e ainda não instalei o Babylon Builder. Uso Windows Vista em português. Não sei o que fazer, pois acho que sei menos de programação que o Major!!!
2008-07-11 Caloni:
Olá, Fabrício.
Não se preocupe. Apenas peço que tenha paciência que em breve irei lançar uma versão mais robusta com geração de log, o que me permitirá descobrir o que está acontecendo nas suas execuções.
No momento, poderia fazer mais um teste? Tente executar o programa dentro de um prompt de comando com direitos administrativos E nível de integridade alto. Você consegue isso clicando com o outro botão do mouse sobre o atalho para o prompt e escolhendo "Executar como Administrador", ou algo do tipo.
Obrigado a todos pelo feedback dos problemas da versão beta.
[]s
2008-07-11 Fabricio Morrone:
Olá Caloni
Executei como vc pediu e nada aconteceu. O meu Houaiss é a versão 1.0.5, de agosto de 2002. Será que é por isso que não dá certo?
2008-07-13 Adrian:
Olá caloni,
Estou interessadíssimo nisso, mas tive algum problema. Quando executo o Houaiss2Babylon na pasta c:\houaiss nada acontece, o mesmo se executo na pasta c:\houaiss\dicionario. A tela do cmd só pipoca rapidamente na tela. Quando tento executar pelo cmd, entro o comando e nada ocorre. Uso o Windows XP sp2, houaisss versao 1.05, instalei o babylon 7 e o babylon builder.
Agradeço pela atenção.
2008-07-14 Caloni:
Olá a todos.
Foi gerada uma nova versão (2026-03-21 link quebrado) com diversas mensagens de erro. Se puderem testar novamente, agradeço muito.
[]s
2008-07-14 Fabricio Morrone:
Oi Caloni
Testei essa nova versão, ela dá várias mensagens de erro mesmo, mas não cria os arquivos txt. As mensagens são para cada arquivo da pasta Dicionario (Erro abrindo arquivo "C:\Arquivo de Programas\Houaiss\Dicionario\deah***.dhx". Erro de sistema numero 3"). Essa mensagem aparece também com a extensão txt.
Por enquanto, obrigado por tentar nos ajudar!!
2008-07-15 Caloni:
Olá, Fabricio.
A mensagem do erro número 3 é "O sistema não pode encontrar o caminho especificado". Você poderia verificar se o caminho que está sendo mostrado na mensagem é exatamente o que existe em sua máquina? Grato.
[]s
2008-12-22 Willians:
Olá Caloni
Será que através do seu método seria possível converter o Houaiss para um arquivo com extensão ".PDB", lido pelo Roadlingua, em versões para palm e Windows mobile?
Parabéns, muito obrigado e um grande abraço.
2008-12-23 Caloni:
Olá, Willians.
Se o formato do Palm for aberto, ou o Roadlingua possuir um conversor de um formato aberto para seu formato, então com certeza! Se você der uma olhada no artigo em que fazemos a engenharia reversa do dicionário vai perceber que seu formato interno é muito simples de interpretar.
[]s
2008-12-23 Willians:
Olá Wanderley
Muito obrigado meu caro, sem querer abusar, mas o algoritmo utilizado na interpretação do Houaiss 2.0 é aplicável ao Houaiss 1.0 (não consigo achar o 2.0 por aqui)?
Mais uma vez, o meu muito obrigado, um feliz natal pra você e um ano novo igualmente agradável.
2008-12-24 Caloni:
Olá, Willians.
Até onde eu sei, iniciei minha análise na versão 1.0, portanto deve funcionar. Ainda está na minha lista de tarefas dar uma olhada em por que o conversor não está funcionando nessa versão, apesar da desencriptação seguir o mesmo princípio.
Igualmente.
[]s
2008-12-25 Willians:
Olá Wanderley
Evoluí um pouco, todavia, surgiu uma caixa de diálogo com a seguinte mensagem: 'Erro abrindo arquivo "C:\Windows\dicionário\deah049.dhx". Erro de sistema número 2.' Sempre que clico no botão "OK" é aberta uma nova caixa de diálogo com texto análogo, só se modificando o número do arquivo, que passa a ser "deah050.dhx", e assim sucessivamente, até o arquivo "deah059.dhx", se não me engano. Acontece que, de fato, ao verificar a pasta "Dicionario", constatei que os arquivos a que me referi acima, não existem. Será que o procedimento de conversão foi bem sucedido e, na verdade, o que ocorreu foi a não previsão, na sua rotina, da inexistência desses arquivos para a versão Houaiss 1.0?
Novamente, muito obrigado e um grande abraço.
Detalhe: Não foi gerado o arquivo "Houaiss.txt"
2008-12-26 Caloni:
Olá, Willians.
Agora que me toquei: você deve estar usando a versão antiga, não?
A versão para usuário (ainda beta) estava disponível em outro artigo.
Boa sorte!
2008-12-26 Willians:
Olá Wanderley
Funcionou! Arrisco-me a afirmar que talvez tenha descoberto o porquê do aplicativo não funcionar no Houaiss 1.0 (por enquanto só posso especular, uma vez que não disponho da versão Houaiss 2.0). Acho que isso ocorre justamente pela ausência dos arquivos que vão do “deah049.dhx” ao “deah059.dhx” na versão Houaiss 1.0 (eles provavelmente devem existir na versão 2.0). Pra tentar “enganar” o teu aplicativo, criei arquivos de texto vazios com o nome e extensão daqueles ausentes e funcionou. Percebi, analisando o algoritmo que você disponibilizou a seguinte linha (o início de um “laço”):
for( int fileIdx = 1; fileIdx ...
Acredito que quando a rotina se depara com a quebra da sequência numérica, ocorra o “bug”.
Enfim, espero não ter falado muita besteira.
Um abraço e muito obrigado!
2008-12-27 Willians:
Olá Caloni
Tenho até vergonha de te aborrecer com isso, mas estava tentando alterar a tua fonte com o propósito de tornar o arquivo de texto "Houaiss.txt" compatível com o programa "awmaker", que converte arquivos de texto para a base de dados de dicionários do "roadlingua", o que faria com que todos nós, além de podermos usar o Houaiss no Babylon, também pudéssemos usá-lo em celulares, smartfones, palms, etc. Todavia, para que isso possa funcionar corretamente, tenho de adequar o arquivo de texto "Houaiss.txt" para o padrão ”.csv”, ou seja, a palavra procurada (ou verbete) deve estar separada da sua respectiva definição por um ";" (ponto-e-vírgula), e toda a definição deve estar em um bloco de texto único, sem os marcadores HTML. Ademais, para poder fazer a quebra interna do texto dever-se-ia usar o delimitador "\n" (sem as aspas) invés do “enter” ou qualquer outro tipo de tabulação. O problema é que não conheço muito da linguagem "C", quase nada, pra ser mais preciso, e sempre que tento fazer esse delimitador ser adicionado no arquivo de texto, o que ocorre, na verdade, e a quebra automática do texto da definição (o que não pode acontecer, sob pena de descaracterizar o padrão .csv), não aparecendo o já referido delimitador no texto.
Será que pode me ajudar mais uma ver amigo.
Grande abraço.
2008-12-29 Willians:
Olá Caloni
Consegui alterar o código-fonte do teu aplicativo e fazer funcionar a base de dados do “Houaiss 1.0” no "Windows Mobile 6", que é o sistema operacional do meu celular (mas é possível fazer o mesmo para o sistema PALM), através do “Roadlingua”, para tanto, além de gerar um arquivo de texto compatível com o "awmaker", tive de dividir os arquivos “.pdb”, gerados por intermédio desse último, em 5 arquivos menores (“Houaiss_A-C.pdb”, “Houaiss_D-G.pdb”, “Houaiss_H-N.pdb”, “Houaiss_O-T.pdb”, “Houaiss_U-Z.pdb”), tive de fazê-lo por que se os mantivesse em único arquivo ele ficaria muito pesado, provocando travamentos no celular (coloquei essa hipótese à prova). Esse artifício atrapalha um pouco o processo de pesquisa, mas não a inviabiliza, pelo contrário, é condição para o seu funcionamento (pelo menos da maneira como vejo).
A propósito, se interessar, mandei cópia das alterações feitas no código-fonte por intermédio da tua página de contato.
Mais uma vez, muito obrigado e um grande abraço!
2008-12-29 Caloni:
Olá, Willians.
Antes de tudo, parabéns pela sua iniciativa e dedicação, mesmo não conhecendo muito da linguagem, de tentar adaptar o programa para seus objetivos. Fico muito feliz que tenha conseguido, e conseguido sozinho, o que prova sua capacidade de resolver problemas aparentemente muito difíceis se tentado sozinho.
Olharei seu código-fonte com calma. Obrigado por compartilhá-lo.
[]s
2008-12-29 Willians:
Oh! Caloni, na verdade sou eu quem deve agradecer. Um grande abraço e um feliz ano novo pra ti.
2009-02-10 Caloni:
Olá, Renan.
Uma vez que conseguimos desencriptar o conteúdo do Houaiss através de engenharia reversa, e seu formato aberto é facilmente interpretável, podemos convertê-lo para qualquer formato, limitado apenas à imaginação =)
Dessa forma, se você for programador, recomendo que dê uma olhada no artigo sobre a engenharia reversa aplicada e criar sua própria solução.
Se você não é, então terá que esperar pelo menos uns dois meses, depois que eu voltar de férias e ter algum tempo para pensar em uma futura nova versão =)
[]s
# Linux e o DHCP
2008-04-11 computer blog [up] [copy]Quando procuramos no google por "linux dhcp", o que vem em resposta são diversas dicas, tutoriais, documentos oficiais e palpites sobre como configurar um servidor Linux.
Muito bem. E a outra ponta da história?
[Testes feitos em um Fedora 8, não me pergunte mais detalhes]
O primeiro linque útil encontrado foi a documentação da Red Hat. Além disso seguem alguns macetes que eu descobri no decorrer do percurso. A primeira coisa a ser configurada é o arquivo /etc/sysconfig/network. Nele devemos, em uma configuração simplista, colocar uma única linha:NETWORKING=yesTive alguns problemas com a entrada NETWORKING_IPV6, ou algo do gênero. A comunicação com o servidor DHCP da rede simplesmente não funcionava com essa linha, deixando o computador sem IP durante o boot. Má configuração do servidor? Pode até ser. Porém, não quis entrar nesses meandros.
Por isso, se houver a linha sobre IPV6 e você tiver problemas, comente-a temporariamente.
O passo seguinte é configurar a interface de rede, que é no fim das contas a representação da sua placa. Para isso temos alguns arquivos em /etc/sysconfig/network-scripts no formato ifcfg-nome-da-interface. Se você digitar ifconfig na linha de comando terá os nomes de interface disponíveis. No meu caso, eth0.
vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes :wq
Note que o valor BOOTPROTO é realmente BOOTPROTO, com um O no final. Tive alguns problemas de soletrar também nesse caso, o que me gerou mais alguns reboots mal-sucedidos.
Bem, o que isso faz? Basicamente, manda o Linux utilizar o protocolo DHCP, procurando na rede algum servidor que lhe dê algum IP válido. Só isso. O resto ele faz dinamicamente.
Inclusive alterar automaticamente o arquivo /etc/resolv.conf. Nele estão definidas algumas coisas como o domínio de nomes que estamos e os IPs de onde buscar a resolução de nomes.
Feito isso, como se costuma dizer, voilà! Temos um cliente DHCP funcionando contente e feliz. Eu reiniciei a máquina para tudo dar certo, mas provavelmente devem existir maneiras mais saudáveis de reiniciar a rede (talvez um ifdown seguido de ifup resolvesse). E agora eu posso finalmente ter acesso aos pacotes de instalação que precisava.
Notas de um Linux padawan =)
// Comments
2008-04-09 Gustavo Monteiro:
W,
Na realidade, o arquivo é o /etc/resolv.conf.
=)
Abcs.,
2008-04-13 Caloni:
É verdade! Lapso meu.
Corrigido.
[]s
# Aprendendo assembly com o depurador
2008-04-11 computer blog [up] [copy]Além de servir para corrigir alguns bugs escabrosos o nosso bom e fiel amigo depurador também possui uma utilidade inusitada: ensinar assembly! A pessoa interessada em aprender alguns conceitos básicos da arquitetura do 8086 pode se exercitar na frente de um depurador 16 ou 32 bits sem ter medo de ser feliz.
Vamos ver alguns exemplos?
Para quem está começando, recomendo usar um depurador simples, 16 bits e que existe em todo e qualquer Windows: o debug. Já usado para depurar a MBR aqui no bloque, poderá agora ser usado para ensinar alguns princípios da plataforma de uma maneira indolor. Basta iniciá-lo na linha de comando:
debug -
Os comandos mais úteis são o r (ver ou alterar registradores), o t/p (executar passo-a-passo), o d (exibir memória), o u (desmontar assembly) e o a (montar assembly). Ah, não se esquecendo do ? (ajuda).
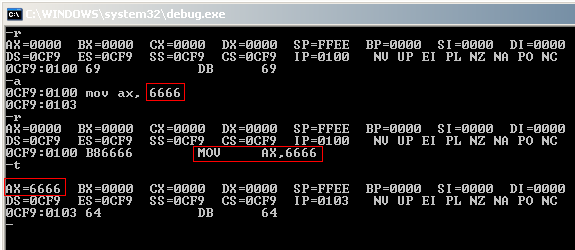
Outro ensinamento bem interessante diz respeito à pilha. Aprendemos sempre que a pilha cresce de cima pra baixo, ou seja, de endereços superiores para valores mais baixos. Também vimos que os registradores responsáveis por controlar a memória da pilha são o sp (stack pointer) e o ss (stack segment). Pois bem. Vamos fazer alguns testes para ver isso acontecer.
-r AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=0CF9 CS=0CF9 IP=0100 NV UP EI PL NZ NA PO NC 0CF9:0100 69 DB 69 -r ss SS 0CF9 :9000 -r sp SP FFEE :ffff -r AX=0000 BX=0000 CX=0000 DX=0000 SP=FFFF BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0100 NV UP EI PL NZ NA PO NC 0CF9:0100 69 DB 69 -a 0CF9:0100 mov ax, 1234 0CF9:0103 push ax 0CF9:0104 inc ax 0CF9:0105 push ax 0CF9:0106 inc ax 0CF9:0107 push ax 0CF9:0108 -u 0CF9:0100 B83412 MOV AX,1234 0CF9:0103 50 PUSH AX 0CF9:0104 40 INC AX 0CF9:0105 50 PUSH AX 0CF9:0106 40 INC AX 0CF9:0107 50 PUSH AX 0CF9:0108 6C DB 6C ... AX=1234 BX=0000 CX=0000 DX=0000 SP=FFFF BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0103 NV UP EI PL NZ NA PO NC 0CF9:0103 50 PUSH AX -t AX=1234 BX=0000 CX=0000 DX=0000 SP=FFFD BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0104 NV UP EI PL NZ NA PO NC 0CF9:0104 40 INC AX -t AX=1235 BX=0000 CX=0000 DX=0000 SP=FFFD BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0105 NV UP EI PL NZ NA PE NC 0CF9:0105 50 PUSH AX -t AX=1235 BX=0000 CX=0000 DX=0000 SP=FFFB BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0106 NV UP EI PL NZ NA PE NC 0CF9:0106 40 INC AX -t AX=1236 BX=0000 CX=0000 DX=0000 SP=FFFB BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0107 NV UP EI PL NZ NA PE NC 0CF9:0107 50 PUSH AX -t AX=1236 BX=0000 CX=0000 DX=0000 SP=FFF9 BP=0000 SI=0000 DI=0000 DS=0CF9 ES=0CF9 SS=9000 CS=0CF9 IP=0108 NV UP EI PL NZ NA PE NC 0CF9:0108 6C DB 6C -d 9000:fff9 9000:FFF0 36 12 35 12 34 12 00 6.5.4.. -
Como vemos, ao empilhar coisas na pilha, o valor do registrador sp diminui. E ao fazermos um dump do valor de sp conseguimos ver os valores empilhados anteriormente. Isso é muito útil na hora de depurarmos chamadas de funções. Por exemplo, no velho teste do Windbg x Bloco de notas:
windbg notepad 0:000> bp user32!MessageBoxW 0:000> g ModLoad: 5cfd0000 5cff6000 C:\WINDOWS\system32\ShimEng.dll ModLoad: 596f0000 598ba000 C:\WINDOWS\AppPatch\AcGenral.DLL ModLoad: 76b20000 76b4e000 C:\WINDOWS\system32\WINMM.dll ModLoad: 774c0000 775fd000 C:\WINDOWS\system32\ole32.dll ... ModLoad: 10000000 10030000 C:\Arquivos de programas\Babylon\Babylon-Pro\CAPTLIB.DLL ModLoad: 74c40000 74c6c000 C:\WINDOWS\system32\OLEACC.dll ModLoad: 76050000 760b5000 C:\WINDOWS\system32\MSVCP60.dll Breakpoint 0 hit eax=00000001 ebx=00000000 ecx=000a7884 edx=00000000 esi=000b2850 edi=0000000a eip=7e3b630a esp=0007f6d8 ebp=0007f6f4 iopl=0 nv up ei pl nz na po nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202 USER32!MessageBoxW: 7e3b630a 8bff mov edi,edi 0:000> dd esp L5 0007f6d8 01001fc4 00010226 000b2850 000a7ac2 ; ret handle message caption 0007f6e8 00000033 ; mb_ok 0:000> du 000b2850 000b2850 "O texto do arquivo Sem título fo" 000b2890 "i alterado...Deseja salvar as al" 000b28d0 "terações?" 0:000> ezu 000b2850 "Tem certeza que deseja salvar esse artigo de merda?" 0:000> g ModLoad: 75f50000 7604d000 C:\WINDOWS\system32\BROWSEUI.dll
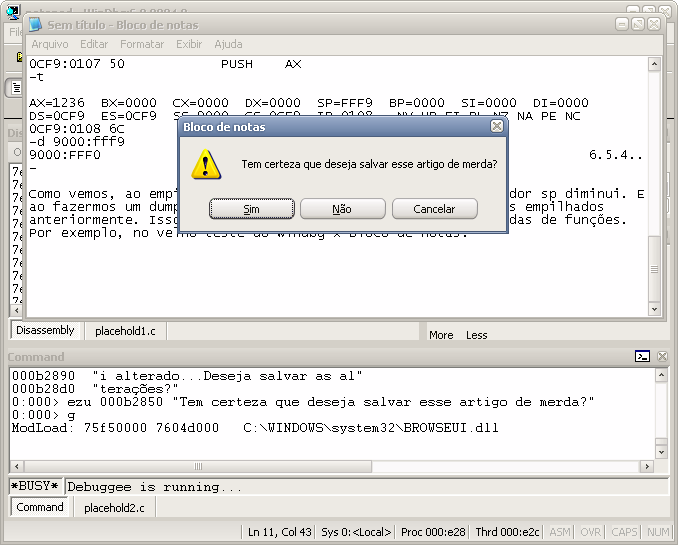
Aposto que você sabe em qual dos três botões eu cliquei =)
Depurar é um processo que exige dedicação (experiência) tanto ou mais do que o próprio desenvolvimento. Por isso, fazer um esforço para descobrir algum problema em algum software pode ser vantajoso no futuro, pois você terá mais capacidade de entender o que está acontecendo à sua volta.
// Comments
2008-04-11 Daniel Quadros:
Propaganda inevitável: aqui tem um livro gratuito sobre programação assembler 16 bits no PC: PC Assember Volume I
2008-04-13 Caloni:
Nada como saber um pouco de assembly para entender C a fundo =)
Outro uso interessante é em pesquisas de otimização: saber como o compilador otimiza trechos de código.
[]s
2008-04-11 skhaz:
Eu já usei esse método para tirar umas duvidas de asm, geralmente eu escrevo um código em C e depuro ele.
# Guia básico de controles de código distribuído
2008-04-15 computer blog [up] [copy]Houve um bom motivo para que, semana passada, eu estivesse caçando inúmeras versões de um projeto desenvolvido fora da empresa: falta de controle de código. Esse tipo de lapso pode consumir de horas a dias de tempo perdido, dependendo de em quantas cópias de máquinas virtuais ficou espalhado o código.
Já escrevi a respeito da importância de controlar e gerenciar o código-fonte para que a falta de um histórico exato das alterações não seja motivo de recorreções de problemas, binários no cliente sem contraparte para ajustes, além de uma série de dores de cabeça que costumam começar a ocorrer assim que nos damos conta que nosso software está uma bagunça que dói.
Na época, discursei brevemente sobre alguns exemplos de gerenciadores de fonte que utilizam modelo centralizado, e nos exemplos práticos usamos o famigerado Source Safe, velho amigo de quem já programa ou programou Windows por alguns anos. Além dele, temos os conhecidíssimos CVS e Subversion, ambos largamente utilizados no mundo todo.
No entanto, uma nova forma de controlar fontes está nascendo já há algum tempo, com relativo sucesso e crescentes esperanças: o modelo distribuído. Nesse tipo de gerenciamento, a liberdade aumenta exponencialmente, permitindo coisas que no modelo antigo seriam muito difíceis de serem implementadas. Não vou me delongar explicando a teoria por trás da idéia, sabendo que, além de existir um ótimo texto explicando as vantagens em cima do modelo centralizado disponível na web, o próprio sítio das implementações atuais explica a idéia de maneira muito convincente. E são elas:
"Mercurial" (ou hg). Sem dúvida o mais fácil de usar. Bem documentado e com comandos intuitivos para o usuário, vem ganhando mais adeptos a cada dia. Seu desempenho é comparável ao do Git, e seu sistema de arquivos é bem eficiente.
"Bazaar" (ou bzr). O irmão mais próximo do Mercurial, com comandos bem parecidos. Um costuma lembrar os comandos do outro, com pequenas diferenças. Seu desempenho não chega a ser comparável aos dois acima, mas sua robustez compensa, pois é o único, de acordo com testes e estudos, que suporta o controle total de operações de renomeação de arquivos e pastas. Recentemente seu projeto tem evoluído muito.
"Git" (ou git). Conhecido como o controlador de fontes do kernel do Linux. Escrita a versão inicial por Linux Torvalds em C e módulos de Perl pendurados, hoje em dia tem como principal desvantagem a falta de suporte nos ambientes Windows, impactando negativamente em projetos portáveis. Sua principal vantagem, no entanto, é a rapidez: é o controle de fonte mais rápido do oeste.
Nos sistemas centralizados o repositório de fontes fica em um lugar definido, de onde as pessoas pegam a última versão e sobem modificações, ou não, caso não tenham direito para isso. Nos sistemas distribuídos, o histórico e ramificações ficam todos locais. Como assim locais? Bom, locais do jeito que eu estou falando quer dizer: na própria pasta onde se está desenvolvendo.
É lógico que pode existir uma versão de ramificações no servidor, que no caso do controle distribuído é mais um membro da rede peer-to-peer de ramificações, já que cada colaborador possui seu próprio repositório local, capaz de trocar revisões entre colaboradores e subir as revisões para os servidores que interessam.
Além disso, o conceito de ramificações (branches) e consolidação de versões (merging) é muito mais presente do que em sistemas como o Subversion, onde o commit (ato de enviar as revisões de um código para o repositório central) ocorre de forma controlada. Da maneira distribuída, é comum criar um branch para cada problema ou feature sendo desenvolvida, e ir juntando tudo isso imediatamente após terminado, gerando um histórico bem mais detalhado e livre de gargalos com modificações temporárias.
Porém, a maior vantagem em termos de desenvolvimento acaba sendo a liberdade dos usuários, que podem trocar modificações de código entre si, sem existir a figura centralizadora do branch oficial. Ela pode existir, mas não é mais uma condição sine qua non para modificações no fonte.
Comecei a usar em meus projetos pessoais o Mercurial por ter ouvido falar dele primeiro. Achei a idéia fantástica, pois já estava à procura de um substituto para meu velho Source Safe, meio baleado das tantas inovações de controle de fonte que surgiram nos projetos de fonte aberto. Outro motivo para desistir do Source Safe foi o fato de ser uma solução comercial que custa dinheiro e não chega a ser absurdamente mais fácil de usar a ponto de valer a pena usá-lo.
O princípio de uso de uma ferramenta distribuída é muito simples: se você tiver um diretório de projeto já criado, basta, dentro dessa pasta, iniciar o repositório de fontes.
>hg init
Após isso, será criada uma pasta com o nome .hg. Dentro dela é armazenado todo o histórico dos fontes. Podemos inicialmente adicionar os arquivos do projeto existente e fazer o primeiro commit, que irá começar a controlar os arquivos adicionados dentro dessa pasta e subpastas:
>hg add adding Header.h adding Main.cpp adding Project.cpp adding Project.vcproj >hg commit -m "Primeira versao"
Se o programa não disse nada ao efetuar o commit, é porque está tudo certo. Agora podemos controlar as mudanças de nosso código usando o comando status. Para vermos o histórico usamos o comando log.
>hg log changeset: 0:e9246bcf2107 tag: tip user: Wanderley Caloni <wanderley.caloni@gmail.com> date: Tue Apr 15 09:05:27 2008 -0300 summary: Primeira versao >echo bla bla bla >> Main.cpp >hg status M Main.cpp >hg commit -m "Alterado algumas coisas" >hg log changeset: 1:829b081df653 tag: tip user: Wanderley Caloni <wanderley.caloni@gmail.com> date: Tue Apr 15 09:06:29 2008 -0300 summary: Alterado algumas coisas changeset: 0:e9246bcf2107 user: Wanderley Caloni <wanderley.caloni@gmail.com> date: Tue Apr 15 09:05:27 2008 -0300 summary: Primeira versao
Como vimos, ao alterar um arquivo controlado este é mostrado pelo comando status como alterado (o M na frente do Main.cpp). Também existem controles para cópia e exclusão de arquivos.
Esse é o básico que se precisa saber para usar o Mercurial. Simples, não? O resto também é simples: fazer branches e juntá-los é uma questão de costume, e está entre as boas práticas de uso. Eu recomendo fortemente a leitura do tutorial "Entendendo o Mercurial", disponível no sítio do projeto, até para entender o que existe por trás da idéia do controle descentralizado de fontes.
Como usuário de Windows, posso dizer que a versão funciona muito bem, e é possível fazer coisas como, por exemplo, usar o WinMerge para juntar branches ou comparar versões automaticamente, o que por si só já mata toda a necessidade que eu tinha do Source Safe.
Testei o Mercurial por cerca de três meses desde que o conheci. Esse fim-de-semana conheci mais a fundo o Bazaar, e pretendo começar a testá-lo também para ter uma visão dos dois mundos e optar por um deles. Ambos são projetos relativamente novos que prometem muito. De uma forma ou de outra, os programadores solitários agora possuem um sistema de controle de fontes sem frescura e que funciona para todos.
Update 2026-02-11: O Bazaar teve seu relase final 10 anos atrás. O Mercurial continua na ativa. O Git, como todos sabem, se tornou o controle de fonte dominante.
// Comments
2008-04-25 Walter Cruz:
Bacana cara, mercurial é uma excelente escolha!
2008-04-26 Caloni:
Olá, Walter
Valeu! Na verdade, agora estou testando também o Bazaar... é uma escolha difícil!
[]s
# Crash Dump Analysis: o livro
2008-04-17 books archive [up] [copy]Para quem acabou de terminar o Advanced Windows Debugging (como eu) e não consegue ler no computador os complicados artigos de Dmitry Vostokov (como eu) no seu blogue Crash Dump Analysis, "seus problemas acabaram-se": acabou de ser lançado o Memory Dump Analysis Volume 1 em hardware! Em modelos portáveis (paperback) e desktop (hardcover).
Se você perder um pouco de tempo lendo o índice online perceberá que boa parte do conteúdo (se não todo) está em seu sítio, disponível gratuitamente. Porém, não há nada como ter um livro organizado para ler no conforto do ônibus para o serviço (ou do metrô para casa). Ainda mais depois de ter aguçado os sentidos com o livro de Mario Hewardt e Daniel Pravat.
Selecionei alguns tópicos que acredito que por si só já valeria a pena a aquisição do livro:
- Crashes and Hangs Differentiated. Você sabe diferenciar quando uma aplicação trava e quando ela emperra?
- Minidump Analysis. Este item está no capítulo sobre análise profissional.
- Raw Stack Data Analysis. Nunca é tarde para aprender sobre a pilha; de novo.
- Symbols and Images
- X64 Interrupts
- Trap Commands (on x86 and x64)
- Bugchecks Depicted. Capítulo essencial, complemento necessário do AWD; boa parte do kernel mode ficou de fora do livro de Windows, espero que esse capítulo cubra essa carência.
- Manual Stack Trace Reconstruction. Isso vai ser legal =)
- WinDbg Tips and Tricks. Provavelmente um dos mais úteis capítulos; não há nada como economizar tempo de debugging com um truque esperto na manga.
- WinDbg Scripts. Com certeza esse capítulo ficaria mais rico com a ajuda do Farah; mesmo assim, deve estar recheado de código para otimizar tempo.
- Crash Dump Analysis Patterns. A coleção de todas as idiossincrasias encontradas por Dmitry em todos esses anos (meses?) de blogue.
- The Origin of Crash Dumps
- UML and Device Drivers. Este é um tópico que eu defendo, e que só uma pessoa como Dmitry consegue entender: usar UML para descrever o funcionamento do kernel mode. Além de tornar as coisas mais simples de enxergar, é uma ótima oportunidade de migração de "coder to developer" para o pessoal de baixo nível.
Enfim, estou coçando os dedos para comprar logo um exemplar. Já sei pelo menos que com certeza será a versão em brochura (spoiler de 2026-02-12: não foi, foi a capa dura mesmo; ainda tenho ele), pois não agüento mais fazer exercício muscular com o mais novo integrante da minha maleta.
// Comments
2008-04-17 Thiago:
Esse homi é truculento mesmo.
[]'s
Thiago
# Ode ao C++
2008-04-21 computer ccpp blog [up] [copy]Era uma vez em uma troca de emails:
Strauss: Lembra quando nós conversávamos sobre o assunto "Por que C++?", há muitas décadas atrás, e seu blogue era um dos primeiros no Brasil que não ficava relatando o que o autor comia no café da manhã, além de falar sobre programação? Pois é, eu estava reorganizando meus g-mails e reencontrei nossa conversa e, pior, seu artigo "derivado" dela, que irei republicar aqui pois, assim como antes, acredito em tudo que escrevi naquela época.
Cristiano: Olá! Sou programador em basic (Vbasic/Qbasic), fico indignado, com pessoas que sabem entender a linguagem C++, assembler... Como podem? Eu acho isto coisa de outro mundo! Será que eu tenho chances de aprender a linguagem?
Strauss: A resposta é simples: estudando. Eu tb comecei com QBasic e VB. Arrume um livro de C++ e estude. Treine bastante. E hoje em dia é mais fácil do que quando eu comecei, pq eu não tinha acesso à Internet. É simples assim... :-)
Caloni: Você pode ir tão longe quanto queira, mas pra isso a primeira coisa que vc tem que fazer é querer =).
Strauss: Acho que vou fazer um post sobre isso. "Por que C++" :-) Vc podia me ajudar...
Caloni: Escrevi um textículo sobre o assunto da escolha, mas não visando o mercado:
/** * @title Por que C++ * @author Wanderley Caloni Jr * @date 31.01.2005 */ É natural que um programador tenha preferência por uma linguagem. Geralmente por motivos pessoais que se refletem em suas características. Eu, por exemplo, tenho vários motivos para amar essa linguagem. Todas as vantagens da linguagem C estão embutidas em C++. E sem aquele papo erudito que deve-se programar em OO para ser C++. Por ser multiparadigma, ela também suporta o melhor da programação procedural e estruturada. C++ é unânime e reconhecida no mundo todo como de uso geral. Dificilmente você vai encontrar um algoritmo que não exista em C++. Pode parecer bobagem, mas coisas como operador de incremento e valor em todas expressões permitem que se faça muita coisa com poucas linhas. Isso a torna muito expressiva. Em outras palavras, você pode juntar várias expressões numa só, e esse conjunto será também uma expressão. Em C++ você é o culpado de qualquer coisa de bom e ruim que aconteça no seu programa. Você tem que seguir poucas regras e tem que ser responsável no que faz. C++ não te ajuda a seguir um bom modelo de programação com restrições embutidas. Isso a torna difícil para iniciantes, mas conforme aumenta a experiência, maior o prazer em programar, pelas responsabilidades embutidas. A possibilidade de compilar e rodar o seu código em vários ambientes é uma característica útil e agradável. No meu caso só é agradável, pois dificilmente faço código portável (apesar das boas noções que tenho sobre o assunto). Por fim, pode não ser importante em muitos casos, mas já é do instinto do programador o desejo pela eficiência. E nada como programar numa linguagem extremamente eficiente em tempo de execução para se sentir feliz de ver o código rodando. FIM []s
Strauss -- Legal. Vou colocar minha água mercadológica no feijão e colocar no site.
Update 2026-02-12 fiz umas pequenas alterações no texto original, mas não adicionei nada, como minha sugestão do passado de colocar, além de rapidez, a economia de recursos. É incrível o quanto progredimos no quesito hardware todos esses anos, e mesmo assim, existem linguagens e ambientes que parecem ter fome suficiente para consumir tudo e deixar um computador de última geração parecer um micro "meio lerdinho". Felizmente não preciso dar nome aos bois, pois todos sabem ou conhecem pelo menos uma linguagem (ou programador) com essa característica.
Também não quis generalizar. C e C++ não são as duas únicas opções quando se fala em bom desempenho. Existe também assembly e linguagens de script, que chegam inclusive a ser mais flexíveis e rápidas (além de mais produtivas).
Ainda acredito em tudo isso que C++ proporciona e irá continuar proporcionando por muto tempo. Muitos programas escritos em C/C++ são conhecidíssimos e usados nos quatro cantos do mundo, muitas vezes em mais de um sistema operacional. C++ está morto? Longe disso... talvez pareça assim em território nacional, mas esse é o motivo de meus votos de sucesso no início de nosso grupo C++.
// Comments
2008-04-23 Alberto Fabiano:
Quem foi este cara que disse que C++ está morto? Ele tem se orientado pelo TIOBE?
Talvez o marketing de massa, que sempre foi indireto ou quase nulo, sim !!!
Mas C++ não precisa de marketing publicitário, nossos mavens já fazem isto involuntariamente na expressão do prazer proporcionado pelo exercício da programação. OK, peguei pesado, mas não é isto? :-)
PS: Gostei da contextualização da mensagem de startup que você enviou ao grupo.
[]s
# CSI: Crashed Server Investigation?
2008-04-23 essays blog [up] [copy]O artigo de Jeff Dailey, The Digital DNA of Bugs Dump Analysis as Forensic Science (2026-02-12: não encontrei mais na web), em que ele compara a nossa atividade de "cientistas do debugging" com a atividade dos profissionais da análise forense, é exatamente o que eu penso sobre nossa profissão. Freqüentemente assisto à série CSI: Las Vegas e mais freqüentemente ainda uso os métodos científicos empregados pela equipe de Gil Grissom para resolver os problemas mais escabrosos que podem ocorrer em um sistema.
Jeff fez uma divertida comparação entre todas as etapas de uma análise forense com todas as etapas de nossa análise do bug. Aqui vai a tradução livre dessas etapas (em linguagem cinematográfica):
"São duas horas da manhã. A câmera focaliza um pager explodindo sobre um criado-mudo... só pode querer dizer uma coisa: algo de ruim aconteceu e pessoas estão à procura de ajuda. O detetive acorda e diz para sua mulher: "Desculpe, eles precisam de mim... Eu tenho que ir"."
Engraçado, eu fiz a mesma coisa, só porque alguém encontrou um servidor morto.
"O detetive aparece na cena do crime. Todos os policiais estão confusos, então eles apenas mantém a área isolada até que os experts cheguem. Seus anos de experiência e iluminação única irão permiti-lo ver coisas que os outros não vêem."
Umm... Isso só me parece apenas familiar. Eu tipicamente uso Live Meeting ou Easy Assist...
"Usando uma combinação de ferramentas especializadas e métodos aprendidos tanto na escola quanto os aprendidos com o tempo, a evidência é coletada na cena para que seja feita uma pesquisa adicional no escritório. Testemunhas são questionadas: "Por volta de que horas isso ocorreu?", "Você ouviu algum barulho estranho", e "você viu alguém ou alguma coisa não usual". Fotos são tiradas, objetos são arquivados, fibras e amostras de DNA são coletadas."
Ok, então o escopo do problema está determinado e todas as informações disponíveis foram obtidas. Ummm... eu faço isso todo dia.
"O prefeito chama o oficial para que diga ao chefe dos detetives que nós devemos resolver este caso. Isso não pode acontecer de novo. Nós devemos capturar o vilão!"
Sinta-se livre para substituir "prefeito" com qualquer figura de alto nível gerencial. Uau, isso ou é um cara mau e asqueiroso ou o driver de alguém está causando pool corruption causando um servidor crítico falhar!
"Nós agora cortamos onde o detetive está no laboratório, usando luminárias, procurando por evidências de DNA, refletindo sobre os fatos principais do caso, pesquisando crimes passados."
Eu não sei sobre você, mas eu simplesmente me refiro a isso como o processo de depuração.
"Finalmente um progresso: o DNA coletado na cena do crime identifica um suspeito que não deveria estar lá. Ao fazer uma pesquisa adicional, o suspeito tem um histórico desse tipo de atividade. O cara mau é capturado, os custos são arquivados e o caso está resolvido!"
Isso deve ser o mesmo que encontrar a causa principal, preencher um bug, e lançar uma correção.
Para finalizar, uma frase do artigo original que resume tudo:
"Ultimately that's what we do. We are all detectives looking for the digital DNA of bugs in the wild affecting our customers. We hunt them down using tools, expertise, and experience."
Dmitry Vostokov imaginou siglas mais imaginativas (2026-02-12 seu artigo não está mais entre nós) e fiéis a todos os que depuram problemas em software, independente deste rodar em servidores ou máquinas de café. Além, é claro, de uma ótima dica de livro sobre análise forense. O significado da sigla neste post foi uma de suas sugestões. Thanks, Dmitry!
# Seminário CCPP Portabilidade e Performance
2008-04-25 ccppbr blog [up] [copy]Reserve sua cadeira. Está marcado para o último dia do mês de maio o primeiro seminário de nosso grupo nacional de programadores e aficionados por C e C++. É bom ou não é?
O assunto gira em torno de duas preocupações constantes na vida de todo programador de linguagens de nível médio:
- Quanta velocidade eu preciso nesse código?
- Em quais plataformas eu conseguiria compilar e rodar meu projeto?
Para responder estas questões teremos uma bateria de palestras com temas que, dessa vez, focam o simples, puro e independente uso das linguagens C/C++:
Dicas e Truques de Portabilidade por Wanderley Caloni
O objetivo dessa palestra é focar nos problemas da vida real que enfrentamos no dia a dia para tornar um código portável ou mais maleável para um dia ser. Nesse caso existem vários assuntos a tratar, como: construções ambígüas não-padrão, isolamento de particularidades de cada sistema, identificação de problemas de portabilidade, organização do código-fonte portável, entre outros.
O nível dessa palestra será o intermediário, porque eu preciso que o público tenha o conhecimento prévio de programação C e C++. Quando você está aprendendo, uma dica ou outra sobre portabilidade pode ser interessante para não ser desvirtuado desde o início. Porém, para realmente começar a programar multiplataforma, existem desafios que devem ser transpostos por aqueles que já conseguem um nível de organização e desenvolvimento em C e C++ que não deixa dúvidas sobre a qualidade do código.
Programação Concorrente com C++ por Fábio Galuppo
Fábio Galuppo estréia na nossa rede de palestrantes, depois de seu inspirador e excitante relato das peripécias do SD West desse ano. Ele irá falar de um tema extremamente atual, que é o uso de programação paralela, em especial usando C++. Existe uma série de coisas para entender, como os modelos a ser seguidos, o uso consciente de threads, a programação com bom desempenho nos novos chips com mútiplos núcleos de processamento e por aí vai.
Apenas para ter uma idéia da importância em se ir em uma palestra como essa, imagine que 99,9% dos produtos da Google se baseiam nesse tipo de programação, envolvendo uma plantação de algumas centenas (milhares?) de máquinas trabalhando um banco de dados gigantesco no modo cooperativo para entregar a resposta mais rápida possível do outro lado. Sentiu o drama?
Programação Multiplataforma Usando STL e Boost por Rodrigo Strauss
Voltando para o tema portabilidade, Rodrigo Strauss volta a repetir sua performance sobre Boost, dessa vez abrangendo o conjunto completo de bibliotecas que compõem essa extensão mais-que-necessária da STL para programadores produtivos e multiplataforma. Todos sabem que um código que apenas usa STL e C++ puro não consegue ir muito longe na vida real, apesar de ser 100% multiplataforma. O que muitos não sabem (inclusive eu) é como é possível turbinar o desenvolvimento portável com o uso do Boost, que é uma solução portável bem interessante.
Por exemplo, a manipulação de arquivos e diretórios não é lá o forte da STL, concentrada no conceito de streams. Com o uso do Boost, podemos ter o melhor da STL, só que turbinada. Além disso, o novo padrão de threads ainda está longe de chegar ao mercado, e o Boost.Threads é uma solução viável atualmente.
Técnicas de Otimização de Código por Rodrigo Kumpera & André Tupinambá
Essa é a estréia de dois palestrantes de uma só vez! Como um bom complemento, voltamos ao tema de otimização, dessa vez em aspectos mais genéricos. Entre questões mais ou menos banais como otimização de laços e benchmarkers, mas que faz toda a diferença saber, teremos ainda tópicos bem avançados, como a relação de nosso código com o cachê do processador, e a tão-falada técnica de branch prediction, presente na maioria dos processadores atuais.
Além do aspecto genérico teremos uma pitada de matemática, como o uso de lookup tables e a otimização de algoritmos baseada em operações vetoriais. Ainda como um aspecto básico, mas importante, temos o uso eficiente da memória, muitas vezes entregue ao controle do sistema operacional, que nem sempre sabe bem o que o programa está fazendo.
# A solução mais simples é usar a fonte, Luke!
2008-04-29 computer blog [up] [copy]Seria bom se as coisas simples da vida fossem simples, não é mesmo? Ontem, sexta passada e quinta passada, no meio de outras tarefas "urgentes", tentava desesperadamente conseguir instalar o "Bazaar" na minha VM de desenvolvimento, um Fedora 8 todinho configurado.
Para azar da minha pessoa, o guia simples e rápido de instalação do Bazaar não funcionava para minha distribuição Linux. Na verdade, funciona. Porém, é instalada uma versão tão antiga (0.91!) que o formato do banco de dados já se tornou incompatível.
#yum info bzr ... Available Packages Name : bzr Arch : i386 Version : 0.91 ...
O pior, no entanto, foi tentar encontrar uma solução para o problema. Fiz mil e uma pesquisas com palavras-chave que nem imaginava que seria capaz de formular. E nada. A princípio minha idéia era apenas atualizar a lista de pacotes do repositório gerenciado pelo yum, o gerenciador de pacotes oficial do Fedora. Entre minhas buscas, encontrei os seguintes itens:
- Um FAQ do Fedora (que não conseguiu responder à minha pergunta).
- O sítio do projeto do yum, gerenciador de pacotes (cujo FAQ não conseguiu responder o mínimo).
- Uma lista enorme de sítios explicando como criar seu próprio repositório (sem comentários).
Enfim, a coisa não estava saindo do lugar. E o cronograma apertando até o dia final. Até que decidi usar o caminho mais rápido e pentelho: perguntar para quem entende do assunto. No caso meu amigo de trabalho Marcio Andrey Oliveira. A resposta foi simples e direta:
"Por que você não instala direto dos fontes?"
Uia! E não é que é mais simples, mesmo?
#wget https://launchpad.net/bzr/1.3/1.3.1/+download/bzr-1.3.1.tar.gz #tar -zxvf bzr-1.3.1.tar.gz /* ele teve que me explicar esse comando singelo */ #cd bzr-1.3.1 #cat INSTALL Installation ------------ When upgrading using setup.py, it is recommended that you first delete the bzrlib directory from the install target. To install bzr as a user, run python setup.py install --home ~ To install system-wide, run (as root) python setup.py install #python setup.py install
E foi isso! É a segunda vez que tento fazer algo simples no Linux e me dou mal. Com certeza os dias futuros serão melhores. Mas me bate aquela sensação que as coisas poderiam já estar em um nível mais fácil de se mexer. Opinião pessoal.
// Comments
2008-05-01 Alberto Fabiano:
E tão maravilhoso quanto o tar é o distutils que foi isto que você utilizou quando executou o "python setup.py install".
Este cara é uma das oitavas maravilhas do mundo pythológico, bom, na realidade acho que há mais do que 8 maravilhas pythônicas, mas este sem dúvidas é um deles.
Quais são as outras 7? :-)
Bem, aí está uma tarefa complicada, mas certamente uma delas é o PyS60! Não que eu esteja fugindo da raia em utilizar o Symbian C++, talvez seja trauma do Carbide que é uma IDE um tanto tosca, mas executar scripts Python num celular é algo muito dinâmico e divertido!
E é isto aí... para mim programação é muito mais que profissão, é diversão!
2008-04-30 Daniel Quadros:
Ah, as maravilhas do tar! Espero que tenham te explicado todas estas letrinhas, senão use "man tar" ou "info tar".
Não é a toa que o linux tem dificuldade em ser aceito pelos acostumados com o next/next/finish do windows. Como dizem, "use the source, luke".
2008-04-30 Caloni:
Pior que explicaram, Daniel. Usei uma fonte muito boa de conhecimento =)
Do pouco que conheço sobre Linux, e continuo aprendendo, existem comandos que fazem maravilhas em um piscar de olhos. E existem outros que fazem o básico, mas que precisam de 59 switches mais 412 parâmetros.
Haja Jedi Mind Trick! =)
[]s
2008-05-01 Caloni:
E o pior é que é uma diversão viciante!
Espero que esse projeto de Python em celulares dê muito certo; pois irá elevar em muito as potencialidade de software móvel.
[]s
[2008-03] [2008-05]