- História da Linguagem C: Parte 1
- Dogmas
- História do Windows - parte 3.0
- História do Windows - parte 3.51
- Antidebug: interpretação baseada em exceção (parte 2)
- GINA x Credential Provider
- História da Linguagem C: Parte 2
- Junctions
- Erro de compilação: funções muito novas na Win32 API
- Antidebug: ocupando a DebugPort
- ToDoList
- Hook de API no WinDbg
- Barata Elétrica e o hacker de antigamente
# História da Linguagem C: Parte 1
Caloni, 2007-08-01 <computer> <ccpp> [up] [copy]Confesso que adoro estudar sobre a história da linguagem C. Essa verdadeira adoração pela linguagem me fez estudar suas precursoras, como as linguagens BCPL e B. Posso dizer que todo esse conhecimento, no final das contas, valeu a pena. Hoje entendo muito melhor as decisões tomadas na criação da linguagem e, principalmente, a origem de algumas idiossincrasias e boas idéias que permaneceram até hoje.

Em 21 de julho de 1967 Martin Richards libera o manual da sua recém-criada linguagem BCPL. Na verdade, ela havia sido criada em 66 e implementada na primavera do ano seguinte no Instituto de Tecnologia de Massachusetts (vulgo MIT). Seus objetivos eram claros, como para todo criador de uma nova linguagem: melhorar uma linguagem anterior. Nesse caso, foi uma melhoria da Combined Programming Language (CPL), retirando, de acordo com Martin, "todas aquelas características da linguagem completa que tornavam a compilação difícil".
E BCPL era de fato bem simples. Não tinha tipos, era limpa e poderosa. Porém, mais importante que tudo isso, ela era portável. E essa portabilidade, aliada ao fato que escrever compiladores para ela era bem mais simples (alguns compiladores rodavam com apenas 16 KB), a tornaram especialmente popular na época.
Essa portabilidade era obtida com o uso de um artifício mais ou menos conhecido da comunidade C/C++ hoje em dia: a divisão entre código objeto e código final. O compilador era dividido em duas partes: a primeira parte era responsável por criar um código em estado intermediário feito para rodar em uma máquina virtual. Esse código era chamado de O-code (O de object). A segunda parte do compilador era responsável por traduzir esse O-code no código da máquina-alvo (onde iria ser rodado o programa). Essa sacada genial de 40 anos atrás permitiu que fosse mais simples fazer um compilador para uma nova plataforma e portar todo o código que já tinha sido escrito para uma plataforma anterior, driblando o grande problema daquela época: a incompatibilidade entre plataformas.
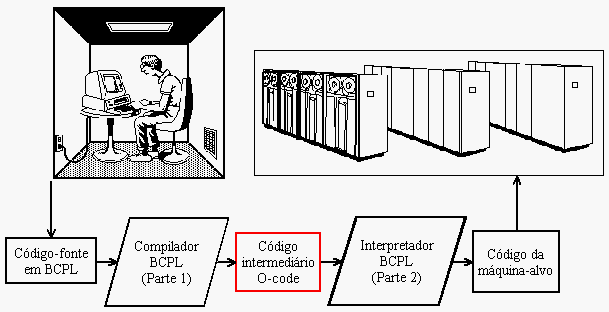
Perceba que é possível fazer toda a parte do compilador detrás do código-objeto uma única vez e, conforme a necessidade, criar novos interpretadores BCPL para máquinas diferentes.
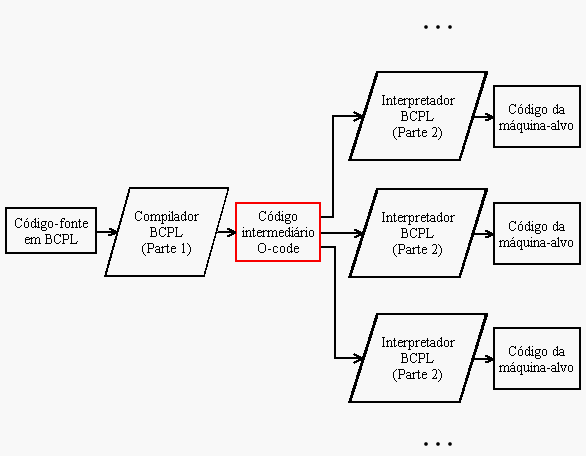
O código intermediário é gerado para uma máquina virtual. O interpretador, cerca de um quinto do compilador, tem a função de traduzir o código gerado para a máquina-alvo. Qualquer semelhança com Java ou .NET não é mera coincidência. Pois é. As boas idéias têm mais idade que seus criadores.
É inevitável também não fazer a associação entre essa forma de funcionamento do compilador BCPL e a divisão feita em C/C++ entre o pré-processador, o compilador e o ligador (linker, em inglês).
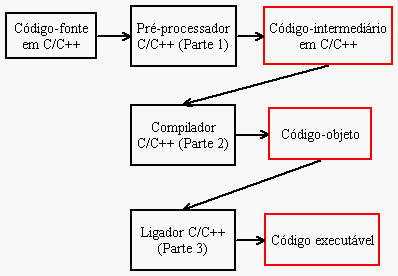
O uso do pré-processador na linguagem C facilitou a portabilidade por um bom tempo, quando não existiam typedefs. Diferente do BCPL, C já tinha tipagem, o que quer dizer que era necessário escolher o espaço de armazenamento que seria utilizado para as variáveis. Com o pré-processamento, essa escolha pode ser feita de maneira seletiva, documentada e generalizada.
#ifdef SBRUBLE_PLATFORM #define UINT unsigned char /* space limitation */ #else #define UINT unsigned int #endif
Como é natural, o código-fonte de uma aplicação tende a crescer em muitas linhas durante sua evolução, especialmente se estamos falando de sistemas operacionais. A compilação desse código vai tomar cada vez mais tempo no processo de desenvolvimento. Por isso, manter esse código-fonte em um mesmo arquivo eventualmente torna-se inviável, tornando a compilação de módulos separados uma solução pra lá de elegante. Compila-se apenas o módulo que foi modificado e liga-se esse módulo com módulos pré-compilados.
Para continuar lendo sobre a história da linguagem existe uma segunda parte.
# Dogmas
Caloni, 2007-08-01 quotes> self> now> [up] [copy]Os dogmas são prisões formadas por conceitos coletivos.
Tolle, Eckhart (O Poder do Agora, 1997)
# História do Windows - parte 3.0
Caloni, 2007-08-03 <computer> [up] [copy]Em 22 de maio de 1990 a versão 3.0 do Windows foi lançada. Foi melhorado o gerenciador de programas e o sistema de ícones, além de um novo gerenciador de arquivos e suporte a 16 cores. Entre as mudanças internas podemos citar a velocidade e a confiabilidade. Como a partir dessa versão apareceram muitos desenvolvedores que passaram a suportar a plataforma, o número de programas disponíveis aumentou, o que conseqüentemente fez com que as vendas alavancassem. Três milhões de cópias foram vendidas apenas no primeiro ano, e assim o Windows se tornou padrão nos computadores domésticos. Quando a versão 3.1 foi lançada, em 6 de abril de 1992, mais três milhões de cópias foram vendidos em apenas dois meses.
As fontes TrueType foram adicionadas, junto de novas capacidades multimídia. Outro grande avanço foi na área de comunicação entre aplicativos com a implementação da tecnologia OLE (Object Linking and Embedding), que permitiu documentos de diferentes fabricantes serem intercambiados.
Em novembro de 1993 foi lançada a primeira versão que integrou o Windows e a rede de trabalho, o Windows for Workgroups 3.1. O suporte a compartilhamento de arquivos e impressoras apareceu a partir daí. Duas aplicações novas também surgiram: Microsoft Mail, cliente de mail para uso em redes, e Schedule+, uma agenda de trabalho.
E, finalmente, agora já é hora de conversarmos sobre a figura ilustre que popularizou ainda mais o desenvolvimento para Windows.

Quem começou a programar para Windows naquela época com certeza deve ter ouvido falar do livro clássico de Charles Petzold, uma das poucas referências naquela época sem internet: Programming Windows 3.1. É um livro consideravelmente completo se considerarmos a época em que foi escrito. Vários exemplos estão disponíveis em suas páginas, mas para os que não viveram essa época (como eu) existe a versão eletrônica disponível para download. Você deve estar se perguntando se todo esse código-fonte serve para alguma coisa hoje em dia. Por incrível que pareça, serve sim. E para demonstrar o conceito de compatibilidade retroativa da Microsoft, iremos utilizar os mesmos exemplos deste livro, sem por nem tirar uma linha de código. Com o devido copyright e respeito merecidos ao autor, é claro =).
Programar interfaces naquela época não era bem o "clicar e arrastar" de hoje em dia. Eram necessários profundos conhecimentos sobre como o sistema operacional se relacionava com o seu programa e vice-versa. Hoje em dia é possível ainda programar como antigamente, já que toda a estrutura continua a mesma. Porém, é algo extremamente contraproducente de se fazer com as IDEs modernas que existem e suas barras de controles pré-fabricados e código automático. Faremos da forma mais rústica para entender como as coisas funcionam por baixo dos panos, o que por si só será extremamente produtivo para o nosso conhecimento.
Antes de ser criada uma janela, é necessário registrar uma classe de janela no sistema, cuja relação com uma janela é mais ou menos a mesma entre classe e objeto no paradigma de orientação a objetos. Você primeiro define uma classe para sua janela e posteriormente pode criar inúmeras janelas a partir da mesma classe.
WNDCLASS wndclass; //Dados sobre a classe de janela. wndclass.style = CS_HREDRAW | CS_VREDRAW; wndclass.lpfnWndProc = WndProc; // Função de janela (isso é importante!) ... wndclass.lpszClassName = szAppName; RegisterClass (&wndclass) ; // Registra a classe de janela.
Quando você define uma classe e a registra está dizendo para o sistema qual será sua função de janela, i. e., qual será a função responsável por receber as mensagens das janelas criadas.
wndclass.lpfnWndProc = WndProc ; // Função de janela.
...
long FAR PASCAL WndProc (HWND hwnd, WORD message, WORD wParam, LONG lParam)
{
switch( message ) // Manipulando as mensagens.
...
}
Uma mensagem é um evento que ocorre relativo à sua janela ou o que está acontecendo ao redor dela no mundo Windows. Por exemplo, as janelas recebem eventos a respeito dos cliques do usuário, redesenho da janela, etc. Quem envia essas mensagens é o próprio Windows, e ele espera uma resposta da sua função de janela. Agora a parte esquisita: quem envia essas mensagens para o Windows é o seu próprio aplicativo!
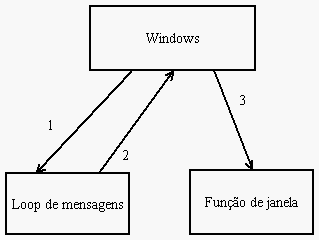
O aplicativo fica aguardando por eventos em um loop conhecido como loop de mensagens. A função do loop basicamente é chamar a função GetMessage e redirecionar as mensagens obtidas para as respectivas funções de janela.
while( GetMessage (&msg, NULL, 0, 0) )
{
TranslateMessage (&msg);
DispatchMessage (&msg); // Despacha a mensagem para a função de janela.
}
E aqui está o código completo:
/*--------------------------------------------------------
HELLOWIN.C -- Displays "Hello, Windows" in client area
(c) Charles Petzold, 1990
--------------------------------------------------------*/
#include <windows.h>
long FAR PASCAL WndProc (HWND, WORD, WORD, LONG) ;
int PASCAL WinMain (HANDLE hInstance, HANDLE hPrevInstance,
LPSTR lpszCmdParam, int nCmdShow)
{
static char szAppName[] = "HelloWin" ;
HWND hwnd ;
MSG msg ;
WNDCLASS wndclass ;
if (!hPrevInstance)
{
wndclass.style = CS_HREDRAW | CS_VREDRAW ;
wndclass.lpfnWndProc = WndProc ;
wndclass.cbClsExtra = 0 ;
wndclass.cbWndExtra = 0 ;
wndclass.hInstance = hInstance ;
wndclass.hIcon = LoadIcon (NULL, IDI_APPLICATION) ;
wndclass.hCursor = LoadCursor (NULL, IDC_ARROW) ;
wndclass.hbrBackground = GetStockObject (WHITE_BRUSH) ;
wndclass.lpszMenuName = NULL ;
wndclass.lpszClassName = szAppName ;
RegisterClass (&wndclass) ;
}
hwnd = CreateWindow (
szAppName, // window class name
"The Hello Program", // window caption
WS_OVERLAPPEDWINDOW, // window style
CW_USEDEFAULT, // initial x position
CW_USEDEFAULT, // initial y position
CW_USEDEFAULT, // initial x size
CW_USEDEFAULT, // initial y size
NULL, // parent window handle
NULL, // window menu handle
hInstance, // program instance handle
NULL) ; // creation parameters
ShowWindow (hwnd, nCmdShow) ;
UpdateWindow (hwnd) ;
while (GetMessage (&msg, NULL, 0, 0))
{
TranslateMessage (&msg) ;
DispatchMessage (&msg) ;
}
return msg.wParam ;
}
long FAR PASCAL WndProc (HWND hwnd, WORD message, WORD wParam, LONG lParam)
{
HDC hdc;
PAINTSTRUCT ps;
RECT rect;
switch (message)
{
case WM_PAINT:
hdc = BeginPaint (hwnd, &ps) ;
GetClientRect (hwnd, &rect) ;
DrawText (hdc, "Hello, Windows!", -1, &rect,
DT_SINGLELINE | DT_CENTER | DT_VCENTER) ;
EndPaint (hwnd, &ps) ;
return 0 ;
case WM_DESTROY:
PostQuitMessage (0) ;
return 0 ;
}
return DefWindowProc (hwnd, message, wParam, lParam) ;
}
Esse exemplo é bem velho, mas compila e funciona até hoje, depois de passados 17 anos. Pode não rodar, mas esta é outra história.
cl /c hellowin.c link hellowin.obj user32.lib gdi32.lib hellowin.exe
O Windows 3.x tinha uma particularidade nefasta: qualquer aplicativo poderia travar o sistema como um todo. Se lembrarmos que o Windows antigamente era multitarefa e não-preemptivo, podemos deduzir que enquanto é executada a função de janela de um aplicativo o sistema aguarda por esse aplicativo indefinidamente. Se o aplicativo trava, ele nunca retorna. Se ele nunca retorna, o sistema fica eternamente esperando pelo retorno da função de janela. Alguns travamentos conseguiam ser resolvidos por interrupção, mas a maioria não. No próximo capítulo da série veremos como os sistemas de 32 bits resolveram esse pequeno problema.
O que o resto do código do Petzold faz? Dê uma olhada na documentação do MSDN. Ela ainda está disponível, já que todos os aplicativos precisam utilizar essas funções, seja diretamente ou através de imensos frameworks de interface com o usuário. E existem pessoas que precisam suportar código-fonte legado.
Já que agora você sabe o que são funções de janela, mensagens e afins, por que não ver tudo isso funcionando? O Microsoft Visual Studio possui uma ferramenta muito útil para isso chamada Spy++ (spyxx.exe). Existem também aplicativos equivalentes (com fonte). Outra ferramenta muito útil, principalmente na hora de desenvolver janelas com controles comuns do Windows, é o Control Spy.
Para saber mais dê uma passada no sítio do Charles Petzold.
# História do Windows - parte 3.51
Caloni, 2007-08-07 <computer> [up] [copy]Bem-vindos. Esta é a série História do Windows. Nos anos 90, a relação IBM/Microsoft era muito próxima por causa do desenvolvimento do OS/2, o projeto de um novo sistema operacional. As empresas cooperavam entre si e tinham acesso uma ao código da outra. A Microsoft desejava avançar seu desenvolvimento no Windows, enquanto a IBM desejava que todo trabalho futuro fosse baseado em OS/2. Para resolver essa tensão as duas combinaram que a IBM iria desenvolver o OS/2 versão 2.0 para substituir o OS/2 versão 1.3 e o Windows v3.0, enquanto a Microsoft iria desenvolver um novo sistema operacional, o OS/2 versão 3.0 para depois suceder ao OS/2 anterior. Com tudo combinado entre as grandes corporações, é lógico que esse acordo foi por água abaixo.
A relação IBM/Microsoft foi terminada. A IBM continuou a desenvolver o OS/2 v2.0 enquanto a Microsoft mudou o nome de seu ainda não lançado OS/2 v3.0 para Windows NT. O Windows NT foi tão massivamente promovido que a maioria das pessoas nem se deu conta que ele era um OS/2 redesenhado. Ambas as empresas obtiveram os direitos de utilizarem as tecnologias do OS/2 e do Windows que foram desenvolvidas até a quebra do acordo.
A IBM lançou a versão 2.0 do OS/2 no início dos anos 90. O sistema foi uma grande melhora sobre o antigo OS/2 v1.3. Apresentava um novo sistema de janelas orientado a objetos (o Workplace Shell) para substituir o Presentation Manager, um novo sistema de arquivos (o HPFS) para substituir o sistema FAT utilizado pelo DOS e Windows e aproveitou todas as vantagens das capacidades 32 bits do processador 386 da Intel. Ele também rodava programas DOS e Windows 3.0, uma vez que a IBM tinha acesso e direito a essas duas tecnologias.
Para concorrer com a IBM a Microsoft lançou o Windows 3.1, com pequenas melhorias à sua versão anterior, a 3.0.
A Microsoft continuou a desenvolver o Windows NT. A empresa requeriu os serviços de Dave Cutler, um dos chefes arquitetos da VMS na Digital Equipment Corporation (hoje parte da Compaq) para desenvolver o NT dentro de um projeto de sistema operacional mais capaz. Cutler estava desenvolvendo um seguimento para o VMS na DEC chamado Mica, e quando a DEC desistiu do projeto ele acabou trazendo para a Microsoft sua especialidade nesse sistema e algum engenheiros do projeto com ele. A DEC acreditava que ele usara parte do código do Mica no Windows NT e acabou processando a Microsoft. A empresa de Gates teve que eventualmente pagar 150 milhões para a DEC, além de concordar em suportar o chip Alpha CPU da DEC na plataforma NT, e é por isso que existe uma pasta com essa arquitetura no CD de instalação do Windows NT.
Sendo um sistema operacional completamente novo o Windows NT sofreu com questões de compatibilidade com hardware e software geralmente usados na época. Ele era também concentrado em recursos, o que o deixava aceitável apenas para máquinas maiores e mais caras. Tanto que inicialmente foi dirigido a servidores de rede, workstations e máquinas de desenvolvimento de software. Por causa disso, a maioria dos usuários foi incapaz de migrar para a plataforma NT. E o Windows NT ainda estava projetado graficamente como o Windows 3.1, o que era inferior ao OS/2 Workplace Shell. Em resposta, a Microsoft começou a desenvolver um sucessor para o Windows 3.1, um projeto de codinome Chicago. Chicago tinha por objetivo apresentar uma nova GUI que competisse com o OS/2 Workplace Shell. Ele também foi projetado para ser de 32 bits e suportar execução multitarefa, como o OS/2 e o Windows NT. Só algumas partes do Chicago, entretanto, foram convertidas para 32 bits, e o resto permaneceu em 16. A Microsoft argumentou que a conversão total iria atrasar em muito o projeto, o que acabaria por encarecê-lo além do limite.
Para o Chicago foi desenvolvida uma nova API para substituir a de 16 bits do Windows anterior. Essa API foi chamada de Win32, e a outra renomeada para Win16. Houveram 3 ramificações: uma para o Chicago, outra para o NT e uma terceira chamada Win32s, que foi um subconjunto para o Windows 3.1 garantir a compatibilidade retroativa das versões. Também foi pensado num mínimo de compatibilidade entre o Chicago e o Windows NT, mesmo que os dois possuíssem duas arquiteturas radicalmente diferentes.
Em setembro de 1994 é lançado o Windows NT 3.5. A versão Workstation substituiu o Windows NT 3.1 e a versão Server o Windows NT 3.1 Advanced Server.

Como todo projeto de sucesso, a primeira coisa a ser feita é definir os objetivos principais. No caso do Windows NT não foi diferente. É importante para nós sabermos que objetivos eram esses e como eles foram mudando de acordo com o momento histórico de forma a analisarmos as conseqüências. Em outubro de 1988 os objetivos do novo sistema operacional eram os seguintes:
- Compatibilidade com OS/2;
- Segurança;
- Suporte a POSIX;
- Multiprocessamento;
- Rede integrada;
- Confiabilidade.
Como o Windows 3.0 fez um sucesso enorme, a compatibilidade nativa passou a ser do próprio Windows caseiro, sendo o OS/2 sendo implementado como um mero subsistema. Subsistema no Windows basicamente quer dizer ambiente virtual de execução de processos feitos para rodar em outro sistema operacional. Essa maneira de suportar processos de outros sistemas operacionais foi usado tanto para o OS/2 quanto para o Windows 16 bits, o MS-DOS e aplicativos POSIX, o padrão utilizado para arquiteturas derivadas do UNIX.
O tempo do projeto foi inicialmente estimado em pouco mais de dois anos. Ao final, quatro anos e meio se passaram até a chegada do primeiro release, que era grande e lento para as máquinas da época. Assim foi iniciado o projeto Daytona, que teve como novos objetivos tornar a nova versão do NT mais rápida e confiável. Foi lançada então a versão 3.51.
O Windows NT é um sistema operacional de 32 bits. Isso quer dizer, entre outras coisas, que ele suporta duas propriedades fundamentais dos sistemas operacionais modernos: modo protegido de execução e memória virtual. O modo protegido de execução permite a divisão entre a parte confiável do sistema operacional, que roda em kernel mode, e a parte não-confiável, que não possui acesso às instruções privilegiadas; a parte não-confiável chamamos de user mode. A memória virtual abstrai a memória física e permite isolamento de memória entre aplicativos, evitando que um programa invada a memória do outro.
Além disso, foi criada uma camada de abstração do hardware (HAL, Hardware Abstraction Layer) que livrou boa parte do código de ter sido escrito em assembly, fazendo assim que ele fosse facilmente portável.
# Antidebug: interpretação baseada em exceção (parte 2)
Caloni, 2007-08-09 <computer> <projects> <closed> [up] [copy]No primeiro artigo vimos como é possível "enganar" o depurador através de exceções e assim fazer o atacante perder um tempo considerável tentando se desvencilhar dos breakpoints de mentira. Porém, vimos também que essa é uma solução difícil de manter no código-fonte, além de possuir o ponto fraco de ser facilmente contornada se descoberta. Agora é a hora de tornar as coisas mais fáceis de manter e ao mesmo tempo garantir maior dificuldade mesmo que o atacante descubra o que está acontecendo debaixo do seu nariz.
O upgrade apresentado aqui continua utilizando o lançamento de exceções intrinsecamente, mas agora não depende mais da divisão do código em minifunções e chamá-las aos poucos. Em vez disso, temos apenas que pegar traços de código e colocá-los em torno de uma macro milagrosa que fará tudo o que quisermos. Isso, claro, depois de algumas marteladas que serão explicadas aqui.
void LongJmp(restorePoint)
{
BackToStart(restorePoint);
}
int Start()
{
if( RestorePoint() == Defined )
{
LongJmp(if);
}
else
{
CallFunc();
}
return 0;
}
A solução acima está apresentada em pseudo-código para tornar mais claro o conceito. Note que existe uma espécie de "retorno invisível", não baseado em retorno de pilha, envolvido. Para implementá-lo, contudo, podemos nos ajeitar com o velho e bom padrão C ANSI, com as rotinas setjmp e longjmp. Para entender a implementação dessa funções na plataforma 8086 precisamos ter primeiro uma visão básica da estrutura de chamada de funções baseada em pilha.
Registradores são variáveis reservadas do processador que podem ser utilizadas pelo código assembly da plataforma envolvida. Stack frame (estrutura da pilha) nada mais é que a hierarquia de chamadas das funções, o "quem chamou quem" em uma execução qualquer. Call e ret são instruções em assembly para chamar uma função (call) e sair de uma função (ret), respectivamente. Ambas alteram o stack frame.
Imagine que você tem uma função, CallFunc, e outra função, Func, e que uma chame a outra. Para analisarmos apenas a chamada de função, e apenas isso, vamos considerar que Func não recebe nenhum parâmetro e não retorna nenhum valor. O código em C fica, então, assim:
void Func()
{
return;
}
void CallFunc()
{
Func();
}
Simples, não? Por esse mesmo motivo o disassembly terá que ser igualmente simples. Em CallFunc ele deverá conter a chamada da função (call) e em Func o retorno da chamada (ret). Se você compilar o código acima e o assembly vier com mais coisas pode ser que que eventualmente apareça mais código embutido em versões Debug, ou se estiver muito diferente ou inexistente pode ser uma otimização do seu compilador.
Func: 00411F73 prev_instruction ; ESP = 0012FD38 (four bytes stacked up) 00411F74 ret ; *ESP = 00411FA3 (return address) CallFunc: 00411F9C prev_instruction 00411F9E call Func (411424h) ; ESP = 0012FD3C 00411FA3 next_instruction
A partir do assembly acima podemos concluir no mínimo duas coisas:
1. a pilha "cresce" para baixo, pois seu valor decrementou de quadro (0012FD3C para 0012FD38 são 4 byte a menos).
2. o valor de retorno da função chamada é o endereço da próxima instrução após a chamada (call), no caso 00411FA3.
Ora, da mesma forma que conseguimos acompanhar essa simples execução, o atacante também o fará. Por isso que no meio dessa chamada iremos colocar o lançamento de uma exceção e, no retorno, faremos não do modo convencional apresentado, mas por uma outra técnica que, ao invés de utilizar a instrução ret, seta "manualmente" o valor do registrador ESP (estado da pilha) e "pula" para a próxima instrução de CallFunc.
Func: 00411F60 throw_exception 00411F61 ... 00411F73 catch_exception 00411F74 mov ESP, 0012FD3C ; ESP = 0012FD3C, como em CallFunc 00411F75 jmp 00411FA3 ; "pula" para CallFunc::next_instruction
Toda essa esculhambada em assembly não precisa ser necessariamente feita em linguagem de baixo nível. Foi apenas uma maneira que encontrei pra ilustrar as diferenças entre retorno baseado em pilha e alteração no fluxo do código. Como já foi dito, para a sorte e o bem-estar de todos, essa mesma técnica pode ser implementada com funções C da biblioteca ANSI:
jmp_buf stack_state;
void Func()
{
longjmp(stack_state, 1);
}
void CallFunc()
{
// setting returns 0
// returning returns not 0
if( setjmp(stack_state) == 0 )
Func();
int x = 10;
}
Essa foi a técnica adicionada à solução do lançamento de exceções. E o código final ficou mais claro (além de rápido, por economizar o uso de uma thread para leitura dos comandos).
/** The only purpose of
this function is to
generate an exception. */
DWORD LongJmp(jmp_buf* env)
{
__try
{
__asm int 3
}
__except( EXCEPTION_EXECUTE_HANDLER )
{
longjmp(*env, 1);
}
return ERROR_SUCCESS;
}
/** And God said:
'int main!'
*/
int main()
{
DWORD ret = ERROR_SUCCESS;
while( cin )
{
string line;
cout << "Type something\n";
getline(cin, line);
jmp_buf env;
if( setjmp(env) == 0 )
{
LongJmp(&env);
}
else
{
cout << line << endl;
}
}
return (int) ret;
}
À primeira vista parece um desperdício o if estar diretamente no código (lembre-se que vamos utilizar a mesma estrutura condicional em várias e várias partes do código. Para tornar mais claro seu uso, resumir a chamada protegida e permitir que a proteção seja desabilitada em debug, vamos criar uma macro:
/** Use this macro instead LongJmp
*/
#define ANTIDEBUG(code)
{
jmp_buf env;
if( setjmp(env) == 0 )
{
LongJmp(&env);
}
else
{
code;
}
}
/** And God said: 'int main!'
*/
int main()
{
DWORD ret = ERROR_SUCCESS;
while( cin )
{
string line;
cout << "Type something\n";
getline(cin, line);
ANTIDEBUG(( cout << line << endl ));
}
return (int) ret;
}
Veja que como agora permitimos a seleção do anti-debug por chamada, fica mais fácil escolher quais os pontos a serem protegidos e quais não devem/podem por conta de perfomance ou outro detalhe obscuro que sempre existe na vida de um programador C++.
# GINA x Credential Provider
Caloni, 2007-08-13 <computer> [up] [copy]Não fui convidado a participar do tema, mas como já faz algum tempo que o rascunho deste artigo está no molho, e aproveitando que meu amigo Ferdinando resolveu escrever sobre nossa amiga em comum, darei continuidade à minha empolgação sobre o tagging e largarei aqui este pequeno adendo.
Com a chegada do Windows Vista, uma velha conhecida minha e dos meus colegas deixou de fazer parte do sistema de autenticação do sistema operacional: a velha GINA, Graphical Identification aNd Authentication.
Basicamente se trata de uma DLL que é chamada pelo WinLogon, o componente responsável pelo famoso Secure Attention Sequence (SAS), mais conhecido por Ctrl + Alt + Del. Ele efetua o logon do usuário, mas quem mostra as telas de autenticação, troca de senha, bloqueio da estação é a GINA. Mexi com várias GINAs há um tempo atrás: GINAs invisíveis, GINAs que autenticam smart cards, GINAs que autenticam pela impressão digital, e por aí vai a valsa.
O Windows já vem com uma GINA padrão, a MsGina.dll, que autentica o usuário baseada em usuário e senha e/ou smart card. Teoricamente o intuito original de uma GINA fornecida por terceiros era permitir outros meios de autenticação. Para isso o fornecedor deveria trocar todas as telas de autenticação pela equivalente de acordo com o novo tipo de autenticação (por exemplo, um campo com uma impressão digital para permitir o uso de biometria em vez de senha). Porém, um outro uso pode ser controlar o login dos usuários baseado em outras regras além das que o Windows já fornece.
Apesar de útil, o sistema baseado em GINAs tinha um pequeno problema: permitia somente a troca exclusiva, ou seja, só uma GINA pode ser ativada. Se não for a da Microsoft, que seja a do fornecedor, e apenas a de um fornecedor. Isso começa a ficar limitado diante das novas e conflitantes maneiras que um usuário possui hoje em dia de fazer logon: nome e senha, íris dos olhos, impressão digital, formato do nariz e assim por diante. Todas essas autenticações deveriam estar disponíveis ao mesmo tempo para que o usuário escolha qual deles lhe convém.
Foi por isso que surgiu seu substituto natural no Windows Vista: o Credential Provider.
O sistema de Credential Provider permite que inúmeras DLLs sejam registradas no sistema para receberem eventos de logon, seja para criar uma nova sessão (tela de boas vindas) ou apenas para se autenticar já em uma sessão iniciada, como, por exemplo, nos casos em que o Controle da Conta do Usuário (UAC: User Account Control) entra em ação.
O sistema de coleta foi simplificado e modernizado: agora a interface não se baseia em funções exportadas, como a GINA, mas em interfaces COM disponíveis. O desenvolvedor também consegue escolher os cenários em que ele pretende entrar em ação:
- Efetuar logon.
- Desbloquear estação.
- Mudar a senha.
- Efetuar conexão de rede (antes do logon).
Baseado no número de CPs registrados no sistema, o LogonUI (processo responsável por exibir a tela de boas vindas) irá exibir as respectivas credenciais para cada um dos CPs envolvidos no logon.
Com o exemplo de GINA stub do Ferdinando desenvolvi uma versão um pouco mais perigosa, da época de laboratório da faculdade. Se trata igualmente de uma GINA que se aproveita da implementação da GINA original, porém na hora de autenticar um usuário ela captura os dados do logon (usuário e senha) e grava em uma parte do registro acessível apenas pelo sistema (lembre-se que a GINA, por fazer parte do WinLogon, roda na conta de sistema).
É claro que para utilizar essa GINA, você deve possuir direitos de administração, ou conhecer alguma brecha de segurança. Eu optei pela segunda opção, já que não tinha a primeira. Podemos dizer apenas que o artigo sobre falhas de segurança relacionadas a usuários avançados do Russinovich pôde resolver meu problema.
# História da Linguagem C: Parte 2
Caloni, 2007-08-15 <computer> <ccpp> [up] [copy]No princípio... não, não, não. Antes do princípio, quando C era considerada a terceira letra do alfabeto e o que tínhamos eram linguagens experimentais para todos os lados, dois famigerados senhores dos Laboratórios Bell, K. Thompson e D. Ritchie, criaram uma linguagem chamada B. E B era bom.

O bom de B era sua rica expressividade e sua simples gramática. Tão simples que o manual da linguagem consistia de apenas 30 páginas. Isso é menos do que as 32 palavras reservadas de C. As instruções eram definidas em termos de ifs e gotos e as variáveis eram definidas em termos de um padrão de bits de tamanho fixo, geralmente a word, ou palavra, da plataforma, que utilizada em expressões definiam seu tipo. Esse padrão de bits era chamado rvalue. Imagine a linguagem C de hoje em dia com apenas um tipo: int.
Como esse padrão de bits nunca muda de tamanho, todas as rotinas da biblioteca recebiam e retornavam sempre valores do mesmo tamanho na memória. Isso na linguagem C quer dizer que o char da época ocupava tanto quanto o int. Existia inclusive uma função que retornava o caractere de uma string na posição especificada:
c = char(string, i); /* the i-th character of the string is returned */
Sim! Char era uma função, um conversor de "tipos". No entanto a própria variável que armazenava um char tinha o tamanho de qualquer objeto da linguagem. Esse é o motivo pelo qual, tradicionalmente, as seguintes funções recebem e retornam ints em C e C++:
int getchar( void ); // read a character from stdin int putchar( int c ); // writes a character to stdout void *memset( void *dest, int c, size_t count ); // sets buffers to a specified character
Segue o exemplo de uma função na linguagem B, hoje muito famosa:
/* The following function is a general formatting, printing, and
conversion subroutine. The first argument is a format string.
Character sequences of the form `%x' are interpreted and cause
conversion of type 'x' of the next argument, other character
sequences are printed verbatim. Thus
printf("delta is %d*n", delta);
will convert the variable delta to decimal (%d) and print the
string with the converted form of delta in place of %d. The
conversions %d-decimal, %o-octal, *s-string and %c-character
are allowed.
This program calls upon the function `printn'. (see section
9.1) */
printf(fmt, x1,x2,x3,x4,x5,x6,x7,x8,x9) {
extrn printn, char, putchar;
auto adx, x, c, i, j;
i= 0; /* fmt index */
adx = &x1; /* argument pointer */
loop :
while((c=char(fmt,i++) ) != `%') {
if(c == `*e')
return;
putchar(c);
}
x = *adx++;
switch c = char(fmt,i++) {
case `d': /* decimal */
case `o': /* octal */
if(x < O) {
x = -x ;
putchar('-');
}
printn(x, c=='o'?8:1O);
goto loop;
case 'c' : /* char */
putchar(x);
goto loop;
case 's': /* string */
while(c=char(x, j++)) != '*e')
putchar(c);
goto loop;
}
putchar('%') ;
i--;
adx--;
goto loop;
}
Como podemos ver, vários elementos (se não todos) da linguagem C já estão presentes na B.
# Junctions
Caloni, 2007-08-17 <computer> [up] [copy]Semana passada baixei uma nova imagem para minha máquina de desenvolvimento. Esse esquema do pessoal da engenharia instalar as coisas para você facilita muito as coisas, mas existe o risco de algo ser instalado no lugar errado, que foram os casos do DDK e do SDK do Windows. Aqui no desenvolvimento, para efeito de padronização, utilizamos a seguinte estrutura de diretórios para esses dois aplicativos:
Library |- ddk |- legacy |- mssdk
Porém, por algum motivo desconhecido os instaladores da Microsoft não seguem o nosso padrão: o SDK é instalado em %programfiles%, Microsoft Platform SDK e o DDK em C:, WINDDK, 3790.1830. Para corrigir este pequeno ato relapso eu até poderia reinstalar ambos os aplicativos no local correto, gastanto algumas horas do dia, mas existe uma outra solução mais rápida e simpática chamada de junction.
Um junction é um link simbólico (symbolic link) de diretório. É praticamente um atalho, com a diferença que ele se comporta exatamente como se fosse o próprio objeto para o qual aponta: qualquer arquivo criado ou apagado usando o junction cria ou apaga um arquivo real no diretório real para o qual ele aponta. Essa característica pode ser tão útil quanto perigosa, por isso devem-se utilizar junctions com cuidado.
Para criar um junction pode-se usar uma ferramenta disponível no Windows Resource Kit chamada linkd.exe. Porém, para evitar de ter que baixar todo o pacote para usar um único arquivo, existe uma outra ferramenta desenvolvida à parte por Mark Russinovich chamada... junction. O comando para criar junctions é bem fácil e direto:
junction c:\library\mssdk "path where is microsoft platform sdk" junction c:\library\ddk "path where is winddk"
E é isso aí. A partir de agora tanto as pastas originais quanto os junctions criados para elas respondem como se fossem a mesma coisa, porém com paths diferentes.
"Neo, sooner or later, you're going to realize, just as I did, that there's a different between knowing the path... and walking the path..."
No Windows Vista os junctions também funcionam para arquivos e possuem seu próprio aplicativo nativo, o mklink.exe. Porém, ele chama os links para diretórios de junctions (em português, junções) e os links para arquivos de links mesmo. Você pode notar uma pequena gamb.. adaptação técnica ao mudarem o nome da pasta "Documents and Settings" para "Users" (ou "Usuários", na versão em português). Esse link é extremamente necessário para a compatibilidade daqueles aplicativos feitos às pressas que não se importam em perguntar para o sistema onde está a pasta de documentos do usuário, fixando o path como se ele fosse estar sempre lá.
# Erro de compilação: funções muito novas na Win32 API
Caloni, 2007-08-21 <computer> [up] [copy]Quando fala-se em depuração geralmente o pensamento que vem é de um código que já foi compilado e está rodando em alguma outra máquina e gerando problemas não detectados nos testes de desenvolvedor. Mas nem sempre é assim. Depuração pode envolver problemas durante a própria compilação. Afinal de contas, se não está compilando, ou foi compilado errado, é porque já existem problemas antes mesmo da execução começar.
O fonte abaixo, por exemplo, envolve um detalhe que costuma atormentar alguns programadores, ou por falta de observação ou documentação (ou ambos).
#include <stdio.h>
#include <windows.h>
void main(void)
{
typedef enum _COMPUTER_NAME_FORMAT
{
ComputerNameNetBIOS,
ComputerNameDnsHostname,
ComputerNameDnsDomain,
ComputerNameDnsFullyQualified,
ComputerNamePhysicalNetBIOS,
ComputerNamePhysicalDnsHostname,
ComputerNamePhysicalDnsDomain,
ComputerNamePhysicalDnsFullyQualified,
ComputerNameMax
} COMPUTER_NAME_FORMAT;
COMPUTER_NAME_FORMAT CF = ComputerNameDnsDomain;
char szDomainName[MAX_COMPUTERNAME_LENGTH];
DWORD dwSize = sizeof(szDomainName);
//GetComputerName(szDomainName, &dwSize);
GetComputerNameEx(CF, szDomainName, &dwSize);
}
Tirando o fato que o retorno void não é mais um protótipo padrão da função main e que a definição da enumeração COMPUTER_NAME_FORMAT dentro da função main é no mínimo suspeita, podemos testar a compilação e verificar que existe exatamente um erro grave neste fonte:
cl getcomputername.cpp getcomputername.cpp(26) : error C3861: 'GetComputerNameEx': identifier not found
A função GetComputerNameEx parece não ter sido definida, apesar de estarmos incluindo o header windows.h, que é o pedido pela documentação do MSDN.
Esse tipo de problema acontece na maioria das vezes por dois motivos:
1. o header responsável não foi incluído (não é o caso, como vimos),
2. é necessário especificar a versão mínima do sistema operacional.
De fato, se criarmos coragem e abrirmos o arquivo winbase.h, que é onde a função é definida de fato, e procurarmos pela função GetComputerNameEx encontramos a seguinte condição:
#if (_WIN32_WINNT >= 0x0500)
typedef enum _COMPUTER_NAME_FORMAT {
ComputerNameNetBIOS,
ComputerNameDnsHostname,
ComputerNameDnsDomain,
ComputerNameDnsFullyQualified,
ComputerNamePhysicalNetBIOS,
ComputerNamePhysicalDnsHostname,
ComputerNamePhysicalDnsDomain,
ComputerNamePhysicalDnsFullyQualified,
ComputerNameMax
} COMPUTER_NAME_FORMAT ;
WINBASEAPI
BOOL
WINAPI
GetComputerNameExA (
__in COMPUTER_NAME_FORMAT NameType,
__out_ecount_part_opt(*nSize, *nSize + 1) LPSTR lpBuffer,
__inout LPDWORD nSize
);
WINBASEAPI
BOOL
WINAPI
GetComputerNameExW (
__in COMPUTER_NAME_FORMAT NameType,
__out_ecount_part_opt(*nSize, *nSize + 1) LPWSTR lpBuffer,
__inout LPDWORD nSize
);
#ifdef UNICODE
#define GetComputerNameEx GetComputerNameExW
#else
#define GetComputerNameEx GetComputerNameExA
#endif // !UNICODE
//...
#endif // _WIN32_WINNT
Ou seja, para que essa função seja visível a quem inclui o windows.h, é necessário antes definir que a versão mínima do Windows será a 0x0500, ou seja, Windows 2000 (vulgo Windows 5.0). Aliás, é como aparece na documentação. Um pouco de observação nesse caso seria o suficiente para resolver o caso, já que tanto abrindo o header quanto olhando no exemplo do MSDN nos levaria a crer que é necessário definir essa macro:
#define _WIN32_WINNT 0x0500
#include <windows.h>
#include <stdio.h>
#include <tchar.h>
void _tmain(void)
{
TCHAR buffer[256] = TEXT("");
TCHAR szDescription[8][32] = {TEXT("NetBIOS"),
TEXT("DNS hostname"),
TEXT("DNS domain"),
TEXT("DNS fully-qualified"),
TEXT("Physical NetBIOS"),
TEXT("Physical DNS hostname"),
TEXT("Physical DNS domain"),
TEXT("Physical DNS fully-qualified")};
int cnf = 0;
DWORD dwSize = sizeof(buffer);
for( cnf = 0; cnf < ComputerNameMax; cnf++ )
{
if (!GetComputerNameEx( (COMPUTER_NAME_FORMAT)cnf, buffer, &dwSize) )
{
_tprintf(TEXT("GetComputerNameEx failed (%d)\n"),
GetLastError());
return;
}
else _tprintf(TEXT("%s: %s\n"), szDescription[cnf], buffer);
dwSize = sizeof(buffer);
ZeroMemory(buffer, dwSize);
}
}
Outra observação que poderia ter ajudado na hora de codificar seria dar uma olhada no que os caras escrevem na seção de advertências (remarks) da documentação:
To compile an application that uses this function, define the _WIN32_WINNT macro as 0x0500 or later. For more information, see Using the Windows Headers.
Podemos também notar pela definição do COMPUTER_NAME_FORMAT dentro do main que o código estava no meio do caminho de cometer um sacrilégio: declarar funções e estruturas que já estão definidas nos headers da API. Portanto, se você já encontrou algum código parecido com esse, é hora de colocar em prática algumas teorias de refactoring.
# Antidebug: ocupando a DebugPort
Caloni, 2007-08-23 <computer> <projects> <closed> [up] [copy]Quando um depurador inicia um processo para ser depurado ou, o caso abordado por este artigo, se conecta em um processo já iniciado, as comunicações entre esses dois processos é feita através de um recurso interno do Windows chamado de LPC (Local Procedure Call). O sistema cria uma "porta mágica" de comunicação específica para a depuração e os eventos trafegam por meio dela.
Entre esses eventos podemos citar os seguintes:
- Breakpoints disparados.
- Exceções lançadas.
- Criação/saída de threads.
- Load/unload de DLLs.
- Saída do processo.
No caso de se conectar em um processo já existente, é chamada a função da API DebugActiveProcess. A partir dessa chamada, se retornado sucesso, o processo que depura agora está liberado para ficar chamando continuamente a função API WaitForDebugEvent. E o código se resume a isto:
void DebugLoop()
{
bool exitLoop = false;
while( ! exitLoop )
{
DEBUG_EVENT debugEvt;
WaitForDebugEvent(&debugEvt,
INFINITE);
switch( debugEvt.dwDebugEventCode )
{
// This one...
// That one...
// Process is going out.
case EXIT_PROCESS_DEBUG_EVENT:
exitLoop = true;
break;
}
// Unfreeze the thread who sent the debug event.
// Otherwise, it stays frozen forever!
ContinueDebugEvent(debugEvt.dwProcessId,
debugEvt.dwThreadId,
DBG_EXCEPTION_NOT_HANDLED);
}
}
O detalhe interessante desse processo de comunicação depurador/depurado é que um processo só pode ser depurado por apenas UM depurador. Ou seja, enquanto houver um processo depurando outro, os outros processos só ficam na vontade.
Partindo desse princípio, podemos imaginar uma proteção baseada nessa exclusividade, criando um processo protetor que conecta no processo protegido e o "depura". Fiz um código de exemplo que faz justamente isso: ele atacha em um processo para depurá-lo (basta passar o PID como parâmetro) e não deixa mais outro depurador ocupar a debug port. Os passos para testá-lo são:
1. Compilar o código.
2. Executar o notepad (ou qualquer outra vítima).
3. Obter seu PID (Process ID).
4. Executar o protetor passando o PID como parâmetro.
5. Tentar "atachar" no processo através do Visual C++.
Após o processo de attach, a porta de debug é ocupada, e a comunicação entre depurador e depurado é feita através do LPC. Abaixo uma pequena ilustração de como as coisas ocorrem:
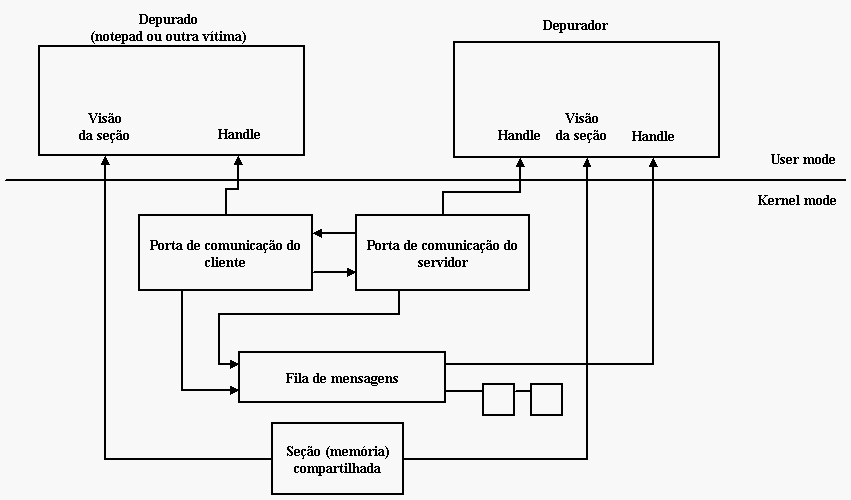
Basicamente o processo fica recebendo eventos de debug (através da fila de mensagens LPC) continuamente até o evento final, o de final de processo. Note que se alguém tentar derrubar o processo que depura o processo depurado cai junto.
O ponto forte desse tipo de proteção é que não afeta a compreensão e a legibilidade do código. De fato o próprio código que "protege" está em outro processo. O fraco, eu diria, é a sua alta visibilidade. Todo mundo que tentar atacar verá dois processos serem criados; e isso já faz pensar...
Por isso é necessário pensar bem na implementação. Particularmente uma coisa a ser bem arquitetada é a união entre depurador e depurado. Quanto melhor essas duas peças forem encaixadas, tão mais difícil será para o atacante separá-las. Uma idéia adicional é utilizar a mesma técnica na direção oposta, ou seja, o processo depurado se atachar no depurador.
Dessa vez não vou afirmar que, uma vez entendido o problema, a solução torna-se óbvia. Isso porque ainda não pensei o suficiente para achar uma solução óbvia. Idéias?
# ToDoList
Caloni, 2007-08-27 [up] [copy]Vou aproveitar que o recente blogue do meu amigo resolveu falar um pouco sobre administração de tempo e citar a ferramenta que venho utilizando há quase um ano para tentar organizar minhas idéias, minhas tarefas e minha vida. Assim como o Kabloc, eu estava em sérias dificuldades para tentar fazer e organizar todas as coisas que eu tinha em mente. Ainda continuo com dificuldades para fazer, mas o mais importante é que agora eu tenho um roadmap de para onde eu quero ir.
Eu sempre ouvi falar nesse programa desde que freqüento o The Code Project, um sítio onde programadores publicam seus minicódigos para serem aproveitados (e avaliados) por toda a comunidade. Possuo algumas pequenas contribuições por lá.
O fato é que por preguiça de testar e pelo seu screenshot inicial, me pareceu um programa demasiado complexo e pesado. Por isso passei vários anos sem sequer baixá-lo.
No entanto, houve um momento em minha vida em que eu precisava definitivamente reunir e organizar todas as minhas idéias e atividades para conseguir concluí-las, tanto no trabalho quanto na vida pessoal. Houve então uma pequena pesquisa de minha parte de programas que fizessem o que eu precisava. Foi aí que eu baixei e testei o ToDoList, um programa pequeno, portátil (posso levar em meu PenDrive) e muito flexível. Eis abaixo o screenshot original do artigo do Code Project:
Bem, me parecia mais do que eu precisava. No entanto ele é flexível, e suas colunas podem ser configuradas da maneira que lhe aprouver. Abaixo um screenshot de como utilizo o ToDoList:
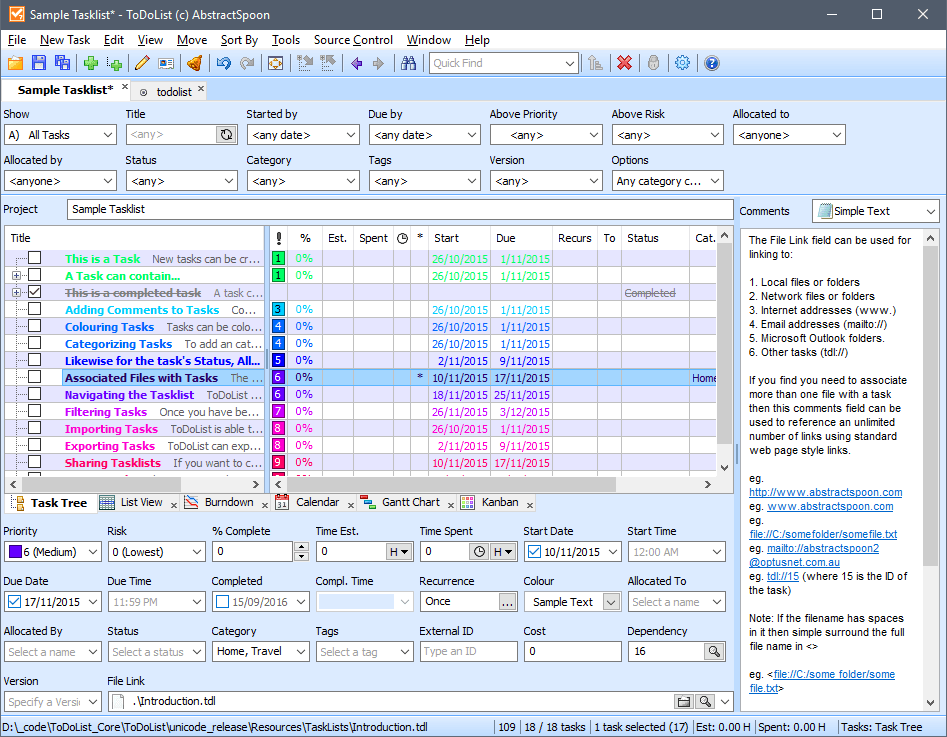
Entre algumas coisas legais que gosto nesse programa que me fizeram ficar com ele, consigo me lembrar da seguinte lista:
- Posso levar onde quiser e salvar minhas configurações em um arquivo ini.
- Ele fica na área de notificação e posso ativá-lo com um atalho global.
- Ele conta o tempo de uma tarefa se você quiser.
- Ele exporta as listas em formatos como Excel, HTML e texto puro.
- Ele é pequeno e não precisa de instalação.
- O código-fonte é disponível e está sempre sendo atualizado.
- Posso salvar minhas listas em XML (padrão) ou encriptado.
- Pode ser estendido por meio de plugins.
Bem, ele sozinho não resolveu meus problemas. Assim como o Kabloc disse, é você, e unicamente você, o responsável por organizar a sua agenda. E eu tive que passar muito tempo junto da minha para conseguir encontrar a maneira ideal para eu trabalhar. Cada um tem a sua.
Há um tempo atrás não acreditava muito em idéias, mas a partir de um dado momento um outro amigo meu conseguiu me convencer que idéias são os verdadeiros motores do mundo, e um mundo sem idéias seria um mundo de fazedores de coisas sem cabeça. Não adianta ser muito bom no que se faz se não se pensa no que se faz. Essa é um boa razão para explicar por que boas idéias permanecem para sempre, mesmo que seus criadores já tenham morrido há muito tempo.
Por esse motivo que uso o ToDoList para catalogar e listar todas as idéias que tenho sobre o que pretendo fazer. Como você deve adivinhar, a lista nunca acaba e só tende a crescer. Mas tudo bem, o objetivo não é acabar, mas sim não perder a idéia que se teve, pois ela aos poucos pode ser extendida e aprimorada no próprio ToDoList, até chegar a hora de implementar. Quando for a hora de botar a mão na massa muito dos problemas já foi pensado e analisado naqueles momentos de divagação no banheiro, no ônibus, ou na sala de aula. Os momentos mais frutíferos, aliás.
Porém, é claro que catalogar tudo também não é tudo. É preciso agir. Por esse motivo costumo dividir minhas tarefas em duas listas (fora a da empresa onde trabalho): Curto Prazo e Longo Prazo. As tarefas no curto prazo são as mais imediatas, e representam as coisas que devo fazer antes da semana, do mês ou do ano acabar. Geralmente dou uma olhada diária nessa lista. As de longo prazo não são menos importantes, mas possuem um tempo de finalização mais longo, ou porque não são interessantes atualmente, ou porque fazem parte do meu projeto de vida, algo que se deve pensar mais e agir aos poucos. Costumo dar uma olhada semanal nessa lista.
Enfim, cada pessoa tem sua maneira de encarar problemas, catalogar idéias e fazer acontecer. Essa ferramenta, na minha opinião, pode ajudar.
# Hook de API no WinDbg
Caloni, 2007-08-29 <computer> [up] [copy]Basicamente existem duas maneiras de um executável obter o endereço de uma função API do Windows: ou ele usa uma lib de interface com a DLL (o chamado "link estático") ou ele chama a função GetProcAddress explicitamente (1).
Para conseguir saber as funções das quais um executável obtém o endereço através da primeira técnica podemos utilizar o mundialmente famoso Dependency Walker. Ele nos mostrará quais DLLs ele utiliza e quais funções por DLL ele quer o endereço. Ele também nos avisa sobre as DLLs que estão utilizando delay load, uma técnica inventada no Visual Studio para que os executáveis não dependam estaticamente de APIs muito novas que podem não existir em versões do Windows mais antigas. Com o (carinhosamente chamado) Depends também é possível fazer hook de chamadas de API utilizando a opção profiling (F7), mas não costuma funcionar muito bem com trojans, pois eles capotam antes que alguma coisa interessante ocorra.
O importante do Dependency Walker para o WinDbg é que com um editor é possível copiar todas as funções exibidas em sua interface para um editor, usar um pouco de regular expressions e criar uma batelada de breakpoints:
... bp user32!GetDC ".echo GetDC; g" bp user32!GetDesktopWindow ".echo GetDesktopWindow; g" bp user32!GetDlgCtrlID ".echo GetDlgCtrlID; g" bp user32!GetDlgItem ".echo GetDlgItem; g" bp user32!GetDlgItemTextW ".echo GetDlgItemTextW; g" bp user32!GetFocus ".echo GetFocus; g" ...
O comando "bp" cria um breakpoint no endereço requisitado. O que está entre aspas são os comandos que você deseja executar quando o breakpoint for disparado. No caso, para todas as funções será impresso o seu nome (comando ".echo") e a execução irá continuar (comando "g"). Ao rodar o programa, as chamadas das funções são mostradas na saída do depurador:
... GetDesktopWindow GetDC GetFocus GetDlgItem GetDC GetDlgItem GetDC GetDlgItem GetDC GetDlgItemTextW ...
Lindo, não? Porém ainda podem estar sendo chamadas as funções obtidas pela segunda técnica, a do GetProcAddress. Para esse caso devemos ir um pouquinho mais fundo e rodar o executável duas vezes. Na primeira, coletamos as funções que são obtidas por essa técnica através do seguinte comando:
bp kernel32!GetProcAddress "da poi(esp + 8); g"
O comando "da" exibe o conteúdo de uma string em C (caracteres ANSI e terminada em zero) na memória. A memória no caso é o "apontado do valor contido no segundo parâmetro da pilha". Complicado? Nem tanto: lembre-se que o ESP aponta sempre pro endereço de retorno da função chamadora e os parâmetros são sempre empilhados na ordem inversa da declaração em C. Logo, se o protótipo de GetProcAddress é:
FARPROC GetProcAddress(HMODULE hModule, LPCSTR lpProcName);
O último parâmetro empilhado (ESP+4) é o hModule, e o penúltimo (ESP+8) é o lpProcName, que é o lugar onde é passado o nome da função.
Devemos lembrar de colocar esse breakpoint bem no início da execução e rodar o executável uma vez. Com isso coletamos o conjunto de nomes de funções usadas para chamar GetProcAddress:
... 746e29f8 "ImmReleaseContext" 746e2a30 "ImmNotifyIME" 746e2934 "CtfImmEnterCoInitCountSkipMode" 746e2978 "CtfImmLeaveCoInitCountSkipMode" 746e29bc "ImmGetDefaultIMEWnd" 746e2a64 "ImmSetConversionStatus" 746e2aa0 "ImmGetConversionStatus" 746e2adc "ImmGetProperty" 746e2b10 "ImmGetOpenStatus" ...
Daí é só organizar a lista obtida em ordem alfabética, acabar com duplicidades e criar o mesmo tipo de breakpoint que foi usado para as funções estáticas (pode ser sem o nome da DLL porque, embora não recomendado, o WinDbg se vira para encontrar os símbolos). Depois de criados os comandos, rodamos novamente o executável e, logo no início, já colocamos todos os breakpoints das funções coletadas.
Essa é uma maneira rústica, porém eficaz e rápida de obter a lista de execução da API utilizada por um programa (2).
(1) Uma variação do método GetProcAddress é a técnica de delay load usado pelo Visual C++. Porém, como o Dependency Walker nos mostra também as DLLs que estão linkadas usando essa técnica se torna dispensável um tratamento ad hoc.
(2) Essa técnica nem sempre funciona com todas as chamadas API, pois o aplicativo ainda pode utilizar outras maneiras de obter o endereço de uma função e chamá-la. A solução definitiva seria escrever diretamente um assembly esperto no começo da função, o que pode gerar mais problemas que soluções. Do jeito que está, conseguimos resolver 90% dos nossos problemas com análise de chamadas API. O resto nós podemos resolver em futuros artigos.
# Barata Elétrica e o hacker de antigamente
Caloni, 2007-08-31 <essays> [up] [copy]Os artigos escritos por ele estavam em português, mas sempre em suas edições ele disponibilizava artigos de outras partes do mundo em inglês. Praticamente li todos eles, e muitos fiz questão de ler mais de uma vez. A maioria falava de um mundo que existia antes de eu ter um computador, onde existiam vírus e pirataria de programas em disquetes, BBSs e a tal reserva de mercado. Além, é claro, de dicas de como ser um nerd e não perder a sociabilidade (se é que isso é possível quando se é um nerd adolescente). Existe uma página no zine onde estão listados os melhores artigos de todos os tempos da revista.
Além do Barata Elétrica existiam outras revistas internacionais "bem conceituadas" na época, como a CCC (Chaos Computer Club), uma comunidade de hackers e crackers (o início do Astalavista!) fundada na Alemanha, e a 2600 Quarterly, constantemente perseguida pela polícia dos Estados Unidos depois das aprontadas de Kevin Mitnick, um praticante de engenharia social famoso da época. Como ainda eu ainda engatinhava no inglês, tive que me virar com o que tinha, um dicionário na mão e muita vontade de aprender. Não entendia muito, é verdade, mas minha atitude fez com que o inglês aprendido me valesse até hoje.
Naquela época, além de computadores, programação, muito café e coca-cola, meus interesses estavam bem mais voltados em entender como a sociedade progrediria diante dessa revolução tecnológica que estava acontecendo naquele momento. Como ficariam nossos direitos civis dentro da rede? Quem seria julgado por um crime digital e, talvez mais importante, quem seria o executor desse julgamento? O que seria direito digital? Como fica nossa privacidade? Todas essas questões me levaram a ler livros que recomendo fortemente, como 1984, Revolução dos Bichos e Admirável Mundo Novo. Todos falam de sociedades fictícias, mas cujas características estão muito mais presentes entre nós do que os estereótipos das novelas televisivas. Eles não falam muito sobre computadores nem programação, mas são muito bons para a formação crítica de um indivíduo sobre a sociedade em que ele vive.
Enfim, acho que já deu pra perceber que esse artigo não é sobre C++, Windows, Engenharia Reversa ou computadores. É muito mais um lapso nostálgico que me ocorreu sobre o que era ser um hacker naquela época: ansiar avidamente por conhecimento, mas não um conhecimento qualquer, que termina nele mesmo, regurgitado junto das milhares de notícias diárias. É um conhecimento sadio, apreciado e mastigado lentamente, com consciência, com perseverança. Não havia aquele desânimo por falta de tempo em aprender todas as coisas, mas o contrário: o ânimo por existir mais e mais conhecimento a ser apreciado, discutido e refletido. A troca de informações entre as pessoas era muito importante. O adjetivo hacker da época não estava na capacidade em invadir sistemas, mas em sua atitude em aprender coisas novas, ampliar sua visão do mundo e ter humildade o suficiente para concluir que nessa vida só se aprende um grão de areia de uma praia gigantesca. Bons tempos em que não saber não era vergonha de nada, mas uma oportunidade a mais.
O tempo passa, o mundo gira, e aqui estamos nós: orkut, msn, youtube, blogues, flogues e outros gues inventados a cada dia. As pessoas estão conectadas, e cada vez mais estarão. E para quê? Para trocar mensagens, emoticons, fotos, vídeos, informação. Sobre elas mesmas, sobre onde vivem, sobre onde moram. A tal da privacidade foi por água abaixo. Poucos possuem o discernimento do que podem e não podem fazer sem sofrer as conseqüências de ter sua vida inteira exposta através dos bits e bytes que nunca param de trafegar. A popularidade da rede transformou-a em um second life, literalmente. Para alguns, é até o first life mesmo. Isso é a escolha de cada um.
[2007-07] [2007-09]